




我最近开始在 Postgres 中使用 H3 十六进制网格扩展,目的是让一些不太快的查询更快。我之前的文章 Using Uber’s H3 hex grid in PostGIS 介绍了 H3 扩展。诚然,该帖子的重点是 PostGIS 重点视图,而不是 H3 重点视图。这篇文章仔细研究了使用 H3 扩展来提高空间搜索的性能。
本文考虑的两种常见空间查询模式是:
- 最近邻样式搜索
- 区域分析
设置和焦点
这篇文章使用两个表来检查性能。以下查询将一h3_ix列添加到osm.natural_point 和 osm.building_polygon 表。这种方法使用 GENERATED 列,并向列添加索引。通过这些步骤,我们可以在查询时消除对 PostGIS 连接的需要,以进行粗略的距离搜索。有关安装 H3 扩展及其工作原理的详细信息,请参阅我 之前的帖子。
这篇文章中使用的数据是使用PgOSM Flex加载的 Colorado OpenStreetMap 数据。
首先,将 H3 索引添加到 osm.natural_point 表中。osm.natural_point 计算 H3 索引并在表上创建索引大约需要3秒。
ALTER TABLE osm.natural_point ADD h3_ix H3INDEX
GENERATED ALWAYS AS (
h3_geo_to_h3(ST_Transform(geom, 4326), 7)
) STORED
;
CREATE INDEX gix_natural_point_h3_ix
ON osm.natural_point (h3_ix);
要在表上创建 H3 索引,osm.building_polygon 我们需要将ST_Centroid() 步骤添加到定义中。在构建多边形表上运行这些步骤大约需要 12 秒。
ALTER TABLE osm.building_polygon ADD h3_ix H3INDEX
GENERATED ALWAYS AS (
h3_geo_to_h3(ST_Transform(ST_Centroid(geom), 4326), 7)
) STORED
;
CREATE INDEX gix_building_polygon_h3_ix
ON osm.building_polygon (h3_ix);
现在为这两个表计算 H3 索引。我的下一步是选择一座建筑物,作为即将到来的空间搜索示例的焦点。我使用它的 osm_id. 以下查询返回 h3_ix,该点显示在以下屏幕截图中的地图上。
SELECT osm_id, name, h3_ix, geom
FROM osm.building_polygon
WHERE osm_id = 392853178
;
┌───────────┬────────────────────────┬─────────────────┐
│ osm_id │ name │ h3_ix │
╞═══════════╪════════════════════════╪═════════════════╡
│ 392853178 │ Pangea Coffee Roasters │ 872681364ffffff │
└───────────┴────────────────────────┴─────────────────┘
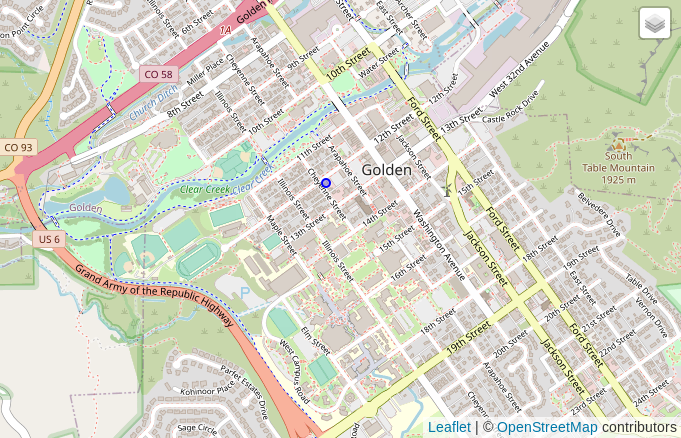
上面的查询返回包含 Pangea Coffee Roasters 的分辨率 7 十六进制的 h3_ix 值 ( 872681364ffffff)。我们可以使用该h3_to_geo_boundary_geometry() 函数查看十六进制的多边形。
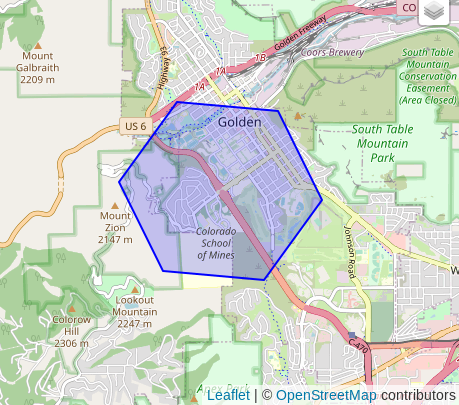
SELECT h3_to_geo_boundary_geometry('872681364ffffff');
使用 H3 的 网格遍历函数 很容易找到六边形的环数和半径大小之间的基本关系。以下查询使用该函数包括围绕焦点 ( )h3_k_ring()的六角形的 3 个六角形环。872681364ffffff 碰巧的是,这个 3 环十六进制缓冲区与使用 SRID 3857 计算的 10 公里缓冲区大致对齐。还显示了 10 公里缓冲区以进行比较。
-- Resolution 7, looking out 3 rings -- Roughly 10 km radius!
SELECT b.osm_id,
ST_Buffer(b.geom, 10000) AS buffer_10km,
b.geom,
h3_to_geo_boundary_geometry(
h3_k_ring(h3_geo_to_h3(ST_Transform(b.geom, 4326), 7), 3)
) AS ix_ring
FROM osm.vbuilding_all b
WHERE b.osm_id = 392853178
;
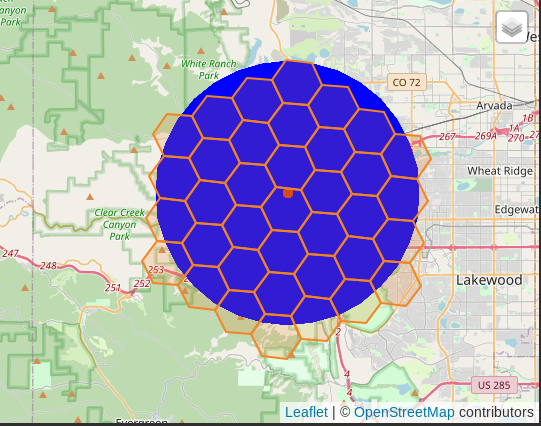
这h3_k_ring()是 H3 指数提供的众多功能之一。查看完整的 API 参考以了解其余功能。
要使半径大 4 倍,我们可以将这两个值乘以 4,以在h3_k_ring()函数中使用 40 公里缓冲区和 12 环十六进制缓冲区。这会产生一个由 469 个六边形组成的网格。
-- Looking out 3*4 (12) rings -- Roughly 10*4 km (40km) radius!
SELECT b.osm_id,
ST_Buffer(b.geom, 10000*4) AS buffer_10km,
b.geom,
h3_to_geo_boundary_geometry(
h3_k_ring(h3_geo_to_h3(ST_Transform(b.geom, 4326), 7), 3*4)
) AS ix_ring
FROM osm.vbuilding_all b
WHERE b.osm_id = 392853178
;
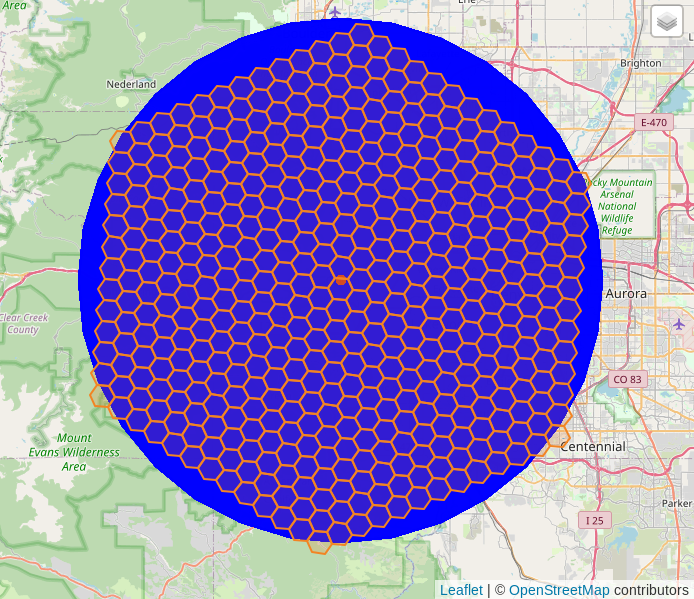
上面的例子表明,我能够在我们已知的测量(10 公里)和更抽象的测量(分辨率为 7 的 3 个六角环)之间快速建立粗略的关系。有一个有点熟悉的参考框架对我们人类和可用性是有帮助的。
最近邻样式搜索
此示例使用 PostGIS 的ST_DWithin()功能来查找距焦点 10 公里范围内的树木。这个使用传统空间连接的查询需要 14 - 25 毫秒才能运行。它返回大约 12,000 行。
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT JSON)
SELECT b.osm_id, b.name, b.height, n.geom
FROM osm.building_polygon b
INNER JOIN osm.natural_point n
ON n.osm_type = 'tree' AND ST_DWithin(b.geom, n.geom, 10000)
WHERE b.osm_id = 392853178
;
由 pgMustard 可视化的查询计划 表明该查询非常有效。以下屏幕截图显示了节点的主要概述以及总时间和节点计时。使用了 GIST 索引natural_point,占用了 8ms 的查询时间。
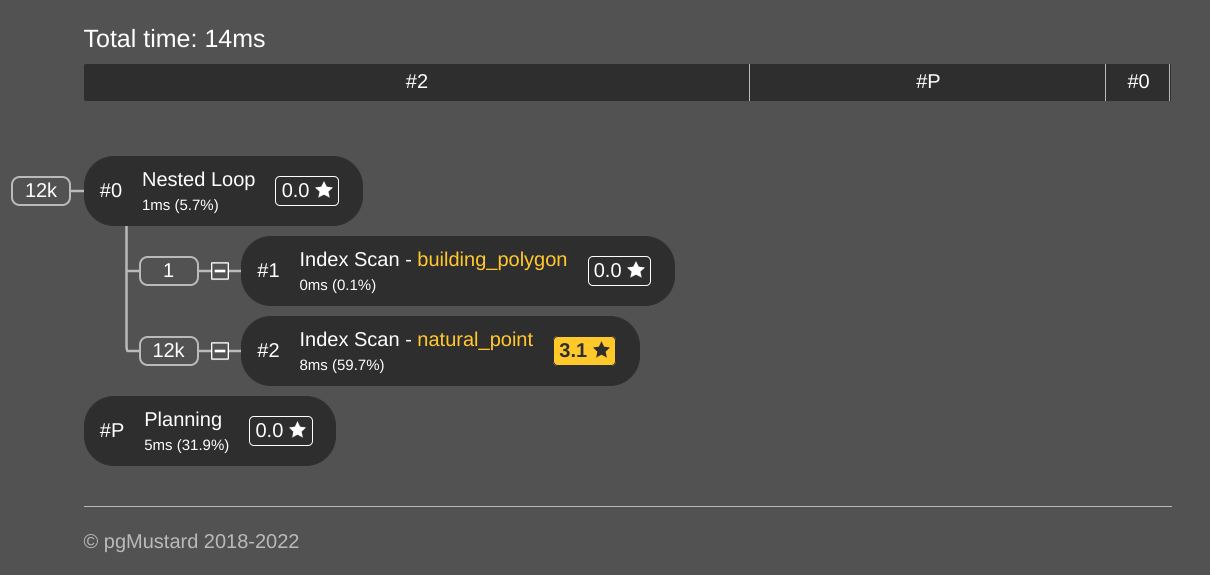
如果您仔细查看行估计(打开指向 pgMustard 的链接!),您会注意到返回的估计行natural_point与实际行数有很大差异。在此查询的情况下,它“超出了 390.4 倍”。空间连接通常具有查询计划器使用的较差行估计,并且通常是空间查询性能较差的原因。
下一个查询使用来自所选建筑物的 H3 索引,并传递h3_ix给h3_k_ring()函数。这将创建用于连接到osm.natural_point表的 3 环十六进制缓冲区,替换空间连接。使用 H3 索引的查询速度提高了 73%,在 4 - 6 毫秒内返回。查询计划 显示再次使用了两个索引。此查询还返回大约 12,000 行。
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT JSON)
WITH rng AS (
SELECT h3_k_ring(h3_ix, 3)
AS ix_ring
FROM osm.building_polygon b
WHERE b.osm_id = 392853178
)
SELECT *
FROM rng b
INNER JOIN osm.natural_point n
ON n.osm_type = 'tree'
AND n.h3_ix = b.ix_ring
;

增加结果大小
此部分将查询切换为查找 40 公里半径内的建筑物,而不是 10 公里内的树木。通过此更改,以下查询每个返回大约 340,000 行。与 40 公里半径的空间连接ST_DWithin()在 459 毫秒内返回。使用 12 环十六进制缓冲区在大约 100 毫秒内返回,快 78%。
ELECT b.osm_id, b.name, b.height, n.geom
FROM osm.building_polygon b
INNER JOIN osm.building_polygon n
ON ST_DWithin(b.geom, n.geom, 10000*4)
WHERE b.osm_id = 392853178
;
WITH rng AS (
SELECT h3_k_ring(h3_ix, 3*4)
AS ix_ring
FROM osm.building_polygon b
WHERE b.osm_id = 392853178
)
SELECT *
FROM rng b
INNER JOIN osm.building_polygon n
ON n.h3_ix = b.ix_ring
;
区域分析
上面的查询使用在“this”的“a distance”内查找“those”的模式。本节切换到查询以回答“向我展示跨区域的这种模式”问题。我的帖子使用 PostGIS 在 OpenStreetMap 中查找丢失的过境点 就是这种类型的分析示例。
由于我的测试数据库已经有可用于树木和建筑物的 H3 索引,因此此示例计算每个十六进制内每个建筑物的树木数量。第一个查询使用要素表和h3.hex表之间的空间连接。
该h3.hex表是按照我在上一篇文章“保存六角形”下概述的步骤创建的,以涵盖科罗拉多州。
WITH bldgs AS (
SELECT h.ix AS h3_ix, 'building' AS src, COUNT(*) AS cnt
FROM osm.building_polygon b
INNER JOIN h3.hex h ON ST_Contains(h.geom_3857, ST_Centroid(b.geom))
GROUP BY h.ix
), trs AS (
SELECT h.ix AS h3_ix, n.osm_type AS src, COUNT(*) AS cnt
FROM osm.natural_point n
INNER JOIN h3.hex h ON ST_Contains(h.geom_3857, n.geom)
WHERE n.osm_type = 'tree'
GROUP BY h.ix, n.osm_type
)
SELECT COALESCE(b.h3_ix, t.h3_ix) AS h3_ix,
CASE WHEN b.cnt > 0
THEN 1.0 * t.cnt / b.cnt
ELSE NULL
END AS tree_per_bldg
FROM bldgs b
FULL JOIN trs t ON b.h3_ix = t.h3_ix
;
下一个查询使用 H3 索引。通过使用这些索引,聚合查询不需要知道数据的“位置”,只需要知道 H3 索引。该h3_ix列基本上只是一小段文字。
WITH bldgs AS (
SELECT h3_ix, 'building' AS src, COUNT(*) AS cnt
FROM osm.building_polygon
GROUP BY h3_ix
), trs AS (
SELECT h3_ix, osm_type AS src, COUNT(*) AS cnt
FROM osm.natural_point
WHERE osm_type = 'tree'
GROUP BY h3_ix, osm_type
)
SELECT COALESCE(b.h3_ix, t.h3_ix) AS h3_ix,
CASE WHEN b.cnt > 0
THEN 1.0 * t.cnt / b.cnt
ELSE NULL
END AS tree_per_bldg
FROM bldgs b
FULL JOIN trs t ON b.h3_ix = t.h3_ix
;
使用空间连接的查询耗时 22 秒(查询计划)。
使用 H3 索引的查询只用了 182 毫秒……快了 99%!(查询计划)
缓冲区总和:工作量度
当查看之前在 pgMustard 中使用空间连接的查询计划 时,“缓冲区总和”细节引起了我的注意。以下屏幕截图显示报告使用了 51 GB 的缓冲区!
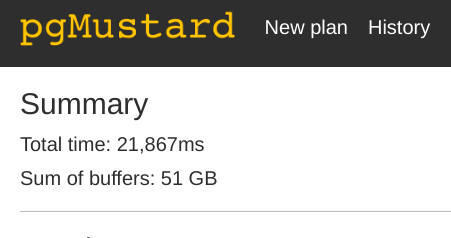
我知道所涉及的表的总大小远低于 1 GB。这让我很好奇,所以我问了 pgMustard 的联合创始人 Michael Christofides,缓冲区总和计算的背后是什么。
“pgMustard 做了一些算术来计算(并显示)这些在每个节点的基础上,在缓冲区部分。它现在还粗略地计算出它们中的每一个在 kB/MB/GB/TB 中代表多少数据,假设一个 8kB 块尺寸。
总和只是将所有这些每个节点的数字加在一起的粗略相加!自然地,对于同一个查询,块可以被多次读取,并且对磁盘的读取和写入是双重计算的,但是由于我认为它是“完成工作”的一个非常粗略的衡量标准,我认为总和的效果非常好。它并不完美,我仍然更关注时间安排,但我认为它可以帮助人们理解为什么有些事情比他们预期的要慢!”——迈克尔·克里斯托菲德斯
诚然,这个总数一开始就让我失望了。在查看了许多查询计划的这个值之后,它在我身上成长了!这似乎是一个不错的指标,一个查询正在使用多少数据,这是一件值得关注的事情。已经很强大的工具的另一个重要补充。
概括
这篇文章探索了在 Postgres 中使用 H3 扩展,目的是提高特定类型空间查询的性能。
- 最近邻样式搜索
- 区域分析
我为最近邻搜索测试的两个查询使用 H3 索引执行速度提高了 73% - 77%。区域分析速度提高了 99%。这些都是巨大的胜利,尤其是随着数据量的增长和空间查询的复杂性增加。使用这些模式的查询通常需要几分钟才能运行。减少 70-99% 的查询时间对我来说听起来不错!
原文标题:H3 indexes for performance with PostGIS data
原文作者:Ryan Lambert
原文地址:https://blog.rustprooflabs.com/2022/06/h3-indexes-on-postgis-data
