




介绍
大数据的来源之一是传统的应用程序管理系统或使用 RDBMS 的应用程序与关系数据库的交互。这种 RDBMS 生成的大数据保存在关系数据库服务器的关系数据库结构中。
Hadoop 生态系统的大数据存储和分析,如 MapReduce、Hive、HBase、Cassandra、Pig 等,需要一个工具来与关系数据库服务器通信,以导入和导出存储在其中的大数据。Sqoop 是 Hadoop 生态系统的一个元素,它促进了关系数据库服务器和 Hadoop 的 HDFS 之间的交互。
“SQL 到 Hadoop,Hadoop 到 SQL”是 Sqoop 的定义。
Sqoop 是一种用于在关系数据库服务器和 Hadoop 之间移动数据的技术。它用于将 MySQL 和 Oracle 等关系数据库中的数据导入 Hadoop HDFS,并将数据从 Hadoop 文件系统导出到关系数据库。Apache 软件基金会提供它。
Apache Sqoop 是如何工作的?
在这篇文章中,我将说明如何借助简单的 Sqoop 架构来实现这一点。为方便起见,下面是简化的 Sqoop 架构图。
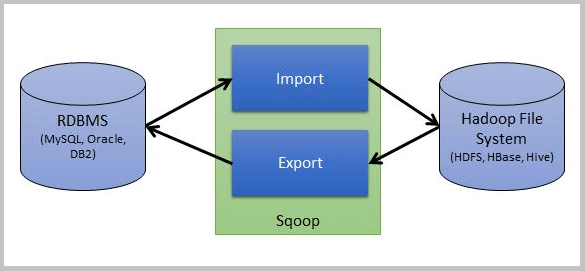
如图所示,一个源是 MySQL 等 RDBMS,另一个是 HBase 或 HDFS 等目标,Sqoop 处理导入和导出操作。
Apache Sqoop 面试问题
1. 使用 Apache Sqoop 的显着优势是什么?
下面列出了使用 Apache Sqoop 的主要好处:
- 支持并行数据传输和容错——Sqoop 使用 Hadoop YARN(Yet Another Resource Negotiator)架构进行并发数据导入和导出过程。YARN 还提供了容错能力。
- 只导入必要的数据——Apache Sqoop 只导入必要的数据。它从数据库表中导入由 SQL 查询生成的行子集。
- 支持所有主要的RDBMS- Sqoop 支持所有主要的RDBMS 连接到HDFS,包括MySQL、Postgres、Oracle RDB、SQLite 等。当涉及到RDBMS 时,数据库需要JDBC(Java 数据库连接)和支持JDBC 的连接器。因为它支持整个加载表,所以数据可以直接导入 Hive/HBase/HDFS。使用增量加载功能,可以在修改表的其余部分时加载它们。
- 直接将数据加载到 Hive/HBase/HDFS - Apache Sqoop 将数据从 RDBMS 数据库导入 Hive、HBase 或 HDFS 进行分析。HBase 是一个 NoSQL 数据库。但是,Sqoop 可以将数据导入其中。
- 用于数据加载的单个命令——Sqoop 提供了一个用于将所有表从 RDBMS 数据库加载到 Hadoop 的命令。
- 鼓励压缩- Sqoop 包括 deflate (gzip) 算法和 -compress 参数来压缩数据。使用 -compression-codec 参数,我们可以缩短表并将它们放入 Hive。
- 支持 Kerberos 集成安全性- Sqoop 也支持 Kerberos 安全性身份验证。Kerberos 是一种用于计算机网络的身份验证系统,它使用“票证”来允许节点在非安全点之间进行安全通信,以确认彼此的身份。
2、Eval工具的作用是什么?
Sqoop Eval 将帮助您使用示例 SQL 查询。这可以针对数据库执行,因为可以在控制台上预览结果。有趣的是,使用 Eval 工具,您将能够确定是否可以准确导入所需的数据。
3. Apache Sqoop 用于导入数据的默认文件格式是什么?
Sqoop 使用两种文件格式,便于数据导入。类似:
i) 分隔文本文件格式
这是用于使用 Sqoop 导入数据的默认文件格式。此外,可以使用 –as-textfile 参数为 Sqoop 导入命令显式选择此文件类型。同样,提供此参数将生成输出文件中所有记录的基于字符串的表示,并带有分隔的行和列。
ii) 序列文件格式
序列文件格式可以描述为二进制文件格式。他们的记录保存在特定于记录的自定义数据类型中,这些数据类型显示为 Java 类。此外,Sqoop 构建这些数据类型并自动将它们呈现为 Java 类。
4. 在 Sqoop 中,如何从特定的列或行导入数据?
Sqoop 使用户能够根据 WHERE 子句导出和导入数据。
句法:
-columns -where -query
5. 列出基本的 Apache Sqoop 命令及其各自的应用程序。
Apache Sqoop 的基本控件及其功能如下:
- 导出:此功能允许将 HDFS 目录导出为数据库表。
- 列出表:此功能将帮助用户列出某个数据库中的所有表。
- Codegen:此方法将允许您开发用于与各种数据库记录交互的代码。
- 创建:此功能允许用户将表定义导入数据库配置单元。
- Eval:此功能将始终帮助您评估 SQL 语句并显示结果。
- 版本:此功能将帮助您显示与数据库文本相关的信息。
- 导入所有表:此功能帮助用户将所有表从数据库导入到 HDFS。
- 列出所有数据库:此方法将允许用户生成特定服务器上所有数据库的列表。
6、sqoop配置中JDBC驱动的作用是什么?JDBC 驱动程序是否足以将 sqoop 链接到数据库?
Sqoop 需要一个连接器来链接各种关系数据库。Sqoop 需要数据库的 JDBC 驱动程序与之交互。几乎所有数据库制造商都为其数据库提供唯一的 JDBC 连接器。不,Sqoop 需要 JDBC 和连接器才能连接到数据库。
7. 有没有办法将 Sqoop 包含到 Java 程序中?
要在 Java 程序中使用 Sqoop,Sqoop jar 必须包含在类路径中。如果我们想在 Java 应用程序中使用 Sqoop,我们必须以编程方式定义每个参数。在这一步之后必须调用 Sqoop.runTool() 方法。
8、sqoop函数使用的mapper数量如何控制?
–num-mappers用于调节 sqoop 命令运行的映射器的数量。此外,我们应该从选择有限数量的地图作业开始,然后逐渐成长,因为一开始就选择大量的地图作业可能会影响数据库性能。
9. Apache Sqoop 与 Flume 的比较。
答。因此,让我们根据各自的特点来探讨所有的区别。
一个。数据流
Sqoop 与任何具有基本 JDBC 连接的关系数据库管理系统 (RDBMS) 兼容。此外,Sqoop 可以从 MongoDB 和 Cassandra 等 NoSQL 数据库中导入数据。此外,它还支持将数据传输到 Apache Hive 和 HDFS。
同样,Apache Flume 使用在 Hadoop 系统中不断创建的流数据源。像日志文件。
湾。 装载类型
Apache Sqoop – Sqoop 负载主要不是由事件驱动。
Apache Flume——在这种情况下,数据加载完全是事件驱动的。
C。何时使用
Apache Sqoop — 但是,如果数据存储在 Teradata、Oracle、MySQL、PostgreSQL 或任何其他 JDBC 兼容的数据库中,则非常适合。
Apache Flume – 它是从 JMS 或假脱机目录等源移动大部分流数据的最佳选择。
d。链接到 HDFS
Apache Flume – 通常,Apache Flume 数据通过通道进入 HDFS。
Apache Flume – 数据通常使用 Apache Flume 中的通道传输到 HDFS。
e. 建筑学
Apache Sqoop——它的架构建立在连接器之上。但是,这意味着连接器精通与众多数据源的交互。同样,必须检索数据。
另一方面,Apache Flume 具有基于代理的架构。从本质上讲,这意味着在 Flume 中开发的代码被称为代理,它负责获取数据。
10. 描述当今使用 Sqoop 的优势。
Apache Sqoop 被认为是对从数据仓库驱动数据有困难的人的有用资源。此外,它还用于将数据从 RDBMS 导入 HDFS。用户可以使用 Sqoop 导入多个表。有趣的是,Apache Sqoop 使得导出数据选择的列变得简单。此外,Sqoop 兼容绝大多数 JDBC 数据库。这是一组可以帮助您通过 Sqoop 筛选的面试问题。
结论
本文提供有关 Sqoop 和大数据的信息。基本上,Sqoop 是一个支持关系数据库服务器和 HDFS 之间通信的 Hadoop 生态系统元素。我们希望这些问题可以帮助您为即将到来的面试做准备。不过,如果您对 Sqoop 面试问题有任何疑问,请随时提出。此外,我们还看到了以下内容:
使用 Apache Sqoop 有多大好处?
Sqoop 是如何运作的?
基本命令及其各自的功能
Sqoop、RDBMS 和 Hadoop 系统如何相互链接等等?
原文标题:Top Interview Questions & Answers for Apache Sqoop
原文作者:Prashant Sharma
原文链接:https://www.analyticsvidhya.com/blog/2022/07/top-interview-questions-answers-for-apache-sqoop/
