




概述
分布式数据库的核心目标之一是为用户提供类似单机数据库的使用体验,PolarDB-X 作为一款兼容 MySQL 生态的云原生分布式数据库,在数据导入方面也为用户提供了类似单机 MySQL 数据库的多种导入工具和系统以应对不同场景,本文将介绍不同场景下 PolarDB-X 是如何处理数据导入的。
文件导入
这种方式通常为初始化数据库时使用,特点是数据量大,导入程序与数据文件通常在同一台机器上。PolarDB-X 提供了 Batch Tool 处理此类型数据导入。
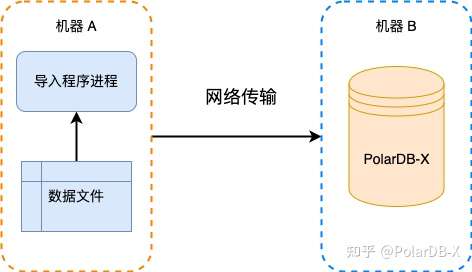
我们简要分析一下这个场景会发现
- 从本地读取数据文件数据的速度通常会远大于导入目标数据库的速度
- 我们的目标数据库 PolarDB-X 为分布式数据库,具有数据分片的特性
读取和写入的速度差提示我们这里适用生产者/消费者模型。我们需要使用一种合适的实现方式最小化程序在 I/O 上的阻塞时间,尽可能达到两侧最大的吞吐量。由于分布式数据库天然具有数据分片的特性,我们会很自然地选择多线程的方式进行数据的并行处理。并发最大的性能杀手是锁等待,因此我们需要尽可能保证每个线程的数据处理过程处于独立的无锁状态。
Batch Tool 基于 Disruptor 框架实现了生产者消费者模型,框架提供的 RingBuffer 使用无锁算法实现,有效契合我们的需求。根据目标端表拓扑分配好线程后,生产者线程以文件系统 Block 整数倍大小为单位顺序读取文件以达到最大读性能,简单处理数据后放入 RingBuffer 中。消费者线程进一步组装数据后导入 PolarDB-X 中。更详细的性能测试可以参考我们此前发布的导入性能测试报告。
在线数据导入
数据系统间的在线数据同步相较于文件的导入应用场景要宽广很多。如 MySQL 主备之间的数据同步,OLTP 数据导入至 OLAP 系统等等。PolarDB-X 近期推出了评估升级功能,帮忙 1.0 版本用户无痛升级至 2.0 版本,我们以此功能为例,分析一下 PolarDB-X 在在线数据导入方面所做的一些工作。在这个场景下,源端为 1.0 数据库实例,目标端为 2.0 数据库实例,逻辑表定义保持一致。评估升级工具从 PolarDB-X 1.0 分布式数据库实例对应的物理库(MySQL)中读取数据,写入 2.0 逻辑库中,由目标库的分布式层计算分片路由并写入底层 DN。因此, 对于单机 MySQL,MySQL 分库分表中间件的数据导入,以下分析同样适用。
与文件数据导入不同的是,在线数据导入由于源端数据系统不停产生新的数据,数据导入并没有一个“完成”时间,我们需要持续同步源端新产生的数据。一个完整的在线同步步骤为:

全量同步基于数据库分片算法切分出每个线程负责的库表后,使用 streaming 的方式从源库读取数据。这里很容易做到每个线程独立负责某一部分库表的同步,因此像我们在前文分析的一样,我们依然基于 Disruptor 的 RingBuffer 实现了生产者消费者模型。有一个需要注意的细节是 streaming 读取实际上是 MySQL 客户端的行为,当同步程序因为各种原因消费阻塞,MySQL 此时会阻塞数据发送到客户端,超过一定时间后 MySQL 会断开连接。这个超时时间由 net_write_timeout控制,默认为 60s,需要提前调整至合适的数值。
选择使用分布式数据的用户数据一般都十分庞大,百 TB 数据的同步需求十分常见。这意味着即使在打满网卡的情况下,全量同步通常耗费的时间也需要以小时为单位计算。而实际情况往往会有更多限制,如源端实例需要为业务提供服务,同步需要限流以防消耗过多资源造成业务抖动,或者较多 GSI 导致写放大,此时目标端写入速度很容易成为瓶颈。
增量同步使用 Canal 伪装成 MySQL 备库进行数据同步。如图 3 所示,由于全量同步耗时较长,如果在这段时间中有持续的业务数据写入,全量同步必然会丢失部分更新数据,因此实践中会将 MySQL binlog 的初始时间点位设置为略早于全量开始时间的某个时间。

根据分布式系统经典的一致性理论,基于 binlog 的朴素的 MySQL 数据复制协议无法达到强一致。虽然基于 Paxos 的 MySQL Group Replication 可以达到强一致,但是应用较少,在此按下不表。为了处理数据冲突,我们可以借助表自身的 pk 或者 uk 进行数据幂等处理。在只关心数据最终一致性的前提下,为了提高增量同步整体的吞吐,我们进行一了系列的优化。除了利用 JDBC 批处理的能力外,在收到一批 MySQL 主库 dump 出的 binlog events 后,以不同事务为单位,我们将不同 update events 进行了 “merge” 操作,按顺序取最新的 update event 作为最终数据版本同步到目标库。现实情况比这个要复杂一些,但是基本的思路是一致的。
当目标库与源库的数据延迟达到秒级时,我们认为两库基本达到了一致状态。此时进入数据校验阶段,从外围保障数据的一致性。我们设计了基于 chunk checksum 的校验算法校验数据一致性。
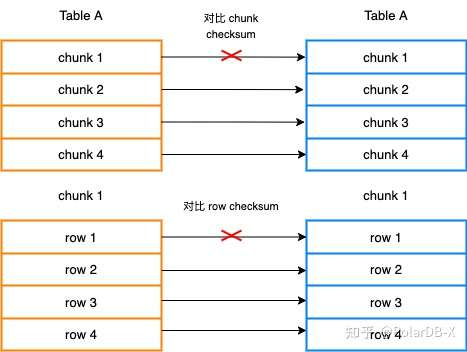
如图 4 所示,大致的思路是首先将 table 切分成不同的 chunk,然后计算源库与目标库同一个表的同一个 chunk 的 checksum 进行比较,这里 checksum 主要使用了 MySQL 的 CRC32() 函数,并在计算时对每个列的数据增加了自定义 salt,判空等手段规避 checksum 冲突。当某 chunk 的 checksum 不一致时,单独计算此 chunk 中每一个 row 的 checksum 进行比较。找到 checksum 不同的 row 后,这些记录会加入到订正数据的队列中,数据订正阶段将会回表重新同步这些数据并以同样的算法进行单独复检。
一般数据导入的故事在校验订正后就结束了,但是在 1.0 升级 2.0 的故事中,为了给用户提供平滑回退 1.0 版本的路径,我们设计了数据回流链路。举个例子,用户在将读写流量从 1.0 实例迁移至 2.0 后,有可能发现 2.0 的某些性能表现与 1.0 有差异,比如某些 SQL 2.0 比 1.0 快,有些慢。为了应付业务需求,有可能需要将流量暂时切回 1.0 实例,这要求 2.0 中新写入的数据实时同步回 1.0 实例中,以免业务流量切换后造成数据丢失。
为了实现数据回流需求,我们需要解决两个问题。
- 数据实时同步回 1.0 实例
- 数据回环问题
针对问题 1,PolarDB-X 的全局 Binlog 可以使我们轻松复用 MySQL binlog 同步的全套逻辑进行数据回流同步。针对问题 2,先简要说明一下什么是数据回环。如图 5 所示,假设表结构为 id, name,其中 id 为主键。如果 insert 了一行数据 (1, 'a'),这一行数据会被同步到目标库中进而产生 binlog,而目标库的回流链路如果无法识别这条数据的来源,会重新将产生的 binlog 事件同步回源库。如果只是简单的 insert 操作,回流时就会出现主键冲突。如果使用了 upsert 或者 replace 操作,就会出现死循环的情况。

数据回环问题在数据同步场景下算是个老生常谈的问题了,比较常见的做法是同步时在源库 update/insert 前后插入自定义事件组成事务作为标志位,这样在回流时可以有效识别标志位进行过滤。这个方案的问题是间接侵入了业务数据流,且很难有效处理大事务场景。为了更优雅地解决这个问题,我们定制了 RDS 的 binlog 格式,在兼容社区 MySQL binlog 格式的基础上增加了逻辑 server id 标志位,这使得我们可以以更细的粒度过滤重复事件,同时避免入侵业务数据流。
Replica
为了更多兼容社区生态,我们实现了大部分常用的 MySQL 主备相关命令,用户可以使用 CHANGE MASTER 命令将 PolarDB-X 实例作为 MySQL 的备库进行数据导入。同样,因为全局 Binlog 的存在,我们可以像单机 MySQL 一样使用 CHANGE MASTER命令将 PolarDB-X 实例作为另一个 PolarDB-X 实例的备库实现增量数据导入功能。更多相关技术细节请关注我们的后续文章。
总结
本文介绍了在不同场景下, PolarDB-X 是如何思考和处理数据导入这一需求的。让用户可以使用熟悉的 MySQL 同步工具对 PolarDB-X 数据进行同步是我们一以贯之的目标。后续会有更多技术细节和思考同大家分享,敬请期待。
参考资料
https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#net_write_timeout
https://dev.mysql.com/doc/refman/8.0/en/group-replication.html
https://dev.mysql.com/doc/inter
文章来源:阿里云数据库社区
