





论文地址: ACM (https://dl.acm.org/doi/abs/10.1145/3394486.3403333)
1. 写在前面
许多观众和影评人会对某个导演的电影情有独钟,即使他们曾经拍过烂片,观众待他们依然如初恋,比如拍出了《阳光灿烂的日子》的姜文。
对于 Airbnb 的论文,我也抱有同样的感情。何况从 KDD'18 的最佳论文,到这两年他们将深度学习应用于搜索实践的两篇论文,篇篇佳作,字字珠玑。
本文是 Airbnb 发表于 KDD'20 的论文,是前一篇《Applying Deep Learning to Airbnb Search》的续作,讲述了他们在搜索排序模型迭代方面的尝试。第二节写得尤其好,为科学炼丹做出了良好示范!
本文,我们以论文的第二节为范本,来看看他们是如何做数据分析、如何做模型迭代的。保证原汁原味!(全文约3500字,阅读时长约 20 分钟)
前两篇论文的笔记在这里,诸位同道不妨先看一看,特别是一脉相承的《Applying Deep Learning to Airbnb Search》:
【Papernotes】(KDD'19) Applying Deep Learning to Airbnb Search
【Papernotes】(KDD'18) Real-time Personalization using Embeddings for Search Ranking at Airbnb
2. 模型优化
在正式开始之前,我们先来看一下他们的基线模型,一个双隐层的神经网络:
输入的特征是房源(listing)的基本特征,如价格、历史预订数等,以及一些类别特征的 embeddings;
两个隐藏层分别是 127 维、83 维的全连接层,使用 ReLU 作为激活函数。
这是他们上一个工作1的结论之一:加深模型对于 CNN 这样的模型是有效的优化手段,但是对于他们的场景(搜索排序),模型容量并不是问题,两个隐藏层已经足够了。
既然加深网络不是模型迭代的方向,他们开始尝试一些专用的网络架构,比如 Deep&Wide2、基于注意力机制的网络3等等。但是都失败了。
这里,他们失败的教训与洞见是:特定深度模型的成功应用,与具体业务、产品是高度绑定的。简单的拿来主义——只看到一个模型的成功,却看不到它解决了基线模型的哪些痛点——是危险的。深度学习欠解释的特点,使得理解一个模型究竟解决什么困难、又是如何解决的,变得更加困难。这又使得深度模型的迁移应用变得更加困难。
于是,他们放弃了论文驱动的模型迭代方式(下载论文->复现模型->A/B测试),坚持第一性原理,从用户第一的核心价值观出发,对模型进行迭代优化。
所谓用户第一的模型迭代方式,就是发现并量化用户的问题,以解决用户的问题为目标,迭代模型。
他们上一个工作的结果是:房源的预订率上去了,但是搜索结果的平均价格下降了。这说明,之前的模型迭代工作使得模型越来越懂用户的价格偏好了。
怀疑此间仍有优化的空间,于是他们分析了房源价格对用户预订决策的影响。如下图所示,X 轴是预订价格与搜索结果的价格中位数(以下简称价格中位数)的对数差,Y 轴是用户数。他们期望,用户数对价格差,状似正态分布:相对于价格中位数,用户偶尔出价更高,偶尔更低,总的来说,是一个对称的分布。但事实是,它是一个明显的偏态分布。这意味着,用户的平均出价低于价格中位数,也就是,用户偏好价格更低的房源,Cheaper Is Better。
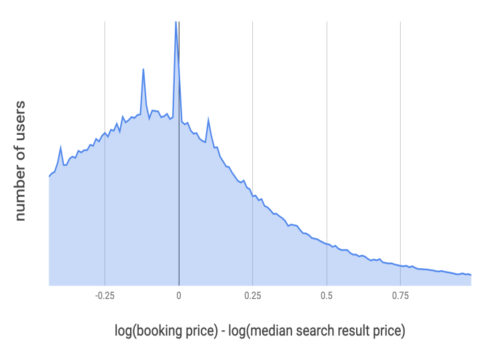
其后是几次将 Cheaper Is Better 注入模型的尝试。来简单看一下他们是如何做的,又是如何总结失败,并最终成功的。
2.1 第一次尝试
第一次尝试,他们将房源的价格从输入特征中抽离了出来,得到一个独独对价格无感的模型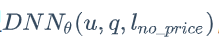 ,其中,u、q、l分别是用户、查询关键字(以下简称query)、房源的特征。
,其中,u、q、l分别是用户、查询关键字(以下简称query)、房源的特征。
然后将模型最终的输出建模为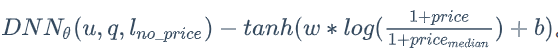 。
。
对数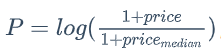 ,对价格是一个单调递增的函数。并且,当一个房源的价格小于价格中位数时,对数结果是一个负值;反之,对数结果是正值。Tanh 同样是一个单调递增的函数,因此 -tanh 将使得模型输出对价格单调递减。
,对价格是一个单调递增的函数。并且,当一个房源的价格小于价格中位数时,对数结果是一个负值;反之,对数结果是正值。Tanh 同样是一个单调递增的函数,因此 -tanh 将使得模型输出对价格单调递减。
线上 A/B 测试,与基线相比,该模型的搜索平均价格下降了 5.7%,效果显著。但是,降价并没有带来预订率的提高,反而下降了 1.5%。
对此,一个说得通的解释是:价格与房源的其他特征是深度耦合的,将其独立出来会使得模型欠拟合。训练集与测试集上的 NDCG 的下降证明了这一点。
2.2 第二次尝试
第二次尝试,他们使用了一个 lattice network (实在不知道这种网络的中文名),既保证价格与其他特征的交互,又保持了 Cheaper Is Better。模型结构如下。
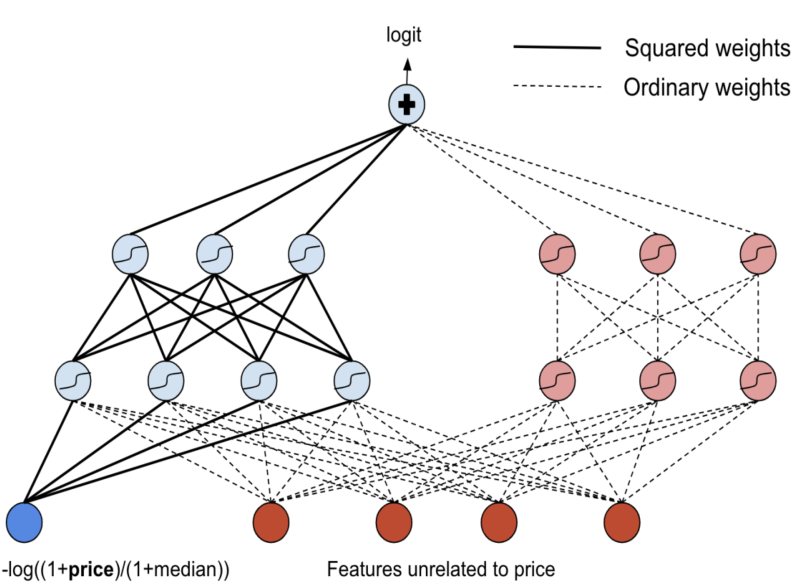
如图例所示,虚线表示正常的权重,实线表示平方的权重。隐藏层全部使用 tanh 作为激活函数。
于是,左半网络保证了价格与其他特征的交互,并保持了模型输出对价格的单调递减:
-P 对价格是单调递减的 -> 平方的权重和 tanh,即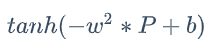 保证了输入层对价格是单调递减的 -> 隐藏层与输出层采取相同的做法,因此也保证了对价格的单调递减。
保证了输入层对价格是单调递减的 -> 隐藏层与输出层采取相同的做法,因此也保证了对价格的单调递减。
右半网络不以价格为输入且没有单调性限制,保证了除价格外所有特征的自然交互。
乍看之下,该模型简直太优雅了!然而,线上的预订率依然下降了 1.6%。
由此,Airbnb 得出结论:对价格的单调性是一个太严苛的约束,以致于模型总是欠拟合的。
这里有一个对深度模型的比喻,很有意思:
深度神经网络就像团队里的明星工程师。给定一个问题,而不加任何限制,它们通常能给出一个合理的解。但是约束它们往某个方向求解时,灾难就如影随形了。
2.3 第三次尝试
第三次不再硬性要求模型输出对价格的单调性了,而是加了一个软约束。具体地,在既有的 pairwise loss(记作 booking loss,预订损失)基础上,加入了一个引入价格信息的辅助损失函数 price loss(价格损失)。

通过调整超参数 alpha,他们将新模型在测试集上的 NDCG 调整为与基线一致。此举的意图在于:在不损失相关性的前提下,强调价格的影响。
然而,线上 A/B 测试的结果未达预期:搜索结果的均价降了 3.3%,预订率下降了 0.67%。原因在于线上线下数据的 diff:线下训练时,模型仅对日志中有记录的 TOP 结果进行了重排;在线上,模型面对的是全体召回(或粗排)的房源,price loss 的真实影响与线下有所不同。
2.4 第四次尝试
经历过三次失败,他们回到了问题的原点:新模型全都不及基线,那么基线是如何利用价格信息的呢?
对于深度学习而言,以上问题很难回答:第一次尝试已经揭示了房源的其他特征与价格是高度耦合的,因此难以确定模型对价格的偏依赖程度,也就难以确定价格对模型的影响。
这一次,他们对问题进行了简化,并不尝试解释价格对模型的影响,而是专注于理解每一次的搜索结果。借助 Individual Conditional Expectation (ICE) 的思想,他们将每一次(基线的)搜索结果的房源拎出来,绘制了房源的排序得分-价格的关系图,如下图所示。
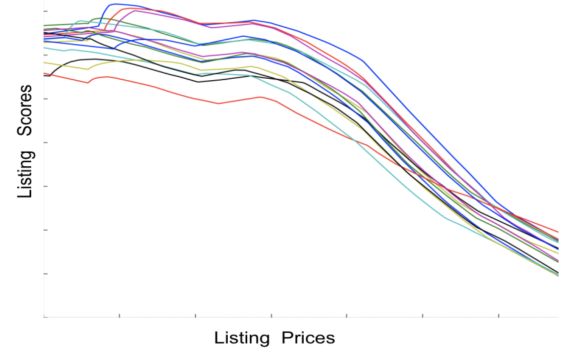
可以看到,房源的排序得分与价格几乎是单调递减的关系。这说明,Cheaper Is Better 已经反映在基线模型中了。
前几次压低价格的尝试,实际上以损害搜索质量为代价换取了更低的搜索均价。
那么,该如何正确地理解图 1 反映的“用户对低价房源的偏好”呢?答案在于城市。
下图反映了不同城市,用户预订价格与价格中位数的差异。可以看到,价格差异在不同城市之间具有明显的分化:在代表成熟市场的头部城市,比如洛杉矶(Los Angeles)、旧金山(San Francisco),价格差异很小;在代表新兴市场的长尾城市,比如北京、Santiago(智利首都,圣地亚哥),价格差异就非常大。
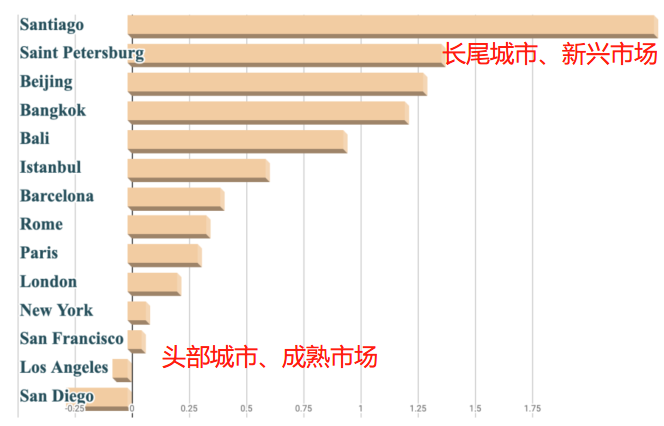
这为图 1 的现象提供了一重解释:模型对头部城市过拟合了,过拟合的模型无法很好地泛化应用于长尾城市。
与以上假设相契合的另一个现象是:使用 pairwise loss 训练模型,两个房源差异更大的特征对模型的影响也更大。不同城市的房源的特征差异大,这继续加大了模型泛化的难度。相反,query 之间的差异并不大,对模型的影响也很小。
于是,第四次尝试的目标就从关注 Cheaper Is Better调整为了为旅程找到合适的定价,the Right Price for a Trip。
他们选择了一个双塔结构,第一座塔的输入为 query 与用户特征,输出 100 维的向量,表征 query-用户组合的理想房源;第二座塔的输入为房源特征,输出 100 维的向量,表征当前房源;用欧式距离表征当前房源与理想房源的差距。
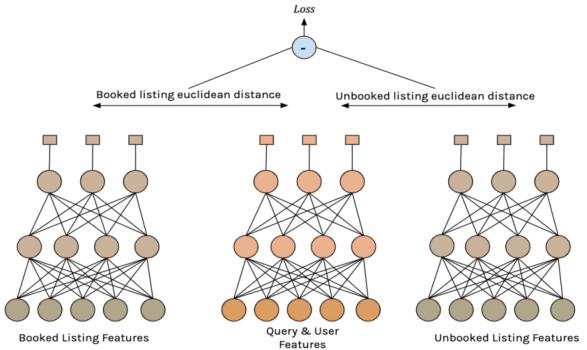
如上图所示,模型看起来像一个三塔结构。事实上,训练的样本依然是房源对:一个预订的房源和一个未预订的房源,而两个房源由同一座塔进行处理。
双塔模型的 A/B 测试显示,线上 NDCG 提高了 0.7%,而由于搜索相关性的提升,预订率提高了 0.6%。相关性提高的另一个效果是,搜索均价下降了 2.3%,说明模型更加准确地捕捉到了用户对价格的偏好。
与基线相比,双塔模型的另一个优点在于:能够减小排序计算的开销。对于基线模型而言,第一个隐藏层的计算开销最大,计算复杂度为 ,此处 N、H、Q、L 分别表示参与排序的房源数、隐藏层的大小、query 与用户特征数、房源特征数。采用双塔结构之后,由于 query-用户塔只需要做一次计算(需要工程方面的优化),第一个隐藏层的计算复杂度减小为
,此处 N、H、Q、L 分别表示参与排序的房源数、隐藏层的大小、query 与用户特征数、房源特征数。采用双塔结构之后,由于 query-用户塔只需要做一次计算(需要工程方面的优化),第一个隐藏层的计算复杂度减小为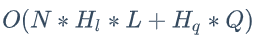 ,
,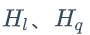 分别表示两座塔的隐藏层大小。排序的 TP99 减小了 33%。
分别表示两座塔的隐藏层大小。排序的 TP99 减小了 33%。
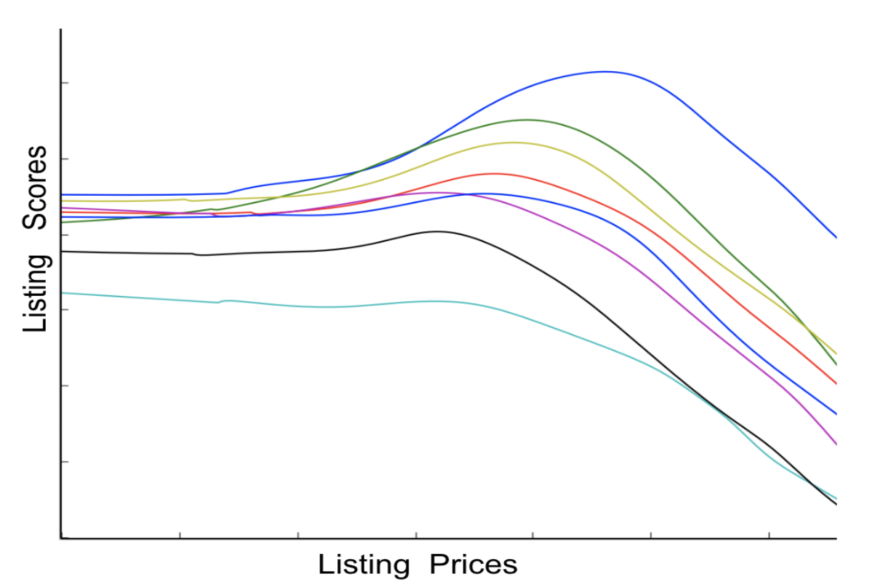
绘制双塔模型的 ICE 曲线,如上所示。与图 4 呈现的单调向下的曲线不同,此时,排序得分对于一定区间的价格是平稳的;对另一区间的价格,随着价格的提高,排序得分甚至会先升再降。
排序得分的尖峰,意味着模型为用户找到的合适的定价(the Right Price for a Trip),而不是只强调低价优先。而单调向下的曲线的继续存在,说明模型依然能够捕捉用户的低价偏好。
写在后面
从 Airbnb 的模型优化工作,可以看到,模型的迭代优化绝非一蹴而就的,需要坚实的数据分析工作、以及不断的不断的求索。如果一开始找错了方向,问题会变得更加困难,甚至不可解。
我个人的一点收获是:模型优化也需要第一性原理。优化的目标是什么、基线的不足在哪里,在优化的过程中,需要不断地回过头来审视这两个问题,必要时重新出发。
论文的剩余部分介绍了他们对于冷启动的优化、以及如何剔除位置偏差的工作。我自己的工作尚未涉及这两方面,以后有机会再聊吧。
祝,新年快乐、升职加薪!
参考文献
[1] Applying Deep Learning to Airbnb Search.
[2] Wide & Deep Learning for Recommender Systems.
[3] Attention is All you Need.
