




随着其正式发布,Milvus 2.1具有许多新功能,如内存副本、支持字符串数据类型、嵌入式Milvus、可调一致性、用户身份验证和传输中的加密,以提供方便和更好的用户体验。虽然内存中副本的概念对于分布式数据库来说并不新鲜,但它是一个关键功能,可以帮助您轻松提高系统性能、提高数据库读取吞吐量并提高硬件资源的利用率。
因此,这篇文章开始解释什么是内存副本以及为什么它很重要,然后介绍如何在人工智能的矢量数据库Milvus中启用这一新功能。
与内存副本相关的概念
在了解内存副本是什么以及为什么重要之前,我们需要首先了解一些相关概念,包括副本组、碎片副本、流副本、历史副本和碎片领导者。下图是这些概念的说明。
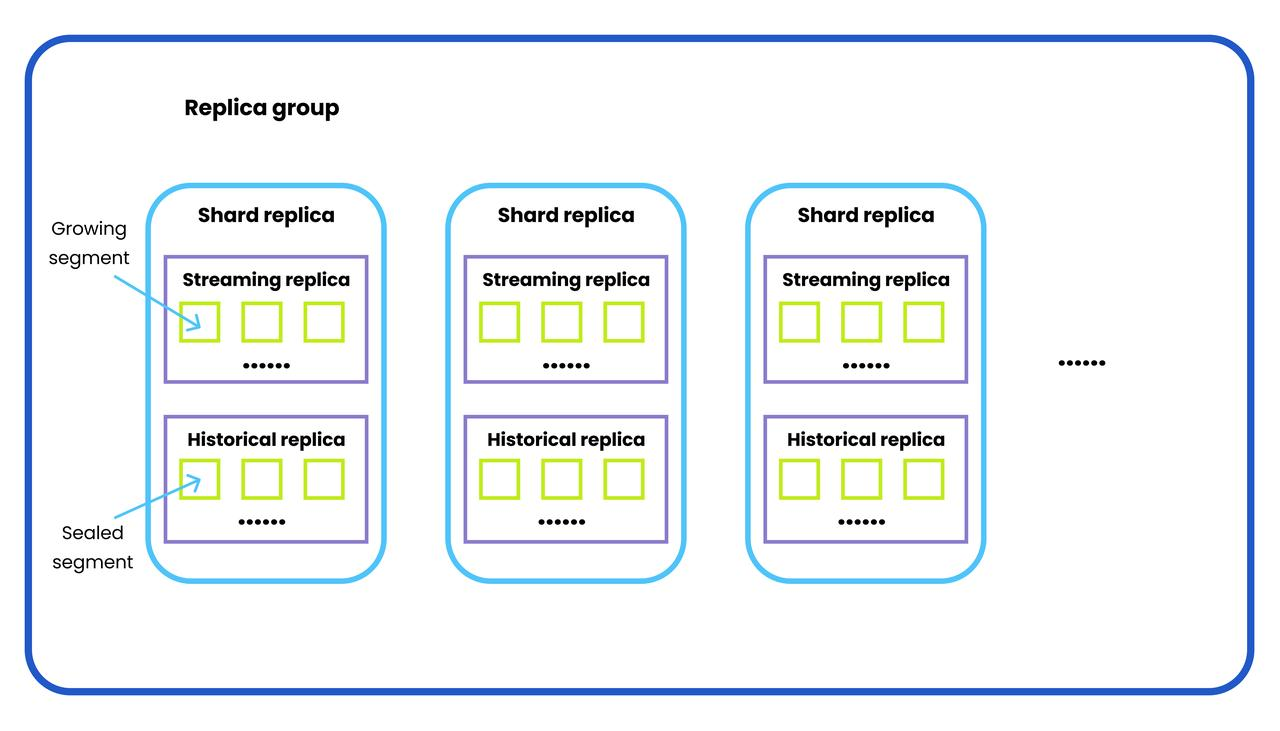
复制组
副本组由负责处理历史数据和副本的多个查询节点组成。更具体地说,Milvus向量数据库中的查询节点检索增量日志数据,并通过订阅日志代理、从对象存储中加载历史数据以及在向量和标量数据之间运行混合搜索,将其转化为不断增长的段。
碎片复制品
分片副本由流副本和历史副本组成,两者都属于同一分片(即数据操作语言通道,在Milvus中缩写为DML通道)。多个碎片副本组成一个副本组。副本组中的碎片副本的确切数量由指定集合中的碎片数量确定。
流副本
流副本包含来自同一DML通道的所有增长段。不断增长的段继续接收新插入的数据,直到其被密封。从技术上讲,一个流副本只能由一个副本中的一个查询节点提供服务。
历史复制品
历史副本包含来自同一DML通道的所有密封段。密封段不再接收任何新数据,并将刷新到对象存储中,留下新数据插入新创建的增长段。一个历史副本的密封段可以分布在同一副本组内的多个查询节点上。
碎片领导者
分片领导者是服务于分片副本中的流副本的查询节点。
什么是内存副本?
启用内存中副本允许您在多个查询节点上加载集合中的数据,以便您可以利用额外的CPU和内存资源。换句话说,当您在集合中加载数据并指定要将其作为两个副本加载时,最终将在两个查询节点上拥有两个数据副本。如果您的数据集相对较小,但希望提高读取吞吐量并提高硬件资源的利用率,则内存中副本的功能非常有用。
默认情况下,Milvus矢量数据库目前在内存中为每个段保存一个副本。但是,使用内存副本,您可以在不同的查询节点上对一个段进行多个复制。这意味着,如果一个查询节点正在对某个段进行搜索,则可以将传入的新搜索请求分配给另一个空闲查询节点,因为该查询节点具有完全相同的段的复制。好处是您完全不必再次重新加载数据。您无需执行任何操作,空闲查询节点会自动执行搜索或查询,因为该查询节点已经复制并接收了数据。
此外,如果我们有多个内存副本,我们可以更好地处理查询节点崩溃的情况。如果没有内存中的副本,我们必须等待重新加载段,以便继续在另一个查询节点上搜索。但是,通过内存复制,搜索请求可以立即重新发送到新的查询节点,而无需再次重新加载数据,如下图所示。

为什么内存副本很重要?
启用内存中副本的最大好处之一是提高了总体QPS(每秒查询)和吞吐量。如果在使用Milvus vector数据库时启用了内存副本,您将能够看到系统性能的巨大飞跃。此外,使用内存中的副本,可以维护多个段副本,并且系统在故障转移时更具弹性,就像上面所示的示例一样。
在Milvus矢量数据库中启用内存中副本
在Milvus vector数据库中,启用内存副本的新功能非常简单。您只需在加载集合时指定所需的副本数量(即调用collection.load())。
在下面的教程中,我们将使用包含图书信息的集合示例。我们假设您已经创建了一个名为“book”的集合,并将数据插入其中。然后,您可以指定加载集合数据时要创建的副本数。下面的示例代码将集合作为两个副本加载。
from pymilvus import Collection
collection = Collection("book") # Get an existing collection.
collection.load(replica_number=2) # load collection as 2 replicas
您可以灵活地修改上面示例代码中的副本数量,以最适合您的应用程序场景。然后,您可以直接在多个副本上执行向量相似性搜索或查询,而无需运行任何额外的命令。但是,应该注意,允许的最大副本数受到运行查询节点的可用内存总量的限制。如果指定的副本数量超过可用内存的限制,则在数据加载期间将返回错误。
您还可以检查通过运行collection.get_replicas()创建的内存中副本的信息。将返回副本组的信息以及相应的查询节点和碎片。以下是输出的示例。
Replica groups:
- Group: <group_id:435309823872729305>, <group_nodes:(21, 20)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:21>, <shard_nodes:[21]>, Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:20>, <shard_nodes:[20, 21]>]>
- Group: <group_id:435309823872729304>, <group_nodes:(25,)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:25>, <shard_nodes:[25]>, Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:25>, <shard_nodes:[25]>]>
原文标题:Increase Your Vector Database Read Throughput with In-Memory Replicas
原文作者:Angela Ni
原文链接:https://dzone.com/articles/increase-your-vector-database-read-throughput-with
