




数据管道的基础是一系列数据处理措施,用于自动化系统或数据存储之间的数据传输和转换。数据管道可用于企业中的广泛用例,包括为推荐目的或客户关系管理而聚集客户数据,组合和转换来自多个来源的数据,以及整理/流式传输来自传感器或事务的实时数据。
例如,像Airbnb这样的公司可以在其应用程序和其选择的平台之间建立数据管道,以改善客户服务。Netflix利用了一个推荐数据管道,该管道自动化了生成电影和系列推荐的数据科学步骤。此外,根据其更新的速率,可以使用批处理或流式数据管道为利益相关者生成和更新分析仪表板中使用的数据。
在本文中,您将学习如何实现一个数据管道,该管道利用Kafka将来自多个源的数据聚合到QuestDB数据库中。具体而言,您将看到流式数据管道的实现,该管道将CoinCap的加密货币市场价格数据整理到QuestDB实例中,在该实例中可以制作度量、分析和其他仪表板。
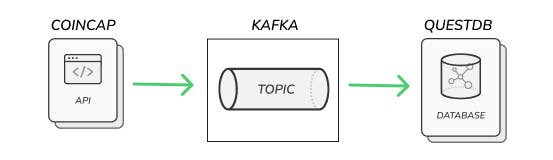
使用Kafka和QuestDB的数据管道
数据管道由数据源(例如,应用程序、数据库或web服务)、处理或转换过程(例如,移动或修改数据的动作,彼此并行或顺序发生)和目的地(例如,另一个应用程序、存储库或web服务)组成。
正在移动或转换的数据的类型或格式、数据的大小以及移动或转换数据的速率(批处理或流处理)是构建数据管道时需要注意的一些其他因素。每月只需触发一次的数据管道与处理应用程序实时通知的数据管道不同。
ApacheKafka是一个开源的分布式事件平台,优化用于实时处理和修改流数据。它是一个快速且可扩展的选项,用于创建高性能、低延迟的数据管道,并为来自多个源的大容量流数据的数据集成构建功能。卡夫卡是一种相当流行的工具,被数千家公司使用。
QuestDB是一个高性能、开源的SQL数据库,旨在轻松快速地处理时间序列数据。它是一个面向关系列的数据库,应用于物联网、传感器数据和可观测性、金融服务和机器学习等领域。数据库的功能是用Java编写的,支持REST API,支持PostgreSQL wire协议和InfluxDB line协议,允许以多种方式获取和查询QuestDB中的数据。
准备
QuestDB可以使用Docker、TAR文件或包管理器(如Homebrew)安装。Confluent提供了一个Kafka发行版的ConfluentPlatform,其中的插件可以简化您的数据管道流程,并可以使用Docker镜像或其下载的TAR文件进行安装。
注意:Confluent平台与Apache Kafka是分开许可的。如果希望在生产环境中使用此设置,请确保通读Confluent Platform许可证。
至于市场数据,您可以利用CoinCap API来整理ETH市场数据。但也存在其他流式金融数据资源。
本文中使用的所有文件都可以在GitHub存储库中找到。您可以克隆存储库以直接完成以下步骤:
git clone https://github.com/Soot3/coincap_kafka_questdb.git
安装QuestDB和Kafka
在本文中,您可以使用Docker Compose文件安装这两个文件,该文件为Kafka和QuestDB管道创建所需的Docker容器:
---
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:7.0.1
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: "true"
CONFLUENT_SUPPORT_CUSTOMER_ID: "anonymous"kafka-connect:
image: yitaekhwang/cp-kafka-connect-postgres:6.1.0
hostname: connect
container_name: connect
depends_on:
- broker
- zookeeper
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: "broker:29092"
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverterquestdb:
image: questdb/questdb:latest
pull_policy: always
hostname: questdb
container_name: questdb
ports:
- "9000:9000"
- "8812:8812"
按照顺序,此Docker Compose文件将安装合流的托管卡夫卡工具、Zookeeper和卡夫卡代理,它们管理卡夫卡生态系统中的连接和进程。然后,它将安装一个JDBC连接器,该连接器将启用Kafka与任何关系数据库(如QuestDB)之间的连接。该特定JDBC连接器映像是一个自定义连接器,用于简化Confluent的Kafka服务与Postgres数据库之间的连接。
您可以通过移动到Docker目录,然后运行Docker Compose文件来设置Kafka和QuestDB:
cd coincap_kafka_questdb/docker docker-compose up -d
安装过程应该需要几分钟。您可以使用docker compose ps检查服务是否正常运行。一旦您看到连接容器状态正常,您的集群就可以运行了。
连接Kafka和QuestDB
此时,您的Kafka集群和QuestDB实例仍然未连接,无法在它们之间传递数据。使用已安装的连接器,可以通过设置连接器的配置设置来创建此连接:
{
"name": "postgres-sink-eth",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "topic_ETH",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"connection.url": "jdbc:postgresql://questdb:8812/qdb?useSSL=false",
"connection.user": "admin",
"connection.password": "quest",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "true",
"auto.create": "false",
"insert.mode": "insert",
"pk.mode": "none"
}
}
在这里,您将设置连接监视的一个或多个主题、消息条目的格式以及连接的身份验证详细信息。然后,默认情况下,QuestDB接受admin和quest作为用户和密码。
您可以使用以下命令将此配置发送到已安装的连接器:
curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @postgres-sink-eth.json http://localhost:8083/connectors
成功执行后,您应该能够看到包含上述配置的JSON响应。
此时,您有一个已连接的QuestDB实例,该实例将监视topic_ETH主题,并提取发送给它的任何记录以存储在数据库中。然后可以为数据库中的记录创建一个表。
CREATE TABLE topic_ETH (`timestamp` timestamp, currency symbol, amount float)
这将为您的记录创建一个格式化表,下一步涉及生成将发送到此表的记录。
使用CoinCap API和Python生成市场数据
使用CoinCap的API和一些Python代码,您可以创建一个实时生成数据的Kafka生成器:
# importing packages
import time, json
import datetime as dt
import requests
from kafka import KafkaProducer# initializing Kafka Producer Client
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:
json.dumps(x,default=str).encode('utf-8'))print('Initialized Kafka producer at {}'.format(dt.datetime.utcnow()))# Creating a continuous loop to process the real-time data
while True:
# API request
uri = 'http://api.coincap.io/v2/assets/ethereum'
res = requests.request("GET",uri)start_time = time.time()
# Processing API response if successful
if (res.status_code==200):
# read json response
raw_data = json.loads(res.content)# add the schema for Kafka
data = {'schema': {
'type': 'struct',
'fields': [{'type': 'string', 'optional': False, 'field': 'currency'
}, {'type': 'float', 'optional': False, 'field': 'amount'
}, {'type': 'string', 'optional': False,
'field': 'timestamp'}],
'optional': False,
'name': 'Coincap',
}, 'payload': {'timestamp': dt.datetime.utcnow(),
'currency': raw_data['data']['id'],
'amount': float(raw_data['data']['priceUsd'])}}print('API request succeeded at time {0}'.format(dt.datetime.utcnow()))producer.send(topic="topic_ETH",value=data)print('Sent record to topic at time {}'.format(dt.datetime.utcnow()))else:
print('Failed API request at time {0}'.format(dt.datetime.utcnow()))end_time = time.time()
time_interval = end_time - start_time
# setting the API to be queried every 15 seconds
time.sleep(15 - time_interval)
这段Python代码在连续循环中查询CoinCap API,每15秒生成ETH的市场价格。然后,它处理这些数据并将其发送到Kafka主题topic_ETH,QuestDB可以在那里使用这些数据。这里使用的数据模式和有效负载只是一个示例,因为它没有使用一些QuestDB优化,例如分区。
您可以使用以下命令运行此代码:
# move back to the parent directory
cd ..
# Installing needed Python packages
pip install -r requirements.txt
# Run the python code
python producer.py
注意:如果您在使用需求安装依赖项时遇到问题。txt文件,特别是如果您遇到Microsoft Visual C++错误,请先检查Python版本。在编写本文时,合流的Kafka Python包支持Windows上的几个Python版本,特别是Python 3.7、3.8和3.9。如果您收到librdkafka/rdkafca错误。找不到h,您可以尝试按照GitHub问题的步骤进行操作。在我们使用Apple M1的特定情况下,我们通过执行
brew install librdkafka
export LIBRARY_PATH=/opt/homebrew/Cellar/librdkafka/1.8.2/lib
export C_INCLUDE_PATH=/opt/homebrew/Cellar/librdkafka/1.8.2/include
pip3 install -r requirements.txt
在producer脚本启动并运行后,您将每隔15秒整理ETH市场价格,这些数据将发送到您的卡夫卡主题。然后,您的QuestDB实例将使用监控的Kafka主题中的数据自动更新其数据库。有了这个数据管道和连接,QuestDB实例将每隔15秒填充一次数据。
尝试运行以下命令几次,以观察数据库在Kafka主题中的自我更新:
SELECT * FROM 'topic_ETH'
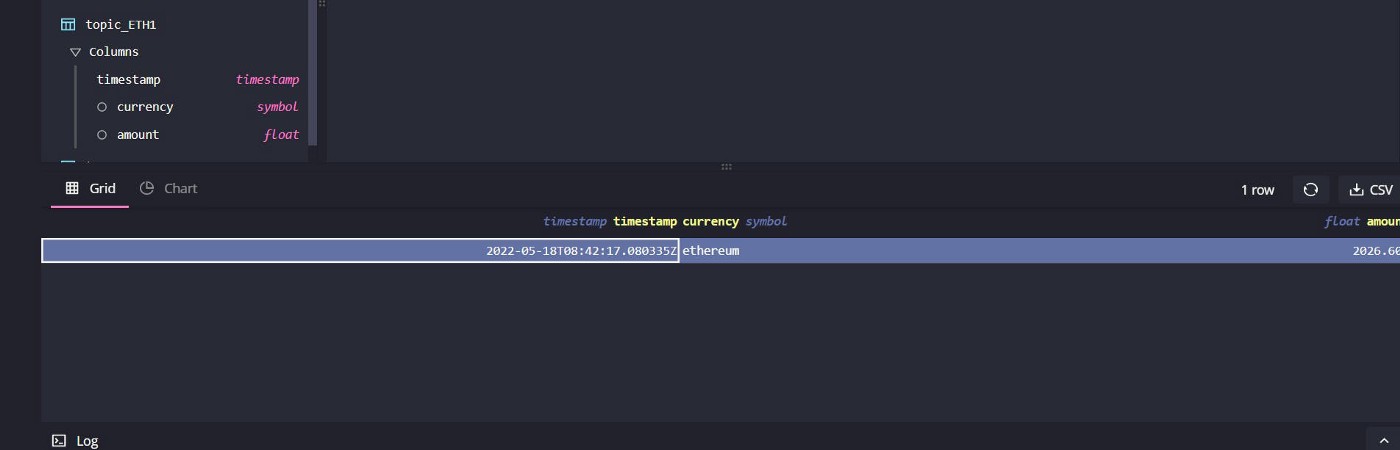
使用QuestDB实例上的数据,您可以查询或修改它,甚至生成更多记录发送到其他Kafka主题,从数据中创建物化视图和关键性能指标。
注意:要删除本文中使用的已安装容器,请移动到coincap_kafka_questdb/docker目录并运行以下命令:
docker-compose down
结论
数据管道是有效移动和转换数据以供使用的一个重要考虑因素。为了有效地整理原始数据,并将这些原始数据转化为有价值的见解,您需要数据管道。
在本文中,您学习了如何使用Kafka整理数据,并实现一个数据管道,该管道收集实时ETH市场数据,并通过Kafka连接将数据存储到QuestDB。
QuestDB是一个开源SQL数据库,专注于快速性能和易用性。它是一种用于大容量时间序列数据的优化存储,无论是来自您的金融服务还是传感器应用程序,在这些应用程序中不断生成时间序列数据。它满足了对高性能摄取和查询时间的需求。与Kafka结合使用,您可以聚合来自多个源的数据,修改它们,并以适合最终用户或应用程序的持续更新速率存储它们以供使用。
原文标题:Building a Data Pipeline Using QuestDB and Confluent Kafka
原文作者:Sooter Saalu
原文链接:https://dzone.com/articles/building-a-data-pipeline-using-questdb-and-conflue
