




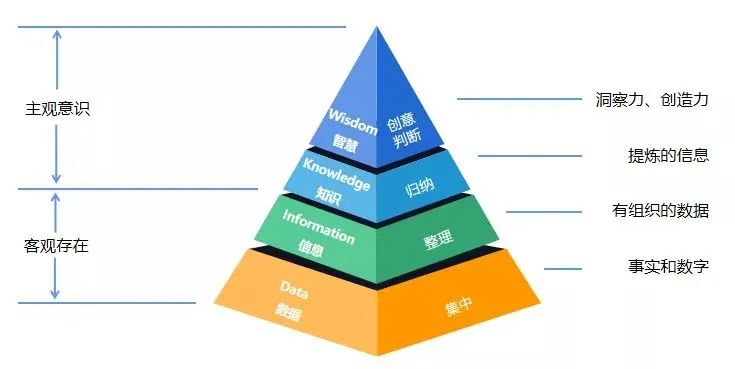
Rowley在2007年提出DIKW体系,从数据、信息、知识到智慧,是一个不断凝炼的过程。拥有了知识不代表拥有智慧,将知识转成智慧需要“转识成智”,对于AI来说,知识图谱是一个非常好用的工具。

知识图谱的价值归根结底是为了让AI变得更智慧。谷歌高级副总裁一语道破知识图谱的重要意义所在:“构成这个世界的是实体,而非字符串”。
底层图谱就像一张非常“聪明的网”,它涵盖了所有领域知识,并且记录下知识与知识之间的联系。人们通过知识图谱能够很轻易获取相关的学习内容,大大增加了学习的深度和广度。根据领域大数据及所有用户数据,归纳出领域图谱;同样的技术还可以用于打造个人图谱,将个人兴趣、行业、学习程度进行图谱化管理;根据领域图谱所呈现的大趋势,以及个人图谱显示的学习程度,就可量身定做智能化的学习路径,使得人们更容易达成学习目标。
当利用知识图谱聚合起大量知识之后,如何能够让人们触达知识、主动获取知识呢?搜索技术在其中起到了关键的作用。而且,基于知识图谱的搜索,除了能够直接回答用户的问题外,还具有一定的语义推理能力,大大提高了搜索的精确度。人们可以随时搜索到相关的知识内容,甚至是那些隐形的、碎片化的知识也可以通过底层的AI技术被链接、被激活。同时也能够更有效地催生优质内容的不断增加。
知识图谱是什么?
知识图谱,从字面上看,就是用图的形式将知识表现出来。知识图谱是用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱有两个技术基因,一个是知识视角,来源于传统AI的知识表示与推理领域,它使得知识图谱具备AI基因;一个是图的视角,关心图中的节点、边、链接、路径、子图结构,怎样利用图的结构进行推理、挖掘和分析,它使得知识图谱具备互联网基因。
从数据角度看,它是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体-属性-关系”,构成网状的知识结构,在金融领域是融合碎片化的信息,挖掘隐藏的关联关系和传递影响,辅助智能决策。
从技术角度说,它是一套工程技术,包括知识抽取、知识表示、知识存储、知识推理和知识检索等一系列技术。通过知识图谱技术,能将知识库中所有信息进行整合和联系,形成底层图谱。
谷歌最早提出知识图谱的概念,2012年5月,谷歌在搜索页面中首次引入“知识图谱”,用户除了得到搜索网页链接外,还将看到与查询词有关的更加智能化的答案,但它并非突然出现的全新概念,而是经历了不短的历史沿革。
下面用一张图表示知识图谱的演化历程:
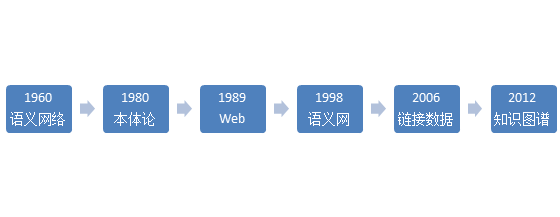
知识图谱的最早前身是作为自然语言语义知识表示工具的“语义网络(semantic networks)”。早期的语义网络只存在于论文里,后来悄悄进入工程。
随着人们对自然语言语义认识的深入,以及语言资源建设的扎实推进,自然语言语义知识表示进入了“本体(Ontology)”阶段。本体这个概念在哲学层面上是形而上的,是只可意会不可言传的,因为所有的描述都成为了“本体”的外在符号,我们世界上的所有图像、语言、我们看到的、听到的、感受到的,都成为符号到本体的某种映射。本体就是那个实相,亚里士多德口中的“实体”,巴门尼德眼里的“存在”。
哲学层面上所有的符号到本体存在映射,语义层面就很好理解,我们的主要目的就是要建立这样一种映射,举个简单的例子,我们希望把{“BUAA”,"Beihang", "Beihang University","北航","北京航空航天大学"}这个符号集都映射到“北京航空航天大学”这个“本体”上来。再深一层,建立了本体的集合,就可以去发掘本体间深层的关系。描述语义层面的本体关系的语言就是RDF和OWL等。建立好本体间的关系之后,就可以进行语义层面上的推理,推理的结果可以映射回语言层面,形成新的组合。
本体这一概念不仅在自然语言语义表示领域,也在知识工程和信息检索等领域有所推进。除了领域无关的语言学知识本体,也有大量领域相关的本体问世。本体作为领域共享的知识组织框架,在许多行业都有推进的尝试,但由于缺乏共同标准和顶层设计,这方面工作进展并不理想。
而真正对知识图谱产生深远影响的是Web的诞生。Tim Berners Lee在1989年提出了Web的愿景,Web应该是一个以“链接”为中心的信息系统,以图的方式相互关联。
1994年,在第一届国际万维网大会上,Tim又指出,们搜索的并不是页面,而是数据或事物本身,由于机器无法有效地从网页中识别语义信息,因此仅仅建立Web页面之间的链接是不够的,还应该构建对象、概念、事物或数据之间的链接。
1998年,Tim正式提出语义网(Semantic Web)的概念。语义网是一种数据互连的语义网络,它仍然基于图和链接的组织方式,但图中的结点不再是网页,而是实体。这是一个标志性的转折点,语义网概念的中文翻译和上面提到的语义网络虽然仅仅一字之差,但其内在含义的差别其实非常之大。
通过为全球信息网上的文档添加“元数据”(Meta Data),让计算机能够轻松理解网页中的语义信息,从而使整个互联网成为一个通用的信息交换媒介。我们可以将语义网理解为知识的互联网(Web of Knowledge)或者事物的互联网(Web of Thing)。
2006年,Tim又提出了链接数据(Linked Data)的概念,进一步强调了数据之间的链接,而不仅仅是文本的数据化。
就这样,基于Tim的高瞻远瞩和务实风格,并通过W3C组织扎实推进工作,一整套技术体系逐渐成形。
等到谷歌提出“知识图谱”概念时,这套技术体系实际上已非常成熟。虽然基于知识图谱的搜索服务还有待进一步建设,但知识图谱本身一定程度上已经可以脱离依附于信息资源的“标签体系”的从属地位,独立发展了。
如何构建知识图谱?
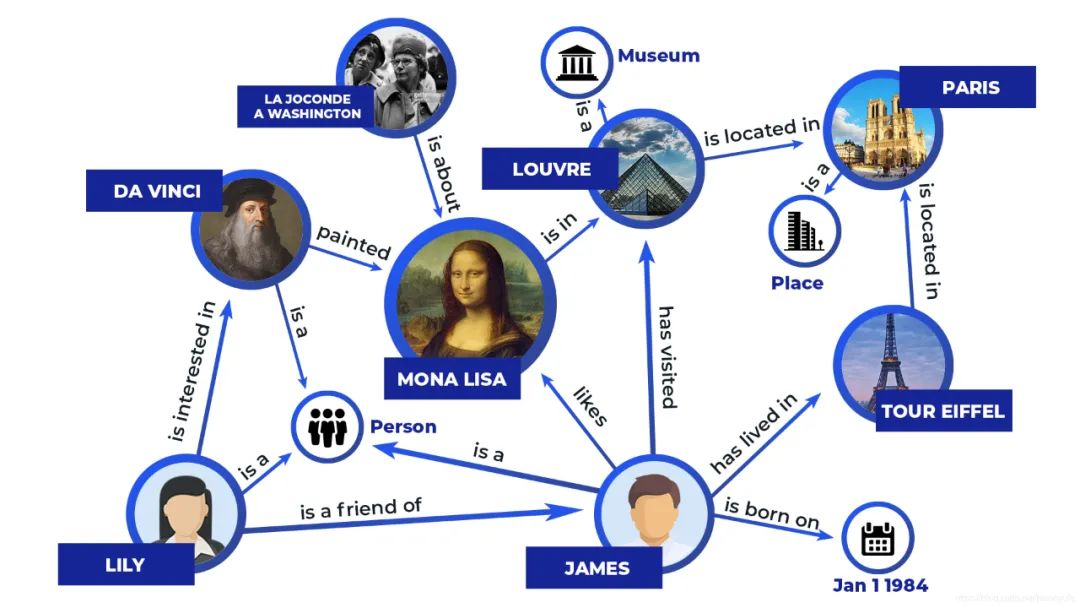
一是获取数据。维基百科、百度百科等这些结构化的知识可以高效地转化到知识图谱中;W3C的开放互联数据项目(Linked Open Data,LOD)以RDF(Resource Description Framework)形式在Web上发布各种开放数据集,还允许在不同来源的数据项之间设置RDF链接,实现语义Web知识库;互联网的海量网页中的杂乱知识可通过自动化技术抽取出来构建知识图谱。
二是表示知识。知识图谱就是基于有向标记图的知识表示方法。最常用的知识图谱表示方法有属性图和RDF图两种,以RDF图为例,知识图谱的最基本组成单位是三元组,包含(主语,谓语,宾语),这是最简单且接近于自然语言的数据模型,多个三元组头尾链接形成一张描述事物之间关系的图谱。基于网络的表示方案往往需要图算法来实现,可进一步改进,将知识图谱中的实体和关系的语义信息用低维向量表示,这种分布式表示方案能够极大地帮助基于网络的表示方案。
三是融合知识。知识图谱的数据来源包括了文本、DOM Trees、HTML表格、RDF语义数据等多个来源,能更有效的判定抽取知识的可信性。知识融合主要包括实体融合、关系融合和实例融合三类,同一个实体在不同语言、不同国家和地区往往有不同命名,而同一个名字在不同语境下可能会对应不同实体,在这样复杂的多对多对应关系中,如何实现实体融合是非常复杂而重要的课题;再就是关系融合;在实现了实体融合和关系融合之后,就可以实现三元组实例的融合。不同数据源会抽取出相同的三元组,并给出不同的评分。根据这些评分,以及不同数据源的可信度,就可以实现三元组实例的融合与抽取。
如何使用知识图谱?

知识图谱大显身手的主战场是知识推理。推理是知识图谱的核心技术和任务,推理往往需要相关规则的支持,这些规则可以通过人们手动总结构建,自动挖掘相关推理规则或模式,主要依赖关系之间的同现情况,利用关联挖掘技术来自动发现推理规则。
知识推理可以用于发现实体间新的关系。利用推理规则实现关系抽取的经典方法是Path Ranking Algorithm,将每种不同的关系路径作为一维特征,通过在知识图谱中统计大量的关系路径构建关系分类的特征向量,建立关系分类器进行关系抽取,取得不错的抽取效果,但这种基于关系的同现统计的方法,面临严重的数据稀疏问题。知识推理方面还有很多探索,例如采用谓词逻辑等形式化方法和马尔科夫逻辑网络。
写在最后
知识推理通过海、陆、空三大军团并行作战:
图推理是“海军”,亿万级“当量”的知识图谱是知识的大海。
神经网络推理是“空军”,一层又一层的深度神经网络高入云霄,通向知识的天空。
规则推理则是 “陆军”,看上去朴实无华,一步一个脚印,实际推理中却始终离不开它。
最终,形成一张聪明的网,帮助我们转识成智。
