




前言
在之前的文章中我们介绍过了《PolarDB-X on OSS: 冷热数据分离存储》和《PolarDB-X 是如何拯救误删数据的你:备份恢复》。其中之前介绍的备份恢复方案是针对DN MySQL存储的,采取了全量备份加增量binlog备份的策略,恢复流程为:找到最近的全量备份集,执行数据恢复;然后找到从全量备份集开始到恢复时间点之间的所有 binlog 文件,再进行Apply。由于PolarDB-X的冷数据存储方案是基于OSS对象存储的,将整个数据库实例视为一个整体来做备份恢复方案,需要考虑到OSS存储服务的特点。
文本将会详细介绍PolarDB-X在OSS存储上的冷数据如何做备份,以及如何提供任意时间点的恢复能力。
OSS文件版本时间戳
对于每个存储引擎指定为OSS的表,它分为元数据部分和数据文件部分。其中元数据存储在PolarDB-X的GMS元数据节点中,数据文件存储在OSS中,存储于OSS的数据文件格式为开源ORC格式。对于每一个OSS数据文件在对应的GMS元数据记录中都会包含两个时间戳字段commit_ts与remove_ts用于版本控制,与MVCC多版本含义一致。每当一个逻辑操作对应的一批新数据文件生成且提交时,它们会共享同一个TSO时间戳并记录在元数据commit_ts字段中。每当一个逻辑操作对应的一批文件被删除时,它们会共享同一个TSO时间戳并记录在元数据remove_ts字段中。
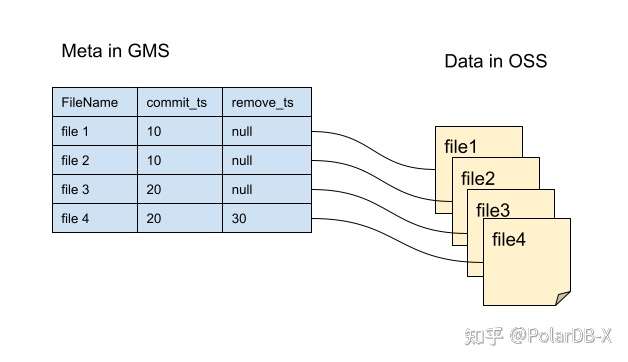
从上面可以看到不同于DN热数据的行级别MVCC版本,OSS冷数据的MVCC版本是文件级别的。同时我们可以了解到删除操作是往对应的文件remove_ts填上删除时刻对应的TSO时间戳。基于时间戳我们可以实现Flashback Query,提供基于任意时间点快照的查询。文件级别的时间戳也是OSS备份恢复的基础。
生成commit_ts时间戳的场景(一般指数据写入OSS成功后):
1. Load模式全量将InnoDB表生成OSS表
2. TTL模式每次将InnoDB表过期归档到OSS表
3. 交换InnoDB表和OSS表分区
生成remove_ts时间戳的场景(一般值删除OSS数据文件成功后)
1. 删除指定OSS表对应的数据文件
2. 删除指定OSS表对应的数据分区,删除数据分区会定位OSS数据文件进行删除
3. Drop OSS表,会级联删除对应的OSS数据文件
4. Drop Database,会级联删除库下的OSS表,和级联删除对应的OSS数据文件
Flashback Query
下面我们以Flashback Query应用为例子,熟悉下commit_ts和remove_ts的作用。Flashback Query指的是用户可以针对SQL中的每张表指定一个时间点,查询相应时间点数据的Snapshot。 当用户查询带有As of Timestamp 'yyyy-MM-dd hh:mm:ss'时,用户指定时间会被转换成TSO时间格式。 转换方式为 物理时间 (the number of milliseconds since January 1, 1970, 00:00:00 GMT) 左移22位得到read_ts。 转换后的时间会与对应的OSS文件的时间戳做可见性判断。
Flashback Query SQL例子:
SELECT XX FROM oss_orders where userId = 100
AS OF TIMESTAMP '2022-07-05 11:11:11'基于commit_ts/remove_ts在可见性的判断逻辑如下:
if (file.commit_ts == null) {
// commit_ts == null 意味着文件还未提交
// skip, 不可见
}
if (read_ts == null) {
// read_ts表示始终读最新版本
// remove_ts != null 说明文件被删除了,不可见
if (file.read_ts != null) {
// skip, 不可见
}
} else {
// visibility : read_ts ∈ [commitTs --- removeTs]
// 只有read_ts落在[commitTs --- removeTs]区间才可见
if (read_ts < file.commit_ts
|| (file.remove_ts != null && read_ts > file.remove_ts)) {
// skip, 不可见
}
}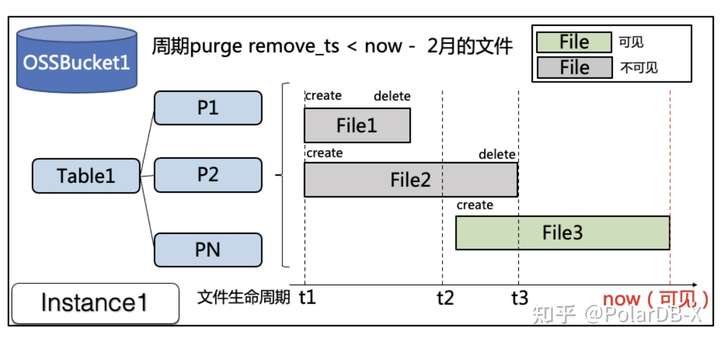
如上图所示,查询的当前时间now,对应的 read_ts > (F1.remove_ts or F2.remove_ts),所以F1、F2数据不可见,而对应的F3文件,只有commit_ts没有remove_ts 且 read_ts > F3.commit_ts,所以F3数据可见
归档存储备份恢复流程
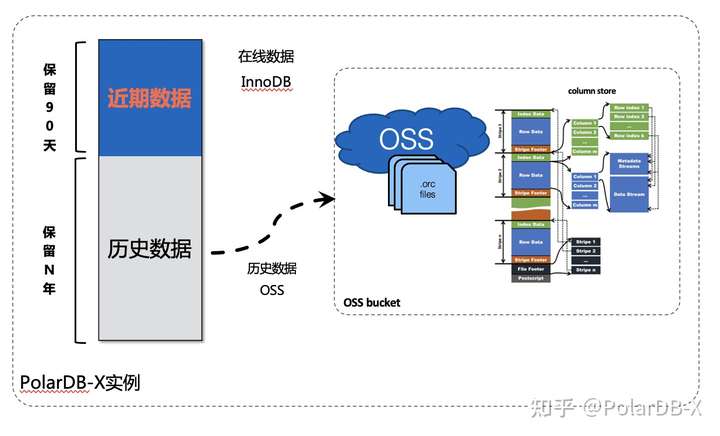
如上图所示,PolarDB-X引入了OSS做冷热数据分离存储后,本文谈的备份恢复是数据库实例级别的备份恢复,实例级备份恢复将DN InnoDB存储引擎的数据和OSS的冷数据视为一个整体,进行统一的恢复,需要支持指定的恢复时间点将原实例恢复到一个目标实例当中。
考虑OSS冷数据的存储规模会比较大,采用和在线库一样高频的备份恢复策略,会带来比较大的备份存储成本,因此在实例级备份恢复任务的设计上,我们把InnoDB和OSS拆分成了相对独立的备份恢复逻辑,既可以一次性备份组合,也可以两者分离各自备份,提供了比较好的灵活性,但两者的备份恢复都得有一些设计约定:
1. 支持定时或者手工触发全量备份的接口,允许实例级备份流程进行全局触发。其中InnoDB的备份恢复流程,设计上也是把全量数据和增量数据的拆分成了两个相对独立的逻辑,具体可参见:《PolarDB-X 是如何拯救误删数据的你:备份恢复》。
2. 支持任意时间点的恢复接口,在实例级恢复流程中会先调用在线数据InnoDB的时间点恢复机制,先确保对应的GMS、DN正常恢复,之后基于GMS的元数据信息,进一步恢复OSS上存储的冷数据。
在这个备份恢复的设计前提下,基于OSS的备份恢复流程如下:
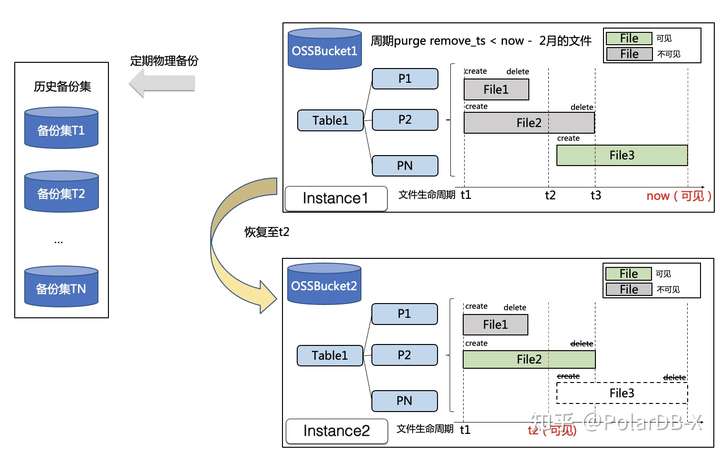
OSS数据备份流程:
1. 固定周期全量备份OSS数据文件
a. 管控需要先对CN发起Alter FileStorage OSS Backup指令,将GMS中维护的OSS数据文件元数据(主要包括数据文件名及对应的时间戳版本信息)持久化到OSS,文件名为files_meta.txt
b. 管控读取OSS中files_meta.txt文件获取所有文件元数据
c. 管控将数据文件逐个拷贝到备份OSS Bucket进行备份
2. OSS Schema元数据存储在GMS中,因此元数据的备份逻辑可以走MySQL基于Binlog的备份恢复流程。
3. 此外内核固定周期Purge过期老版本数据(Alter FileStorage OSS Purge Before Timestamp)保证每次备份数据集大小不会一直增大.(需要保证Purge周期 > 备份周期)
OSS数据恢复流程为:
1. 依赖InnoDB在线数据的备份恢复,恢复出一个PolarDB-X新实例,将GMS + DN找到最近全量备份+binlog增量恢复到指定时间点,此时对应时间点的OSS元数据会随着GMS恢复到指定时间点。
2. 选择OSS数据备份集:判断历史周期备份集中是否存在距离恢复时间最近且备份时间大于恢复时间的备份集,如果存在则选择;如果不存在满足条件的历史备份集,说明恢复时间距离当前时间较近,直接选择当前原实例OSS下的全部数据文件,并通过Alter FileStorage OSS Backup指令将GMS中维护的元数据文件推送至OSS。
3. 恢复任务将上面步骤中选取的OSS数据备份集拷贝一份到新实例,并更新新实例对应的OSS Bucket连接方式。
4. 新实例上CN上执行Alter FileStorage OSS As Of Timestamp '恢复指定时间' ,将OSS数据文件按时间戳裁剪至所需要的时间点。
数据文件的时间戳信息
上面提到通过Alter FileStorage OSS Backup指令,GMS中维护的OSS文件时间戳信息会被持久化到OSS的files_meta.txt文件中。我们来看看files_meta.txt到底包含什么信息。 它包含了当前OSS中所有的文件及其对应的时间戳信息commit_ts和remove_ts。通过这个文件我们可以避免昂贵的对象存储list开销,遍可以知道所有文件及其对应的时间戳信息,时间戳信息会被用户恢复过程中的数据裁剪。
{
"files":
[
{
"fileName": "data-e6c0-408a-9df5-298a44c0e66d.orc",
"removeTs": 6922448564517863488,
"commitTs": 6922444923815854144
},
{
"fileName": "data-c9ac-4541-b3ab-c80e932d0cfb.orc",
"commitTs": 6922448796521594944
}
]
}通过在OSS数据文件全量备份时,会同步备份对应的files_meta信息,从而保证在备份集恢复时可以获取到完整的文件列表视图,基于恢复的时间点进行进一步的数据裁剪。
冷数据备份恢复与数据裁剪
在上面冷数据的备份恢复流程中我们知道,冷数据的恢复是通过全量备份集应用数据裁剪来得到指定时间点的数据,主要设计上得益于冷数据文件的commit_ts与remove_ts多版本设计,可以在当前数据中直接进行多版本数据的查询和处理。
OSS多版本裁剪对应的SQL是Alter FileStorage OSS As Of Timestamp 'recover_ts',其中recover_ts指需要恢复的时间点,执行的流程是:
1. 获取OSS备份集中的files_meta.txt文件,获取当前OSS Bucket中所有的数据文件,及其对应的时间戳信息。
2. 根据recover_ts与每一个文件的commit_ts和remove_ts进行处理
if (file.commit_ts == null) {
// ignore, commit_ts == null 意味着文件还未提交,不处理
} else if (recover_ts < file.commit_ts) {
// delete file, 该文件的提交时间比恢复时间点大,需要删除
} else if (recover_ts >= file.commit_ts && file.remove_ts == null) {
// ignore,文件在恢复时间点前已经提交且未删除,保留
} else if (recover_ts >= file.commit_ts && recover_ts <= file.remove_ts) {
// update remove_ts = null,文件在恢复时间点前已经提交,而删除时间恢复时间之后,所以要将remove_ts置为null,使得文件可见
} else if (recover_ts > file.remove_ts) {
// ignore,文件的删除时间在恢复时间前,不处理,用户可以通过FlashBack Query查询
} else {
// impossible case
}如OSS存储备份恢复流程章节中的例子,如果要在当前备份集中恢复到t2的时间戳,需要清除 commit_ts > recover_ts(t2)对应的数据文件,比如图例中的F2文件,而此时F2.remove_ts > recover_ts(t2),在备份恢复中认为是一个未来的行为,在恢复后需要清除F2文件的remove_ts时间戳,然后用户使用当前时间查询时,F1不可见(remove_ts导致不可见)、F2可见、F3不可见(recover时被清除)
purge已删除的老版本数据
因为OSS文件的删除使用了标记删除,使得Time Travel成为可能。但如果长期不清理已删除的数据会导致数据占用空间过大,因此我们会后台定期调度Alter FileStorage OSS Purge Before Timestamp 'purge_ts'的DDL来触发已删除的老数据(例如删除的数据超过两个月后就会被物理清理)。
具体的实现算法比较简单,找到所有remove_ts < purge_ts的文件列表,逐个调用物理删除。如果数据被物理删除后,就无法通过Flashback或者recover恢复到删除的时间点,因此当前运行实例多版本数据最多支持回滚到purge_ts之内的数据,如果需要恢复到更早的时间点,则需要依赖周期性的物理备份,且物理备份周期应该小于purge周期。
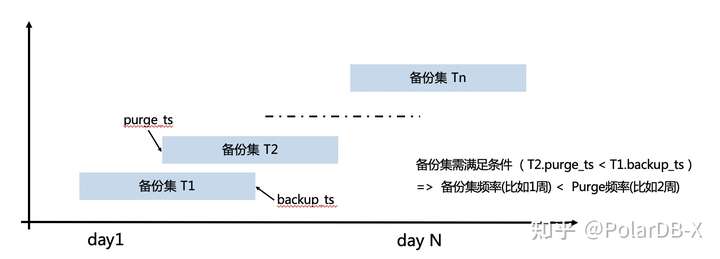
比如OSS的备份周期为N=1周,那purge_ts的策略需要保证至少大于N,一般建议是2N = 2周。
总结
PolarDB-X采用了OSS对象存储作为冷数据存储引擎,我们详细介绍了如何在OSS存储上做备份恢复,在最后简单做一下InnoDB和OSS备份方案的差异。
| InnoDB在线热数据 | OSS历史冷数据 | |
|---|---|---|
| 备份数据 | 全量+binlog增量 | 元数据复用InnoDB备份能力 + 数据文件全量拷贝 |
| 恢复数据 | 全量+增量Apply | 元数据复用InnoDB恢复能力 + 数据文件按时间戳裁剪 |
| 备份周期 | 天级别或周级别 | 周或者月级别 |
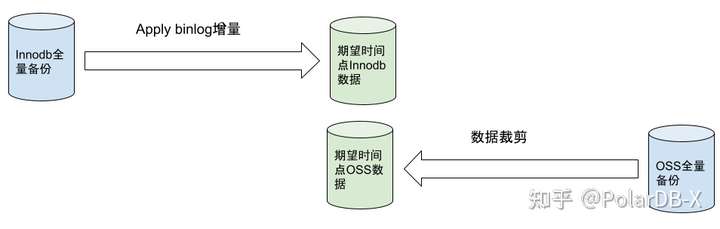
如上图所示,InnoDB和OSS备份恢复的一大区别是:InnoDB会找到最近小于恢复时间点的全量备份集,再应用增量来恢复到指定时间点,而OSS则是找到最近大于恢复时间点的备份集,利用数据集内置增量数据,再应用裁剪机制来恢复到指定的时间点。
PolarDB-X提供了一体化的InnoDB + OSS的冷热数据分离存储,支持正常的业务数据链路交互,比如可以通过兼容MySQL的语法访问OSS的冷数据,以及支持一体化的数据库运维体验,全面减低用户的上手和运维成本。
文章来源:阿里云数据库
