




在TPCC与透明分布式中我们提到过,对于分布式数据库,透明的核心在于全局索引,全局索引的关键在于分布式事务的性能。PolarDB-X等众多分布式数据库对分布式事务的性能做了各种优化,使得它能够满足全局索引的维护需求。
那么问题来了,透明是不是所有场景(特别是对性能要求高、资源投入最多的场景)的最优解,手动分区是否也存在价值。
首先,我们需要先看一下,分布式事务相对于单机事务,处于一种什么样的水平。
分布式事务与单机事务
分布式事务,一个研究了几十年的领域。
诚然,在一些benchmark下,有很多分布式事务方案可以做到很不错的性能与功能,但是很遗憾,在通用场景下(说白了就是不对业务做特殊优化,无论是对事务的使用方法上还是业务模型之类的),分布式事务跟单机事务相比,在成本(或者说性能)上依然存在不可逾越的鸿沟。
我们做过一些测试,这个差距至少在3倍以上。这个3倍综合了很多指标,而且做的是同一个产品自身的对比,意思是A数据库的单机事务性能与A数据库的分布式事务性能,当然,这个前提是A数据库有单机事务的优化。无论是大多数人觉着很NB的Google Spanner,还是后起之秀TiDB、CockroachDB等,亦或是同门兄弟OceanBase,当然,也包括我们PolarDB-X自己,在实际的测试中,都能够看到这个差距(差距在3倍的已经是最好的了,有的甚至在七八倍以上)。
以后有机会会单独写一篇文章介绍一下这个测试,这里先不做展开了。
这个结果其实是非常符合直觉的。很多人都嘲笑过某某CPU厂商的产品,称之为“胶水CPU”;也有很多人知道,NUMA架构下,要对进程做好绑核(十年后数据库还是不敢拥抱NUMA?)。因为性能而已。
即使Intel在只有两个NUMA的情况下,跨NUMA的性能差异也有2倍
跨核、跨CPU造成的RT升高等代价,已经能让人感知到明显的性能差异了,更何况“总线变网线”的分布式事务呢。分布式事务,一定需要更多的成本。数据库嘛,一个典型的成本中心,指望数据库直接赚钱是不太可能的,省钱就是最重要的了。
因此,我们能看到一个有点奇怪的现象,对于一个高并发的交易系统来说,优化良好的分库分表中间件+单机数据库一定是它性能的天花板。因为它逼着业务一定要干掉分布式事务,将所有的操作都优化成单机事务。当然,它用起来肯定是不方便的。
那么问题来了,分布式数据库,能否在提升易用性、降低了使用成本的前提下,去接近这个性能的天花板呢?
想要接近这个天花板,就要求分布式数据库有能力消除分布式事务。
我们先介绍一个工具——表组。
表组(Table Group)
表组是单机MySQL中没有的概念。
作为一个以兼容单机MySQL为己任的分布式数据库,引入一个新的概念代表着额外的学习成本,但即便如此,我们还是坚持在PolarDB-X中引入了这个概念。为什么呢,我们先了解一下,它是用来解决什么问题的。
考虑以下场景:
有两张表,订单表(orders)与订单详情表(order_details),如果一个订单包含了10个商品,那就会向orders表里插入一条记录,再向order_details表中写入10条记录。对于大多数电商系统,订单的核心查询维度是买家,所以两张表都以买家ID(buyer_id)作为分区键,如下:
create table orders(
order_id bigint auto_increment primary key,
buyer_id bigint,
...
) partition by hash(buyer_id);
create table order_details(
order_detail_id bigint auto_increment primary key,
order_id bigint,
buyer_id bigint,
...
) partition by hash(buyer_id);对于一个下单操作,就是如下的一个事务(假设buyer_id=88):
begin;
insert into orders (order_id,buyer_id, ...) values (null,88, ... );
select last_insert_id(); ##获取生成的订单id
insert into order_details (order_detail_id, order_id, buyer_id, ...) values (null, ${order_id}, 88, ...);
insert into order_details (order_detail_id, order_id, buyer_id, ...) values (null, ${order_id}, 88, ...);
insert into order_details (order_detail_id, order_id, buyer_id, ...) values (null, ${order_id}, 88, ...);
...
commit;如果这两个表的分区是这样分布,那无论如何也会是一个分布式事务:
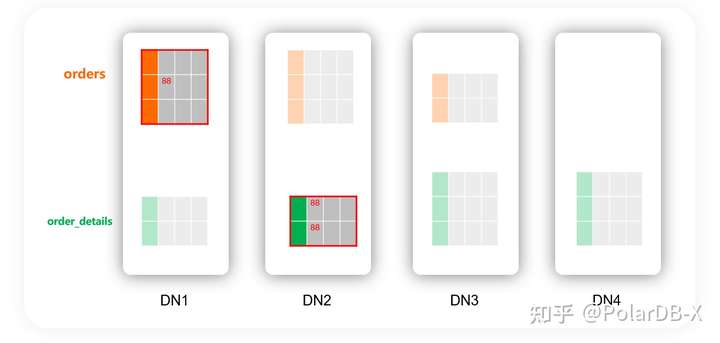
在性能天花板方案中(分库分表中间件+单机数据库),88这个buyer_id所在的orders的分表与order_details的分表一定会放到同一个分库中,从而将这个事务做成一个单机的事务。
同时,我们希望,这个事务永远都是单机事务。这就意味着:
- 同样的buyer_id的orders与order_details一定在同一个节点上,而不是当某些buyer_id巧合在一个节点上才优化为单机事务。
- 测试环境它是单机事务,线上环境也得是单机事务;今天是单机事务,明天做了一些操作(例如扩容、rebalance等)之后,它也是单机事务。这样才能保证性能的一致性。
因此,我们需要将这两个表绑定起来。这意味着,这两个表的分区算法、分区数、分区的划分要时时刻刻是一样的,同时,包含相同buyer_id的分区,要时时刻刻调度在同一台机器上。
这个绑定关系,就称之为表组:
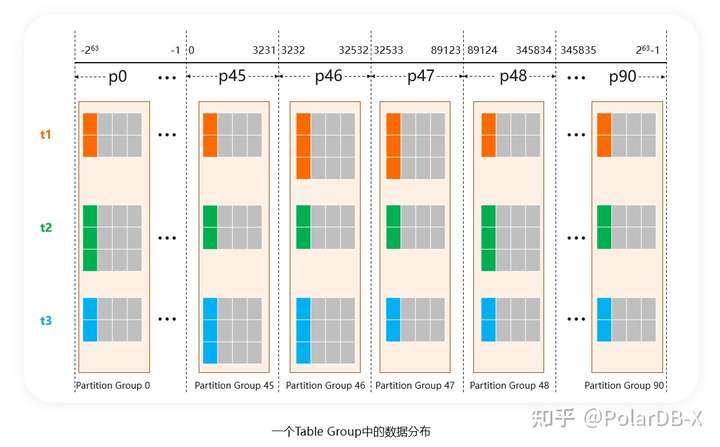
一个分布式数据库,只有具备了表组(当然它也可以叫其他名字,例如在Spanner中,使用的是“交错表”这个概念实现了类似的效果),才具备消除分布式事务的能力。例如,TiDB、CockroachDB中没有这种能力,所以它们所有的事务都是分布式事务,即使你愿意设计合理的分区键,也无法让数据路由在一起。
题外话,仔细观察会发现,目前市面上开源的SQL+分布式KV这种架构的数据库,没有一个产品能提供这样的能力。它们看似结构清晰、分层明确,但进入性能的深水区后,能提供的优化手段就特别少。讨“数据库研发者”的喜欢未必能讨“数据库使用者”的喜欢。
PolarDB-X以表组为基础,提供了一系列的能力,让应用享受到分布式数据库带来的便利的同时,也能具备接近中间件方案的性能。
表组与JOIN的下推
表组除了为消除分布式事务提供了手段之外,还有另外一个附加的好处,可以做JOIN的下推。
考虑以下SQL:
select *
from orders join order_details
on orders.order_id=order_details.order_id and
orders.buyer_id=order_details.buyer_id
where orders.order_id=xxx and
orders.buyer_id=xxx业务意义是根据订单ID,查出这个订单的所有信息,也包括订单的商品列表信息。
由于JOIN的条件要求两个表的分区键(buyer_id)相等,如果orders与order_details在同一个表组中,那么JOIN实际上只会发生在同一个分区组内(表组内编号相同的或者说对齐的分区称为一个分区组)。而分区组一定在同一台DN上,那代表这个JOIN操作可以由DN来完成。这就是JOIN的下推。
由于避免将数据传输到CN,毫无疑问,对于同样的JOIN语句,下推的执行策略一定优于不下推的执行策略。
同时,PoalrDB-X的DN源于MySQL,天生具备了很强的计算能力(包括事务、表达式计算、Filter、JOIN等等),表组使得更多的SQL能将计算下推到DN上,进一步的接近了性能的天花板。
表组的自动调度
有了表组的概念之后,又有一个新的问题。
以上面的orders表与order_details表为例,当建表语句中未指定表组的时候,是否将它们划分到同一个表组中;换句话说,假如一个用户在不了解表组的情况下,分布式数据库能否符合直觉的、自动的避免下单操作中的分布式事务。
对应两种路线:
- 如果一个表,用户没有显式的指定表组,它就不属于任何一个表组
- 如果两个或者多个表的分区算法、分区数等一致,则自动调度到一个表组中
例如,OceanBase使用的是方案1。也就是说,在orders与order_details的例子中,虽然都是同一个buyer_id=88,但这个事务依然会是一个分布式事务。除非手动给orders与order_details创建一个表组。
PolarDB-X的设计理念认为,方案1会提高使用门槛。用户必须理解并知道表组的概念,而且还得给每个表设计表组,才能很好的消除分布式事务,它的下限不够高,或者说,不够透明。我们认为表组应该是一个可选的优化项,而不是必须理解的门槛。
因此,PolarDB-X选择的是方案2,会自动的去识别、并尽可能的将多个表划分到一个表组中。
在上面的例子中,即使用户不知道表组的概念,建表的时候没有指定表组,PolarDB-X依然会将orders与order_details划分到一个表组中,从而消除掉下单操作中的分布式事务。对业务上同一个用户的数据的操作是一个单机事务,这个行为也更符合直觉。
表组的代价
表组是有一定代价的,主要体现在负载均衡上。
很容易理解,数据库的负载均衡主要依赖对数据分片进行分裂、合并、移动等操作。重复一下,表组需要保证性能的一致性,也就是说,在对数据分片进行分裂、合并、移动等操作过程中,同一个表组内的表也要保持分片上的对齐。为了达到这一个效果,这些操作必须同时对同一个表组内的所有表同时进行:
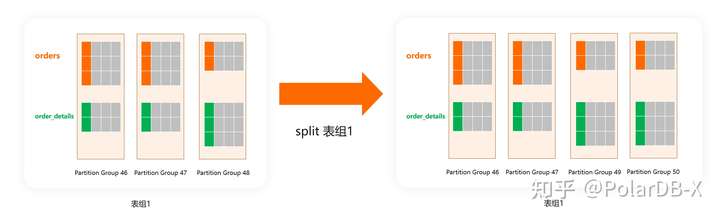
因此相对于不提供表组能力的数据库,表组会使得负载均衡时操作的数据粒度变大(更不容易达到完全负载均衡的状态)。
同时,对于数据库内核的研发者来说,这也会使得负载均衡算法的复杂度大大提高。
题外话,其实这里也可以理解为何一些内核爱好者会更推崇基于分布式KV的数据库,因为约束少、结构简单,想验证自己的一些想法更容易出成果。
例如,如果想在一个不提供表组能力的基于分布式KV的数据库上做一个负载均衡算法,你完全不需要考虑表之间的联系,对每个表你可以自由的做各种分裂、迁移之类的操作,问题会简化很多。但相应的代价就是,这种数据库完全不具备消除分布式事务的能力,对于最终买单的人来说,这意味着要花更多的钱。
对于表组带来的代价,PolarDB-X认为这是一个可优化的选项,但很多时候不是必须的。特别是在应用开发的初期阶段,我们认为开发人员应该将精力更多的放在业务逻辑上,而不是表组的设计上。
这里与之前文章提到过的PolarDB-X的另一个设计理念又是契合的,“Hash适合预分片,系统会更具确定性;PolarDB-X从设计理念上更关注稳定性与确定性”。由于Hash+预分片的使用,PolarDB-X的用户并不需要很快面临负载均衡的问题,可以将表组的设计问题延后甚至弱化。
PolarDB-X希望用户在上线之后,如果存在负载不均等热点问题,再去对这部分表的表组进行调整。
流程上应该是这样的: 1. 建表时,同样分区算法、分区数的表会自动分配到同一个表组中:
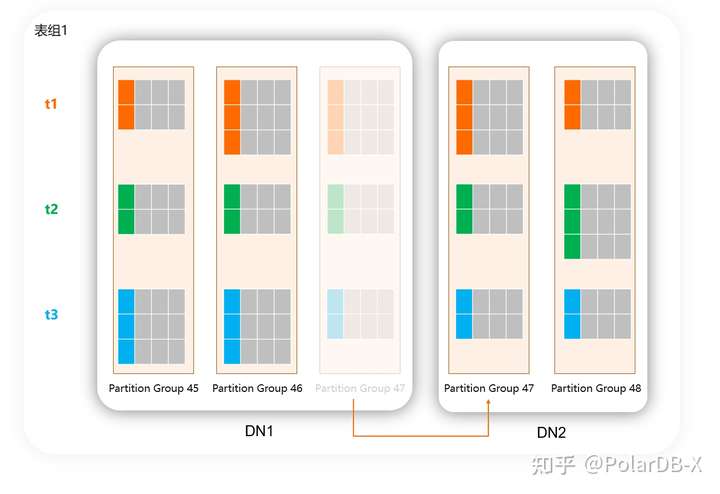
- 当性能测试或者上线后发现默认的分配策略存在热点等问题,创建新的表组,将一些不会出现在同一个事务内或者不需要做JOIN的表挪到其他表组中,缩小每个表组的大小:
CREATE TABLEGROUP TG2;
ALTER TABLE t3 SET TABLEGROUP=TG2;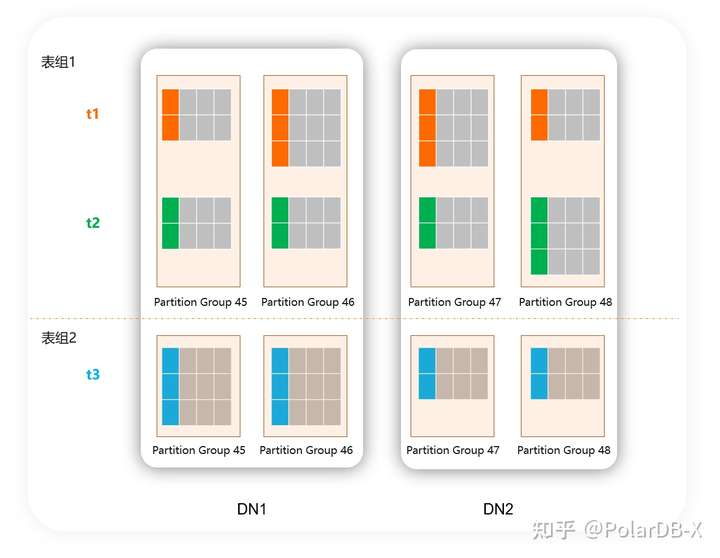
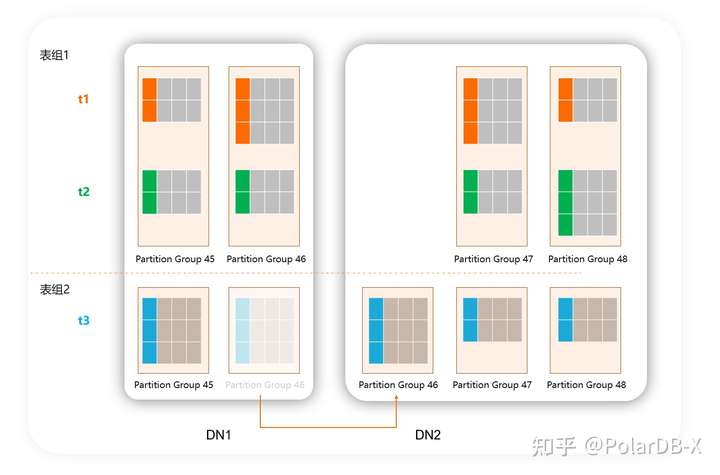
这里有一个很关键的点,这种调整会只需要修改元数据,并不需要搬迁数据,代价极低。因为将一个表挪到一个新的表组,并不需要理解改变它的数据分布。
- 当下次rebalance等操作的时候,开始以新的表组为单位进行:
Local Index
Local Index,顾名思义,只索引每个分片内部的数据。你得先通过其他一些方法定位到分片,才能使用到Local Index。
这里有疑问了,我们都已经有了Global Index,它里面索引了所有的分片的数据,为什么还需要一个听起来更弱的Local Index呢。
这里我们看重的并不是“只索引分片内的数据”,而是看重Local Index中的记录是可以做到和主表的记录在同一个分片上,从而让索引的维护也变成一个单机事务。也就是说,如果单纯为了Local Index而实现Local Index,却做不到单机事务,那是没啥意义的。
在性能优先场景中,由于有分区键的存在,大多数二级索引都只需要Local Index,例如orders表上会有其它一些属性(订单状态、订单类型之类的东西),这些字段只需要Local Index即可,而不需要会产生分布式事务的Gloabl Index。
Local Index的使用,对接近性能天花板是非常重要的一件事情。PolarDB-X使用MySQL作为DN,天生就具备Local Index的能力。
话说,对同一个数据库,测试其Local Index与Global Index的能力,实际上可以很好的体现单机事务与分布式事务的差距
当然,Local Index的“样子”也有很多,别局限于语法。关键看,索引的维护能否使用单机事务。举几个例子:
- TiDB中有partition语法,partition上创建的索引也是一个Local Index,但这个索引与主表并没有位置上的绑定关系,并且也会跨多个range,所以它依然要使用分布式事务来维护。
- Spanner中有个叫interleaved index的概念,大致上能起到单机事务维护的Local Index的作用: > If the index key that you want to use for index operations matches the key of a table, you might want to interleave the index in that table if the row in the table should have a data locality relationship with the corresponding indexed rows.
自动决定下限,手动决定上限
最后回归到我们的题目,透明 vs 手动。
按透明与手动来划分市面上常见的分布式数据库:
- 透明的分布式数据库的典型代表:TiDB、CockroachDB。
- 手动的分布式数据库典型代表:OceanBase、YugabyteDB。
现在我们可以回答,是否透明的分布式数据一定比手动的要好呢?
对于只提供透明用法的数据库,迁移成本会比较低,初步体验会比较好。但进入深水区后,由于不可避免的会大量的使用分布式事务,在核心场景中,性能往往是达不到要求的(或者同样的性能需要更高的成本),并且缺少消除分布式事务、更充分的计算下推等优化手段。
对于只提供手动用法的数据库,虽然设计良好的分区键使得理论上能够做到性能最优,但使用门槛会大幅增加(10%核心表设计分区键也就算了,剩下的90%非核心表也要设计分区键)。
我们认为,无论是纯透明还是纯手动的分布式数据库,都无法很好的满足业务对使用成本和性能兼顾的要求。
PolarDB-X除了提供了透明模式,也完整的支持了分区表的语法,并提供了Table Group、Local Index、JOIN下推等工具,让应用在需要极致性能的情况下,能将事务、计算更多的下推到存储节点。
PolarDB-X是市面上唯一能够做到同时提供透明与手动两种模式的分布式数据库,我们推荐大多场景使用透明模式,之后对核心业务场景进行压测,并使用分区表语法对这些场景做手动的优化,以达到最高的性能。
下一篇
PolarDB-X的表组的分配策略是比较复杂的,但在设计上的一些取舍又是很有趣味的。同时,我们还有做了很多工作来进一步提升表组的易用性。下一篇文章中,我们将详细介绍关于表组的方方面面,欢迎大家持续关注我们。
文章来源:阿里云数据库
