




1. 背景
高频海量数据更新: 在搜索推荐中经常会涉及到海量数据的批量更新,单表记录数在亿级别是非常常见的,并且大批量数据更新很频繁,很多公司可能选择Redis\Hbase之类的一些开源的存储系统,但是它们都并不太适合推荐及推荐这种场景下使用,如一张100G的亿级别数据导入到Redis或者Hbase中在高并发的情况下这可能是一种灾难
检索数据量大,并且对性能要求高: 单次请求过程中召回数万级的数据响应性在5-10毫秒以内这个是一个比较低的要求了,这万级别的数据可能还要去关联检索物品属性、特征等等,一般来说推荐过程中单次响应时长会要求在100毫秒左右,所以对检索的性能要求非常高。还比如排序过程中排量查询1000甚至更多物品特征,单特征表字段80-100个字段想象一下这种性能慢得会有多夸张
检索类型多,需要一套架构支持多种引擎: KV、倒排、向量这三种检索能力在搜索及推荐当中这是最基本的了,通过一套架构方案集成多种检索引擎大量的减少了系统的维护成本及系统的复杂度
基于上面的一些原因的总合我们选择在开源的一些引擎下自研更贴合搜索与推荐的存储引擎
2. 总体设计
2.1. 系统架构 - 如何支撑亿级索引、毫秒级的检索
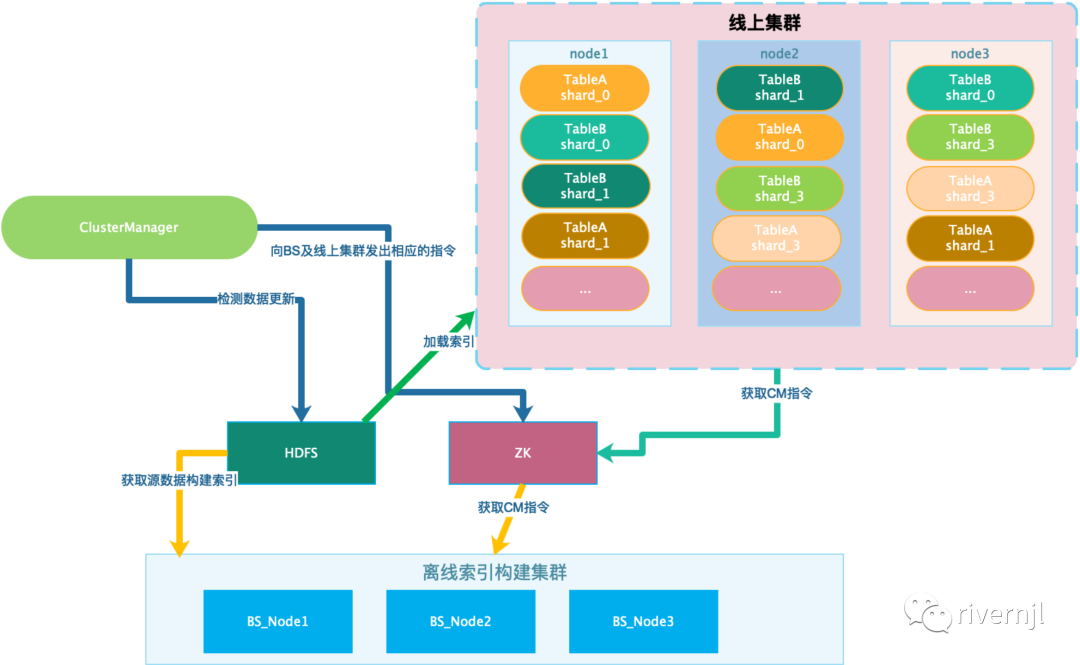
ClusterManager
是整个服务的中心控制台,所有的过引构建、集群资源分析、线上集群扩缩容、索引更新等都由ClusterManger发送控制命令
BS
索引构建服务,进行离线及实时数据处理及索引构建,如果是向量索引的话还提供向量索引模型训练如聚类模型训练
线上服务
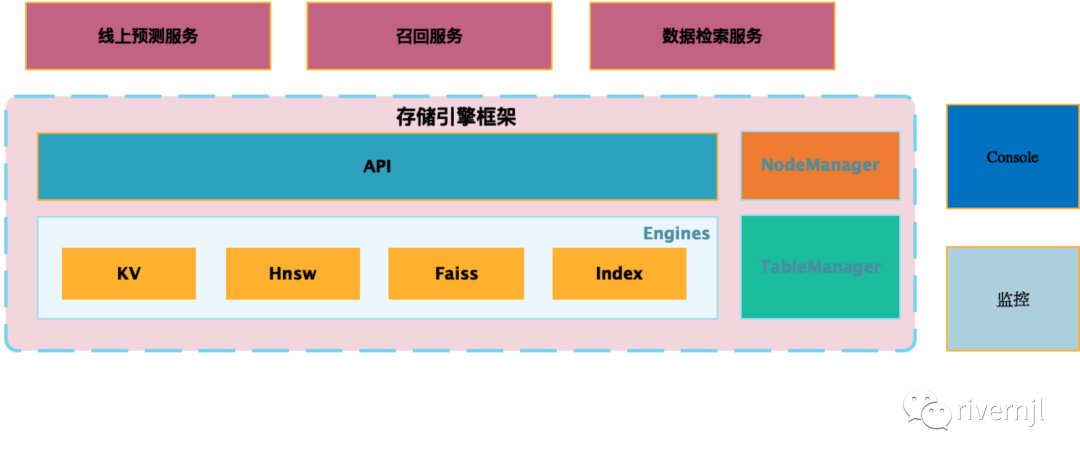
整套储存框架以可嵌入式提供,上层的服务可以将储存框架嵌入自身的服务当中,则这个服务就具备了存储检索能力、系统管控能力、集群管理等等能力。
线上服务通过检索API提供KV\向量\倒排等数据检索,Engines里集成了不同的检索库,NodeManager提供集群结点管理功能,如结点状态管理。TableManager提供表的更新、下线、上线等等管理功能、Console提供统一的管理界面,使用人员可以通过图形化的界面进行相关的操作
2.2. 系统扩展 - 单机资源有限,数据装不下怎么办
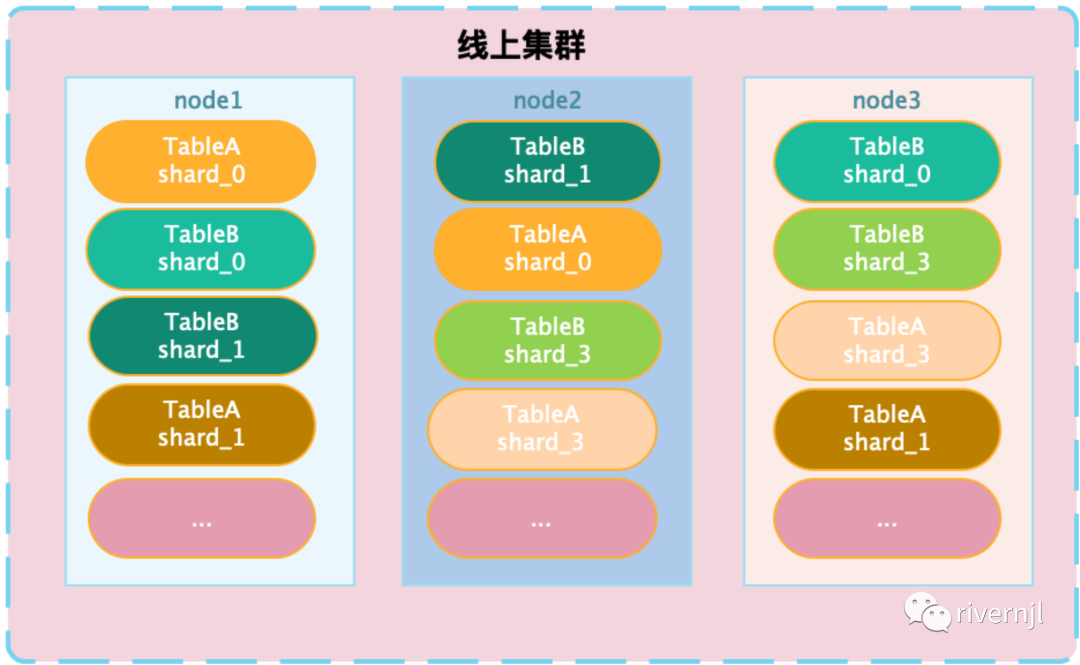
数据分片进行存储,同一张表的不同分片数据可以分布在相同的机器,第一个分片的数据存在多个副本,也可以分布在不同的机器上面,每台机器可以做为一个proxy的角色,请求过来之后proxy根据当前检索的数据计算出数据的分片信息,根据分片取出当前分片所在的机器列表,通过负载均衡相关的算法获取其中一台机器进行数据检索,检索完成后proxy负责对数据进行合并并进行数据返回.
2.3. 如何支撑亿级别的离线数据批量更新
2.3.1. 索引生成
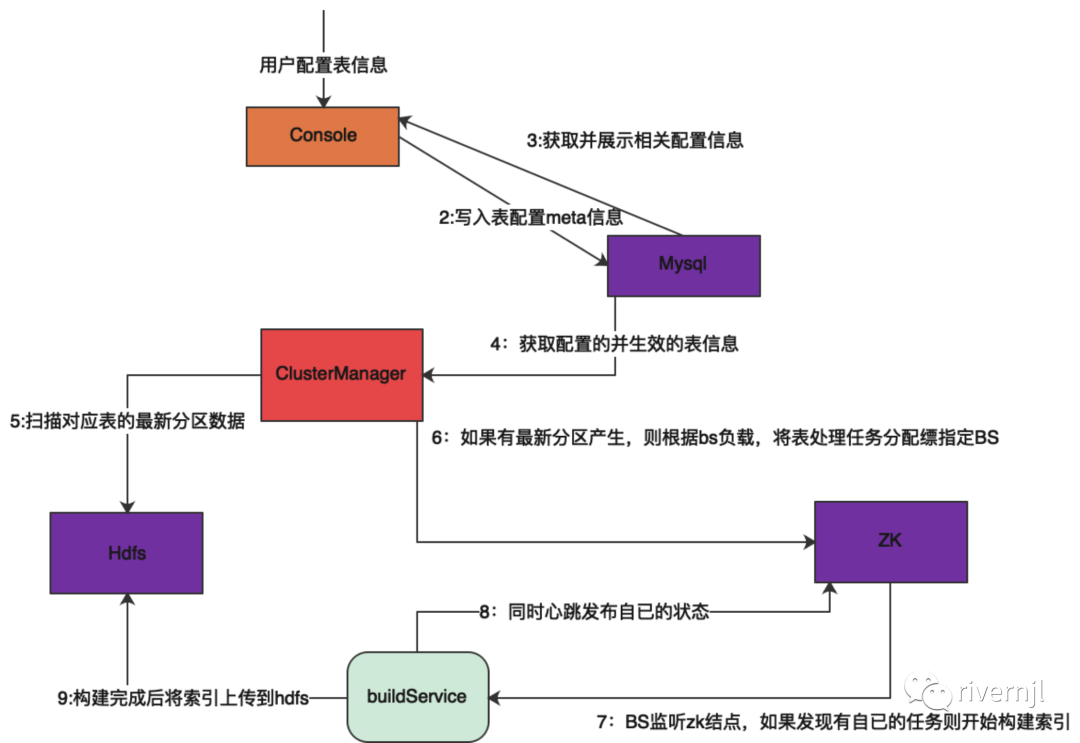
1. ClusterManager扫描数据表变更,生成数据版本信息(数据版本可以作废,作废后不再会发送到线上),并发送指令给BuildService构建索引
2. 如果有指定的表有最新数据则根据当前BS机器负载情况将任务分配给最闲的机器进行build
3. buildService监听zk结点,发现自已有任务需要做则启动构建索引任务,同时上报自已的心跳信息
4. buildService构建完索引将索引上传到hdfs
2.3.2. 线上数据更新
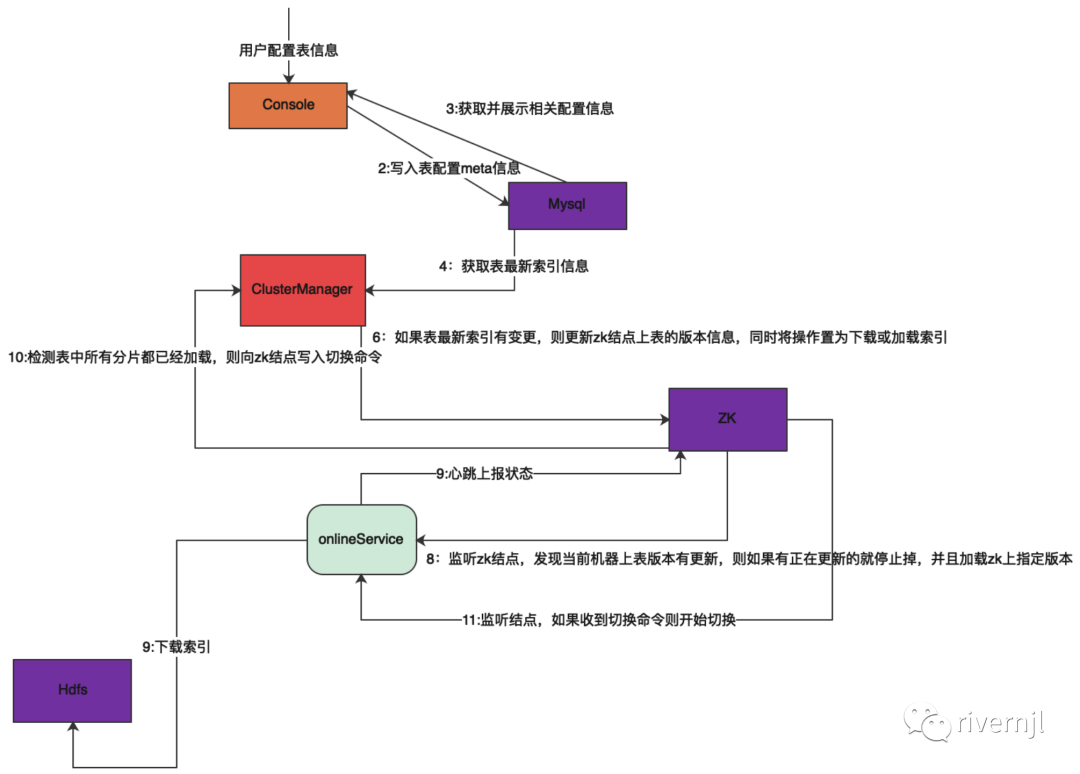
1. ClusteManager收集最新产生的索引信息,如果有表有更新则将表的最新版本更新到zk
2. 线上服务监听对应结点,发现指定表有索引更新则判定本地状态,如果当前表正在更新则停止正在更新动作(如果没有正在更新这一步则不做),然后下载指定远程索引并进行加载,加载完成后跟随心跳上报状态
3. ClusteManager检测表指定版本的所有分片及分片的副本都被加载了向zk写入切换命令
4. 线上服务监听结点,收到监听命令后更切换索引(切换索引只能涉及到指引的更变,时间微秒级)
5. 同时根随心跳上报当前状态
2.3.3. 服务扩索容
2.3.3.1. 线上服务扩列及缩列管理
1. 用户通过console进行扩列操作,同时生成一条扩列任务信息
2. 当前集群上的表都需要重新构建
3. 当所有表构建流程和线上索引加载过程与前面列的流程一致
4. ClusteManager根据当前扩列信息检测所有表的最新索引列是否都已被线上加载了,如果都加载了则发送索引切换命令
5. 如果没有处理完则等待前面的流程
2.3.3.2. 线上服务扩缩行
扩缩行相对简单,只需要指定列的行将索引加载完成后即可提供服务,如果未加载完成当前机器只是一个proxy的角色,将所有请求都分发到其它结点进行服务
2.4. 离线+增量数据更新
2.4.1. 离线全量索引构建流程
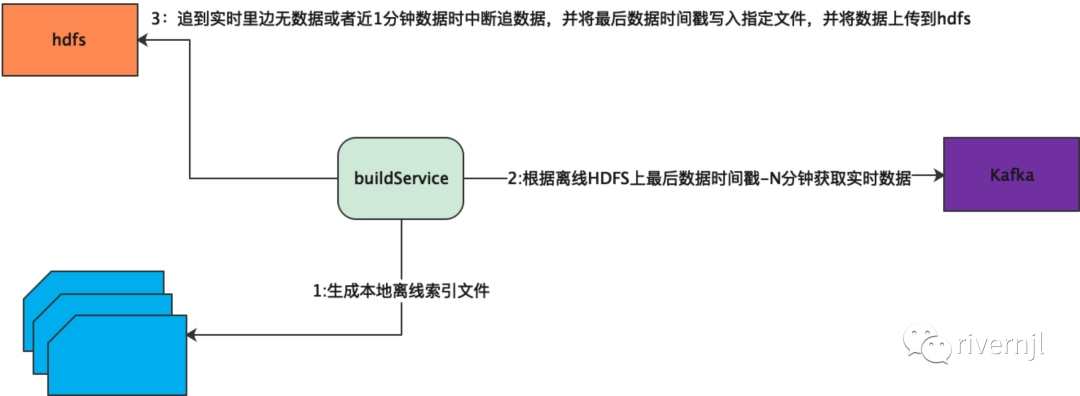
在全量离线索引构建完成后检查表是否带有增量数据,如果带有增量数据则根据数据产生者指定的追数据起始时间开始追回增量数据,如果数据生产者没有产生数据则如果是天分区那就从当前分区的的天的0:00:00开始追增量数据,如果是小时分区则从当前小时的整点开始追数据,增量数据追到没数据或者当前时间点的前1分钟的数据则停止,之后写入最后数据时间戳,BS本地关闭表,并上传文件到远程。
2.4.2. 增量数据备份
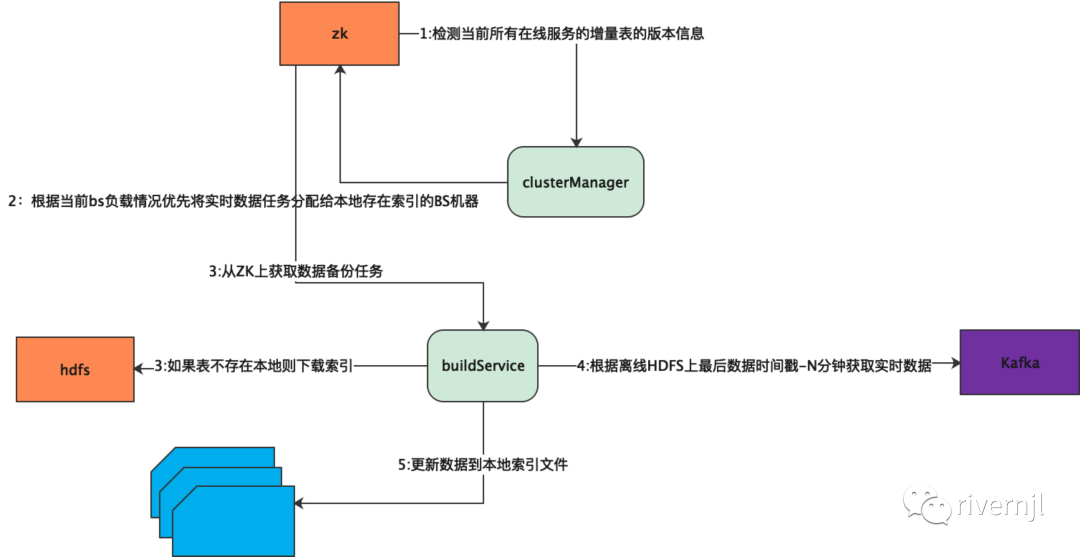
clusterManager根据当前线上用到的表及表版本信息,根据bs的情况分配实时索引备份任务,优先将任务分配给本地存在索引的bs结点,bs获取到任务后开始追增量数据更新到本地索引,所有表数据按配置的固定时间间隔将本地备份索引上传到hdfs,如果bs机器当机或者下线,bs任务将被重新分配到新结点,新结点以hdfs上的最后索引数据时间重新追加数据
2.4.3. 线上机器扩容或者机器替换时增量处理
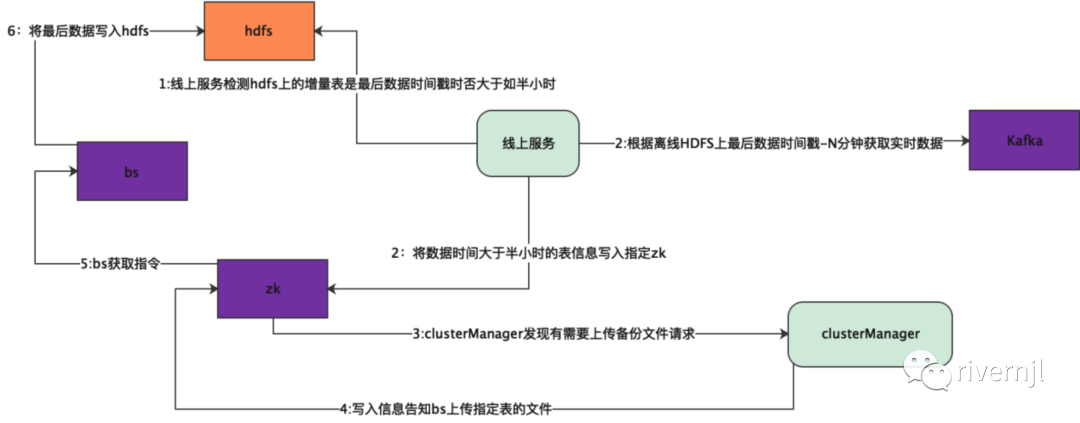
1:线上机器扩容时在下载文件时检测增量表的最后数据时间是否大于指定时间如半小时,如果大于则告知clusterMananager需要通知bs将最新的索引上传,bs收到指令后上传文件
2:线上服务重复上面流程,如果发现索引已更新则下载最新索引文件
3:所有索引都切换ok后向线上提供服务
2.4.4. 线上服务表切换

线上服务先从hdfs上下载索引文件,下载完成后根据最索引文件中的最新时间戳追加新的数据,追加数据完成后切换索引上线
2.5. 存储引擎选型及优化
2.5.1. ANN检索
ANN检索引擎选型
目前ANN检索有很多比较优秀的开源库,如如 nmslib、hnswlib、faiss 等等,hnswlib库性能检索性能最为优秀,在Cosine similarity上召回率能达到95%以上能满足大部分推荐场景向量检索需求,同时整个库代码简单,集成起来相对比较方便
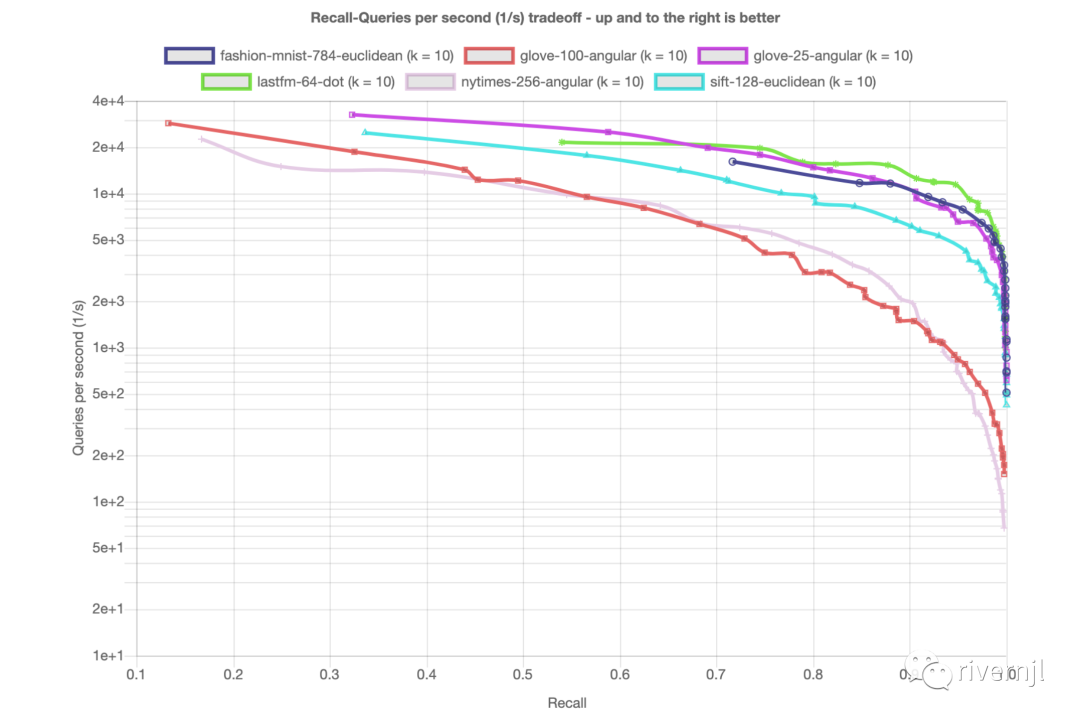
(性能对比图)
hnswlib支持空间距离如下:

扩展HNSWLIB,节约内存资源,丰富使用场景
1: 很多场景下我们的数据label需要的是string类型的,比如一个词向量,词为字符串类型,但是原生的label只支持长整型
2: 原生的索引结构中label是直接加载到内存中的,这样索引加载后占用大量内存,我们需要的是冷数据存储在磁盘,热的label数据存储在内存中
3: 在很多推荐场景下算法做物品间的embbding 是全局的数据,但是在小业务场景下只限制在固定的数据池内进行推荐,如果将label->vector单独存储,同时针对小场景下构建向量索引的话label->vector的数据及索引数据需要做数据版本对齐,整体系统会复杂
针对上面我们对hnswlib进行了扩展
原生的存储结构如下:
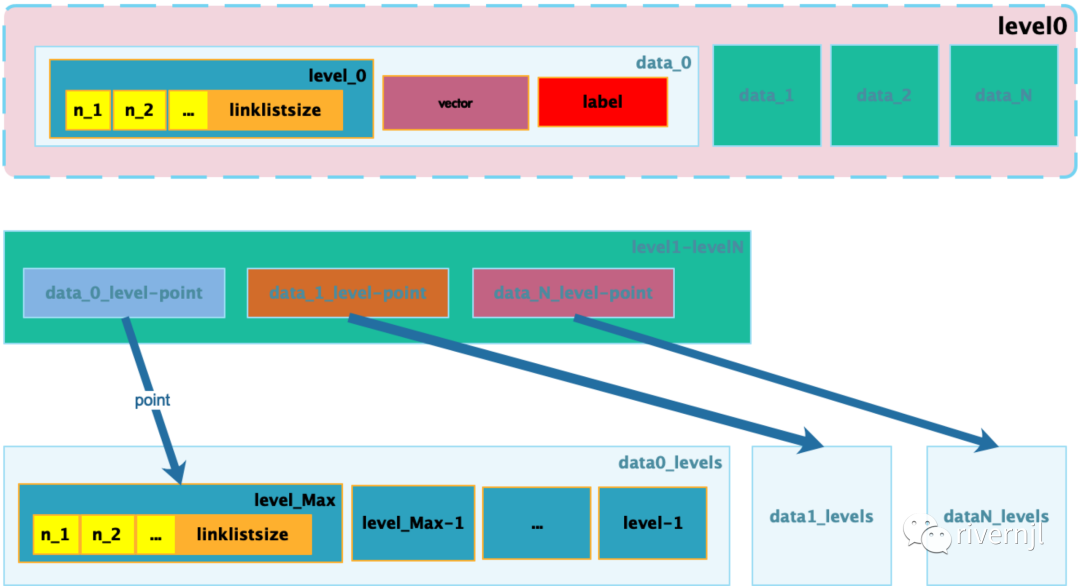
改造后的数据存储结构
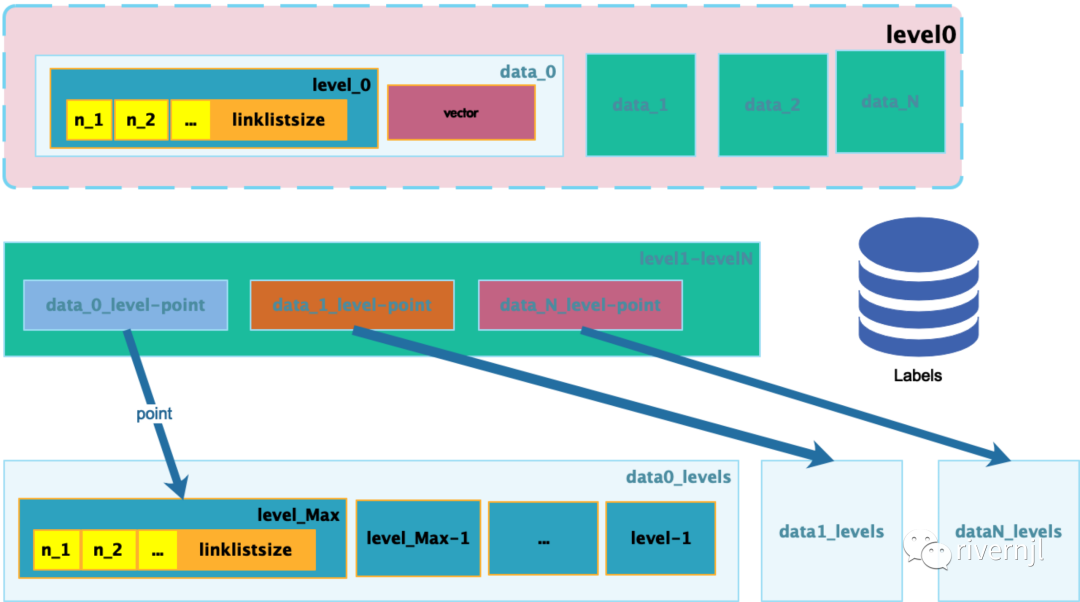
将label从纯内存中迁移到了文件+内存模式进行存储,同时label从原来的索引结构迁出后可以支持string类型的数据,同时在API层面支持只保存向量到文件存储系统中,这样就解决了我们所面临的问题,上线后整体系统的内存占用比起原生的库节省了1半以上,同时在检索性能上比原稍慢一些,但是整体在内存与性能的平衡上这种情能差距还是可以接受的
2.5.2. KV存储引擎
KV引擎选型
目前比较常见的几类存储引擎读写性能及存储空间占比性能比较如下:
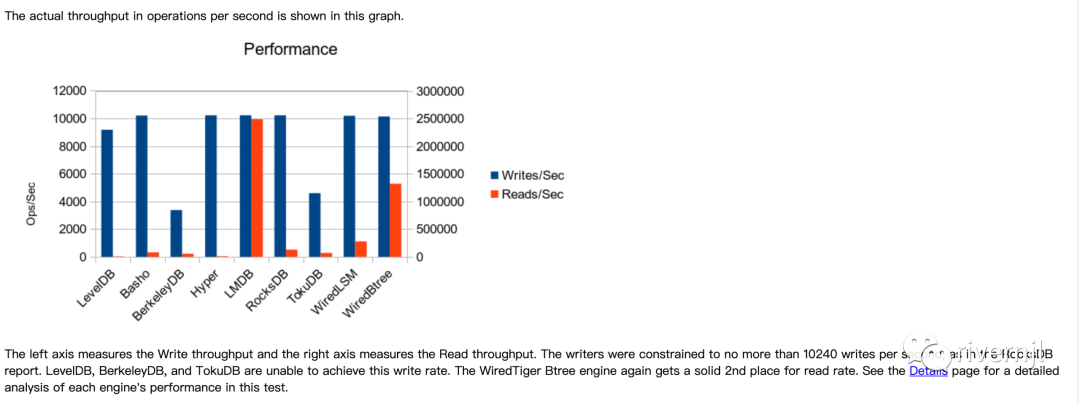
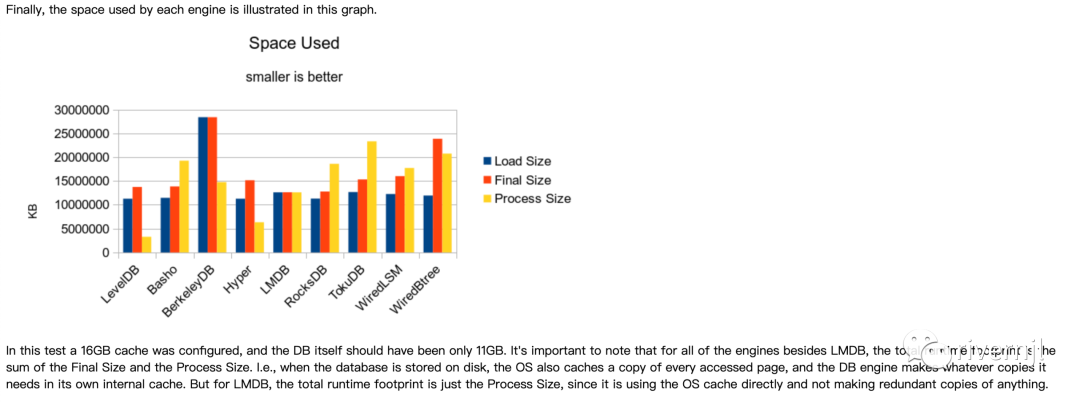
通过综合的比较,我们最终选择RocksDB做为我们的存储引擎
1:Rocksdb开源,并且是一种可嵌入式、持久化存储,方便我们进行定制化开发,与自身的系统进行集成
2:Rocksdb基于c++进行编写,c++当前主流语言,团队成员容易对它进行扩展
3:各方面综合比较来说Rocksdb是比较均衡的,写入及检索性能相对来说表现的还算比较优秀
优化存储,节省存储空间,提升检索性能
1:优化存储数据的序列化及反序列化

每张表有一个独立的schema用于定义表的字段、数据类型等信息,每条记录的数据按数据类型以二进制的方式紧
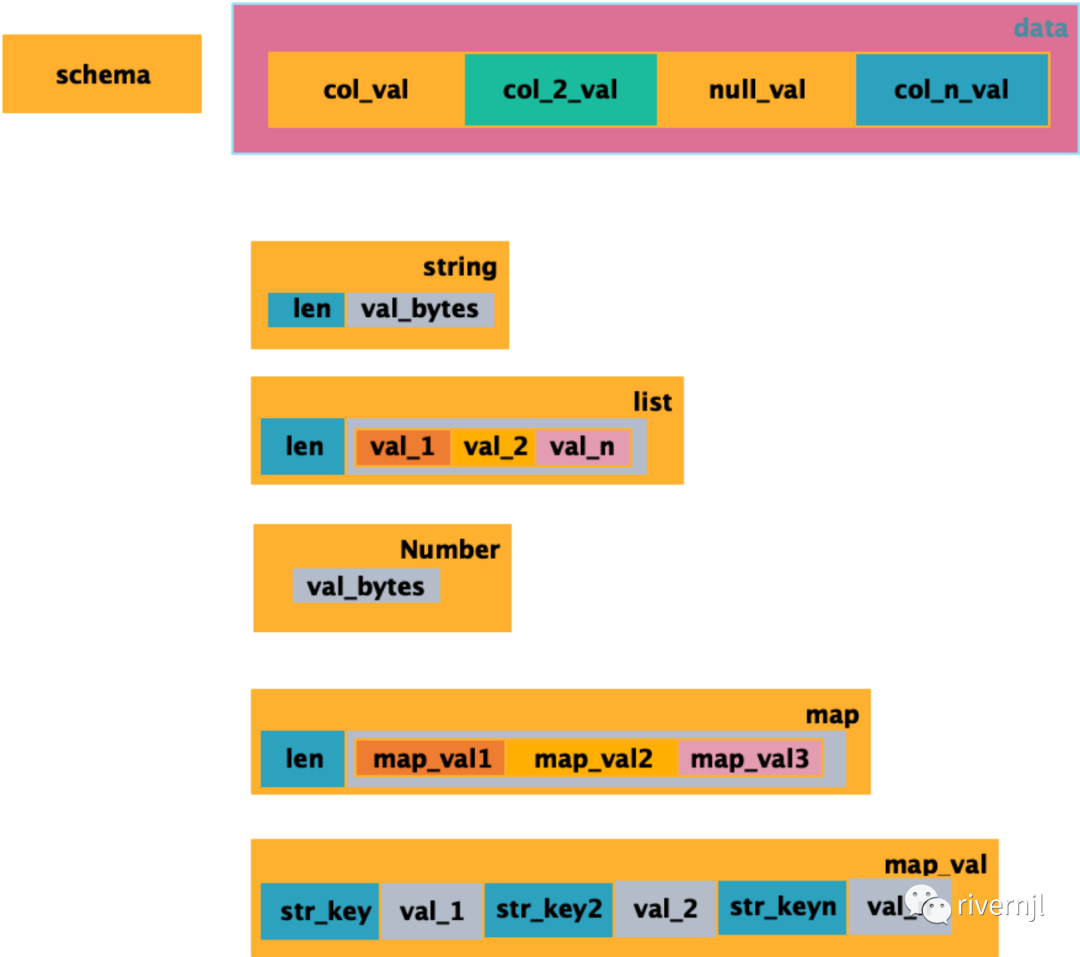
每张表有一个schema定义表的字段及字段类型等信息,表的数据类型支持常用的数字类型,string,list,map等数据结构,如果遇到空字段用一位byte标识为空,整个数据数据紧凑没有太多冗余的信息,减少了存储空间,反序列化过程是一个顺序读取内存数据过程,整体性能消耗很低。
2:优化数据存储模式,提升检索性能
从mmap到Block Cache从上线之初为了性能我们使用了mmap模式,但是效果并没有达到我们的预确,在没有大数据量更新的情况下系统检索性能确实表现还比较优异,但是每当有大数据表更新如一张几十G的表进行更新时,就会间断性的出现检索超时:
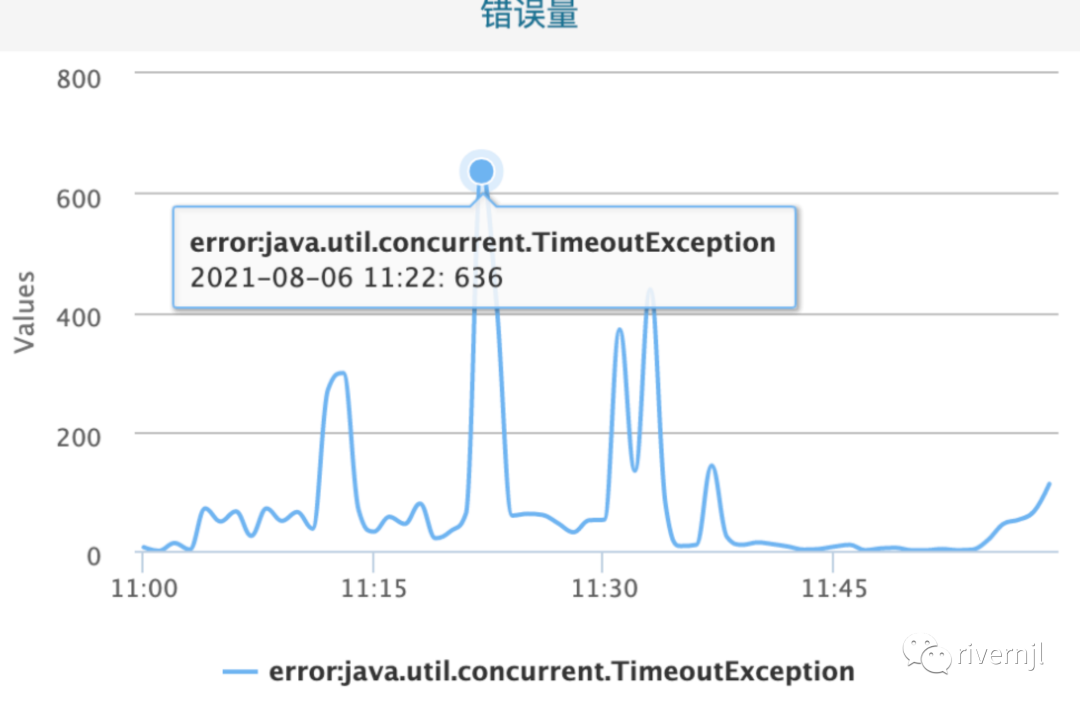
经分析发现文件写入本地磁盘会占用一部分的cache,会将线上cache在内存中的数据换出去,这样造成大量数据需要通过磁盘检索,导致系统性能下降,于是我们采用BlockCache模式,进程独占内存块,不受其它影响,使用BlockCache后线上检索响应不再出现超时现象
同时为了更好的提升性能,在对数据块进行Cache的同时,我们分配出一块小内存进行RowCache,RowCache采用LRU存储模式,将最热的数据放入缓存块中,增加RowCache后系统整体检索性能提升5%左右.
3. 总结与展望
整个平台研发完成后被推广到推荐的各个子系统中使用,相对之前使用第三方存储库,我们取得了如下的成效:
检索性能的提升 整体系统的召回能力比以前提升了2-3倍以上,整体在线预测流程性能提升了2倍以上
数据更新效率的提升 线上数据更新单表记录如30-40G的特征数据更新整体提升了10倍
资源成本的降低 新的服务上线后整体的资源成本节省比以前降低2倍以上
系统维护成本及平台技术架构复杂度的降低 以前我们需要维护三套存储引擎,每套存储引擎有不同的技术架构,整个系统的复杂度及系统的维护成本非常高,新的引擎上线后统一成一套架构架构体系,降低了系统的维护成本,整个系统的技术架构的复杂度也降底了很多
后续系统还需要持续的进行优化,以满足公司业务发展的需要,我们还需要持续的在如下的一些方向上前行:
存储引擎还需要扩充向量检索的能力,以满足更多的应用场景,比如HNSW在Inner product距离计算上召回的准确率并不如人意,我们需要支持聚类等检索模型,在更大规模数据集下我们需要通过更好的算法对索引数据进行压缩以支撑更大规模的向量检索。 在KV检索上我们需要支持更丰富的存储模式,如KKV数据检索模式、超大规模集群下更新大索引时索引下载性能优化、同时需要在索引层面支持部分字段检索以提升超大字段表的检索性能等等。在集群管理方面资源可以动态调度,达到分钟级界面一键快速扩缩容及新集群的创建.
