




介绍
SQL 代表结构化查询语言。它是一种用于交互/查询和管理 RDBMS(关系数据库管理系统)的编程语言。SQL 技能是高度首选和必需的,因为许多组织在各种软件应用程序中使用它。
因此,作为一个新人或经验丰富的候选人,如果您计划参加即将到来的SQL 面试,您需要确保为各种概念性、理论性和编码 SQL 问题做好充分准备。本文包含 20 个基于场景的实时 SQL 编码面试问题,这些问题将帮助您测试您的 SQL 技能并增强您的信心。
注意 –此处使用的所有 SQL 查询都与 Oracle 数据库版本(如 11g、12c、18c 等)兼容。
SQL 编码面试题
考虑如下所示的 学生表作为问题编号。1、2 和 3。
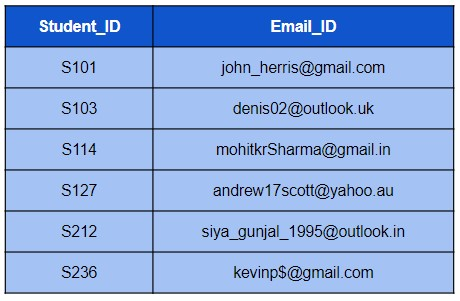
Q1。编写查询以从 Email_ID 列中提取用户名(@ 符号之前的字符)。
Answer:
SELECT SUBSTR(Email_ID, 1, INSTR(Email_ID, '@') - 1) FROM STUDENT;
首先使用 INSTR() 函数从电子邮件 ID 中提取 @ 的位置,然后将此位置(减去 1 后)作为长度参数传递给SUBSTR() 函数。
Output -
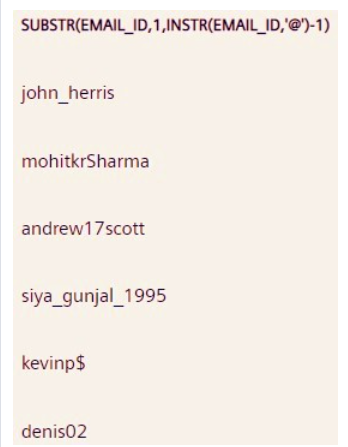
Q2。编写查询以从 Email_ID 列中提取 .com、.in、.au 等域名。
Answer:
SELECT SUBSTR(Email_ID, INSTR(Email_ID, '.')) FROM STUDENT;
提取 的位置。(点字符)首先使用 INSTR() 函数从电子邮件 ID 中获取,然后将此位置作为参数传递给 SUBSTR() 函数中的起始位置。
Output -
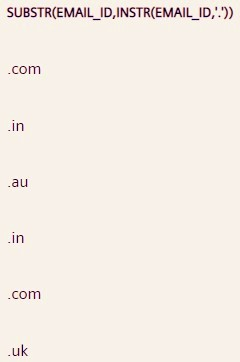
Q3。编写查询以从 Email_ID 列中提取电子邮件服务提供商名称,例如 google、yahoo、outlook 等。
Answer:
SELECT SUBSTR(Email_ID, INSTR(Email_ID, '@') + 1, INSTR(Email_ID, '.') - INSTR(Email_ID, '@') - 1) FROM STUDENT;
首先使用 INSTR() 函数从电子邮件 id 中提取 @ 的位置,并将其(在加 1 后)作为参数传递给 SUBSTR() 函数中的起始位置。
现在提取 的这个位置。(点字符)并从早先提取的 @ 位置中减去它,并将它(在减去 1 之后)作为SUBSTR() 函数中的长度参数传递。
Output -
Q4。以下查询的输出是什么?
SELECT CEIL(-12.43), FLOOR(-11.92) FROM DUAL;
a. -13, -12
b. -12, -12
c. -12, -11
d. -13, -11
答案:b
CEIL() 函数返回大于或等于给定数字的最小整数。因此,如果我们在 ceil 中传递 -12.43,它会返回 >= -12.43 即 -12 的最小整数值。
FLOOR() 函数返回小于或等于给定数字的最大整数。因此,如果我们在 floor 中传递 -11.92,它会返回 <= -11.92 即 -12 的最大整数值。
Output -

Q5。编写一个查询以提取您名字中出现的所有辅音。
Answer:
SELECT TRANSLATE('Narendra', 'xaeiou', 'x') FROM DUAL;首先,从上面提取的输入名称中提取辅音,然后将这些辅音与from_string参数中的字符“a”连接起来,通过在to_string参数中不指定相应字符来删除辅音。因此,如果我们在上述查询中将 Narendra 作为名称传递,它会返回元音 (a, e, a)。
Output -
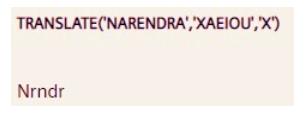
Q6。编写一个查询以提取您名字中的所有元音。
回答:
SELECT TRANSLATE('Narendra', 'a' || TRANSLATE('Narendra', 'xaeiou', 'x'), 'a') FROM DUAL; 首先,从上面提取的输入名称中提取辅音,然后将这些辅音与from_string参数中的字符“a”连接起来,通过在to_string参数中不指定相应字符来删除辅音。因此,如果我们在上述查询中将 Narendra 作为名称传递,它会返回元音 (a, e, a)。
Output -

有关问题编号,请参阅如下所示的emp表。7到14。
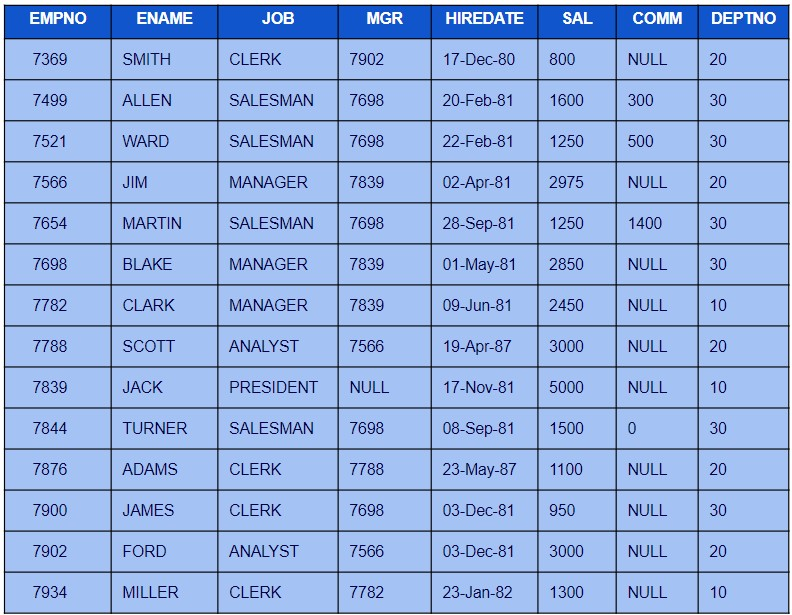
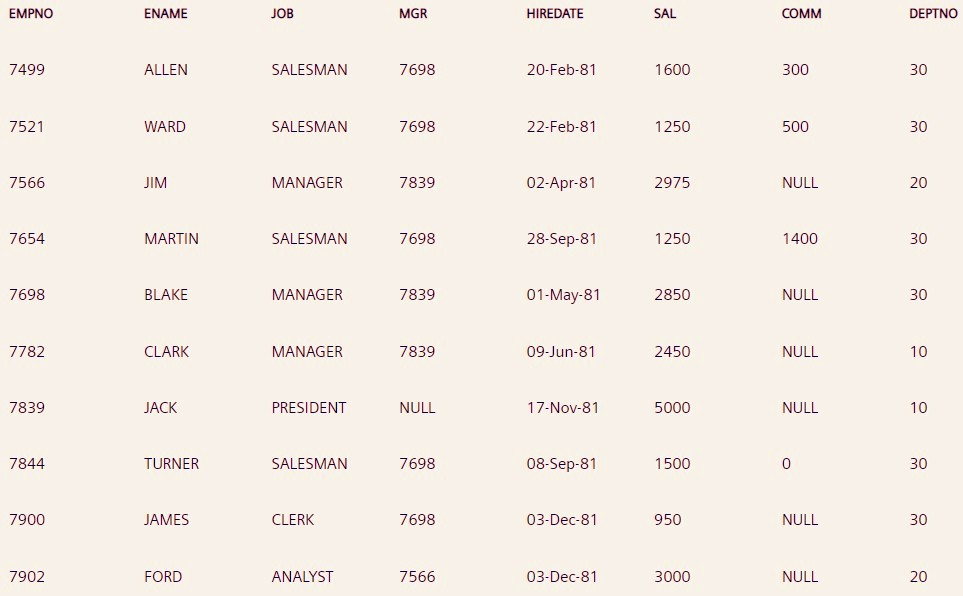
问题 7。编写查询以提取 1981 年加入的员工的详细信息。
Answer:
SELECT * FROM EMP WHERE TO_CHAR(HIREDATE, 'YY') = 81;
使用 TO_CHAR() 从hiredate 列中提取年份部分,并使用WHERE 子句选择1981 年雇用的所有员工。
Output -
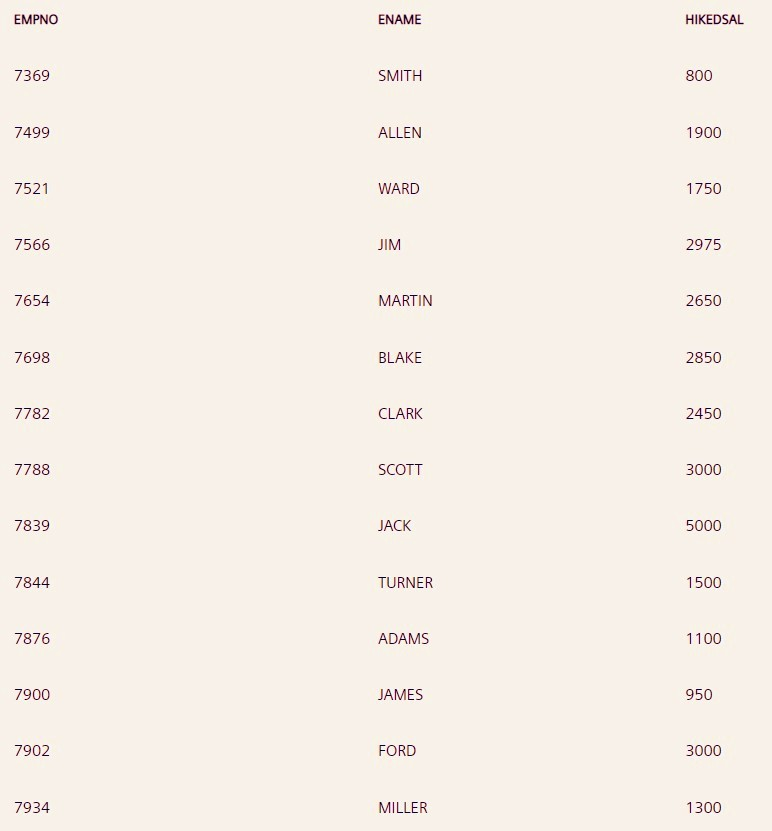
Q8。编写查询以查找添加佣金后每个员工的加薪工资。
Answer:
SELECT EMPNO, ENAME, NVL2(COMM, SAL+COMM, SAL) AS HIKEDSAL FROM EMP;
由于佣金列包含空值,因此直接将其添加到薪水将在佣金为空时返回空值。
使用 NVL2() 函数根据佣金是否为空来确定加薪。如果 COMM ( expr1 ) 不为 null,则返回 SAL+COMM ( expr2 )。如果 COMM 为空,则返回 SAL ( expr3 )。
Output -
问题 9。编写查询以找出比他们的经理获得更多薪水的员工。
Answer:
SELECT E.EMPNO, E.ENAME, E.SAL, M.EMPNO, M.ENAME, M.SAL FROM EMP E, EMP M WHERE E.MGR = M.EMPNO AND E.SAL > M.SAL;
自加入 emp 表,以比较员工的薪水和经理的薪水。
Output -

问题 10。编写查询以找出在经理之前加入组织的下属(被报告人)。
Answer:
SELECT E.EMPNO, E.ENAME, E.HIREDATE, M.EMPNO, M.ENAME, M.HIREDATE FROM EMP E, EMP M WHERE E.MGR = M.EMPNO AND E.HIREDATE < M.HIREDATE;
自行加入 emp 表,以比较员工的聘用率和经理的聘用率。
输出 -

问题 11。编写查询以找出没有任何下属(报告人)的员工,即不是经理的员工。
Answer:
SELECT * FROM EMP WHERE EMPNO NOT IN (SELECT DISTINCT NVL(MGR, 0) FROM EMP);
使用简单子查询首先找出不同的管理者 EMPNO 的列表,然后选择不属于管理者 EMPNO 的 EMPNO。
Output -


问题 12。编写查询以找出第二个最高级的员工,即根据雇用日期第二个加入组织的员工。
Answer:SELECT * FROM EMP E WHERE 2 = (SELECT COUNT(DISTINCT M.HIREDATE) FROM EMP M WHERE E.HIREDATE >= M.HIREDATE);
使用相关子查询,我们可以通过将内部查询输出与 WHERE 子句中的 2 进行比较来获得第二高级员工。
Output -

问题 13。编写查询以找出第 5 个最高薪水。
Answer:
SELECT * FROM EMP E WHERE 5 = (SELECT COUNT(DISTINCT M.SAL) FROM EMP M WHERE E.SAL <= M.SAL);
使用相关子查询,我们可以通过将内部查询输出与 WHERE 子句中的 5 进行比较来获得第 5 个最高薪水。
Output -

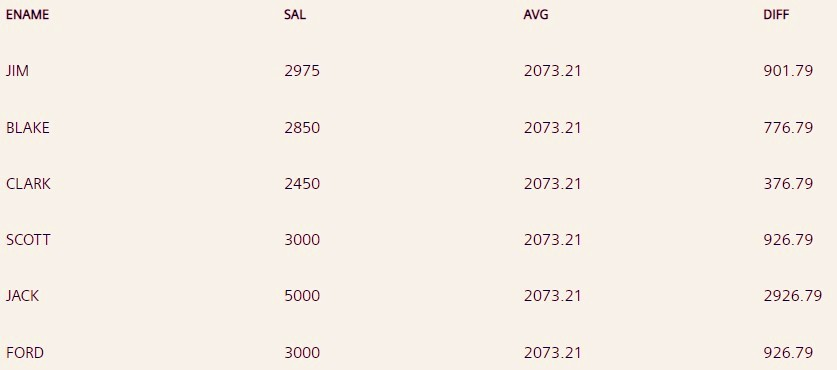
问题 14。编写一个查询,找出工资高于平均工资的员工与平均工资的偏差。
注 –将平均工资四舍五入,工资差异最多为两位数。
回答:
SELECT ENAME, SAL, ROUND((SELECT AVG(SAL) FROM EMP),2) AS AVG, ROUND(SAL - (SELECT AVG(SAL) FROM EMP),2) AS DIFF FROM EMP WHERE SAL > (SELECT AVG(SAL) FROM EMP);
首先,选择收入高于平均工资的员工,然后计算这些员工与平均工资的偏差。
Output -
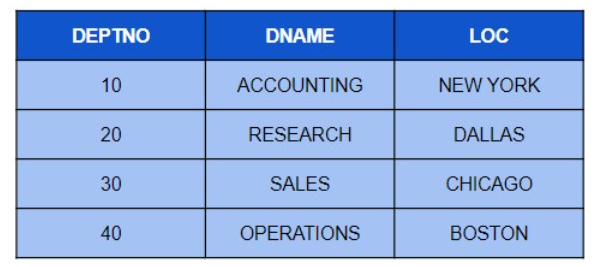
有关问题编号,请参阅dept表以及上述emp表。15 和 16。
问题 15。编写查询以找出在其部门中获得最高薪水的员工。
Answer:SELECT * FROM EMP WHERE SAL IN (SELECT MAX(SAL) FROM EMP GROUP BY DEPTNO);
使用简单的子查询首先使用分组操作获取每个部门的最高薪水列表,然后根据该列表选择获得薪水的员工。
Output -
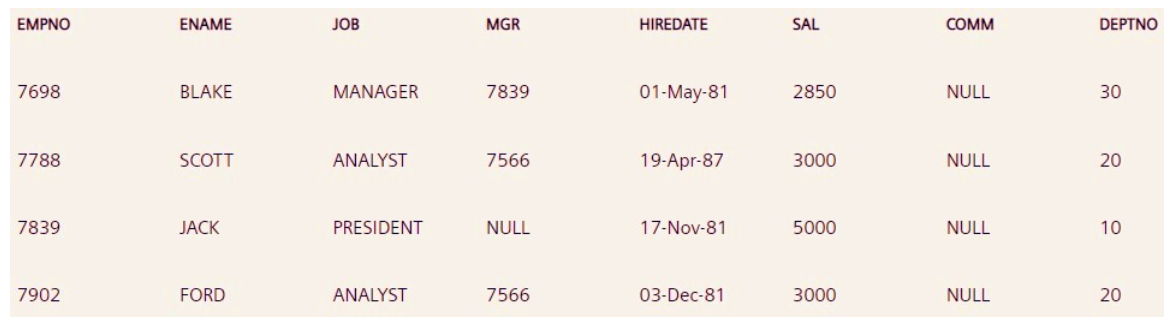
问题 16。编写查询以找出部门最低工资、最高工资、总工资和平均工资。
Answer:
SELECT D.DEPTNO, MIN(SAL), MAX(SAL), SUM(SAL), AVG(SAL) FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO GROUP BY D.DEPTNO;
首先内部连接员工和部门表,然后按 DEPTNO 分组以找出每个部门的最低、最高、总和平均工资。
Output -

问题 17。考虑客户表的当前表结构和所需的表结构,如下所示。
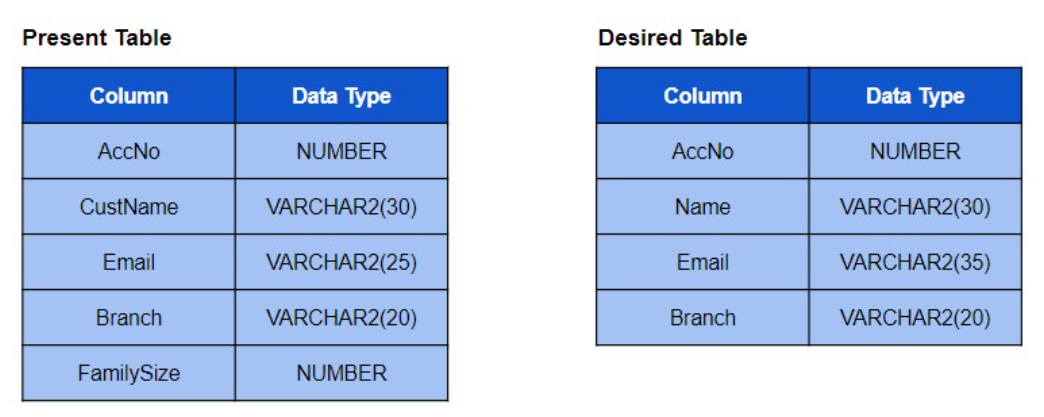
选择将产生所需表格的正确语句
a. ALTER TABLE CUSTOMER RENAME CustName to Name;
b. ALTER TABLE CUSTOMER RENAME COLUMN CustName to Name;
c. ALTER TABLE CUSTOMER ADD Email VARCHAR2(35);
d. ALTER TABLE CUSTOMER MODIFY Email VARCHAR2(35);
e. ALTER TABLE CUSTOMER DROP FamilySize;
f. ALTER TABLE CUSTOMER DROP COLUMN FamilySize;
答案:b、d、e
使用 - 将 CustName 列重命名为 Name
ALTER TABLE CUSTOMER RENAME COLUMN CustName to Name;
使用以下命令将电子邮件列数据类型从 VARCHAR2(25) 修改为 VARCHAR2(35) -
ALTER TABLE CUSTOMER MODIFY Email VARCHAR2(35);
使用 - 删除 FamilySize 列
ALTER TABLE CUSTOMER DROP FamilySize;
问题 18。考虑以下表架构和事务表的数据。
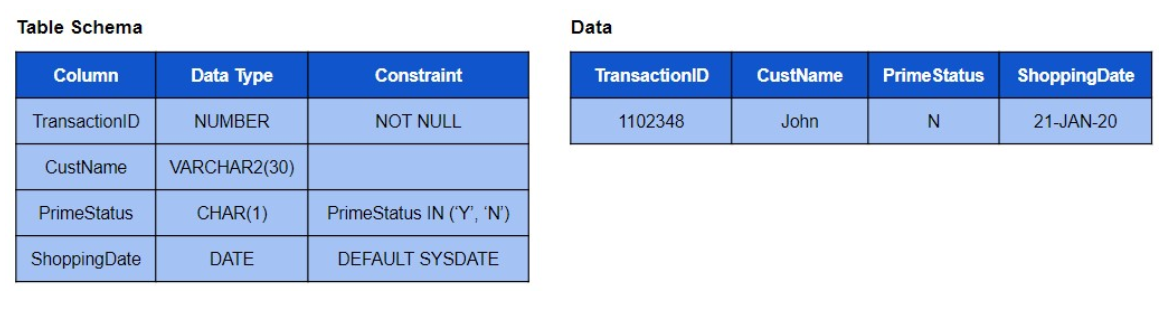
选择有效的 UPDATE 语句
a. UPDATE TRANSACTION SET PrimeStatus = ‘Yes’ WHERE TransactionID = 1102348
b. UPDATE TRANSACTION SET PrimeStatus = ‘VALID’ WHERE CustName = ‘John’
c. UPDATE TRANSACTION SET TransactionID = NULL WHERE CustName = ‘John’
d. UPDATE TRANSACTION SET ShoppingDate = NULL WHERE TransactionID = 1102348
答案:d
CHECK 约束只允许一组预定义的值,所以这里 PrimeStatus 列只允许 Y 或 N。
NOT NULL 约束不允许 NULL 值,因此不能将 TransactionID 设置为 NULL。
我们可以在 ShoppingDate 列中插入 NULL 值。
Output -
UPDATE TRANSACTION SET ShoppingDate = NULL WHERE TransactionID = 1102348;

问题 19。以下 SQL 语句的输出是什么?
SELECT TRANSLATE('AWESOME', 'WOE', 'VU') FROM DUAL;a. AVESUME
b. AVSOM
c. AVSUM
d. AWESUME
答案:c
对于输入字符串,TRANSLATE() 函数将from_string参数中指定的字符替换为to_string参数中对应的字符。如果to_string参数中没有相应的字符,则从输入字符串中删除from_string参数中存在的额外字符。
SELECT TRANSLATE('AWESOME', 'WOE', 'VU') FROM DUAL;Output -

Q 20. 考虑如下所示的emp和insurance 表。
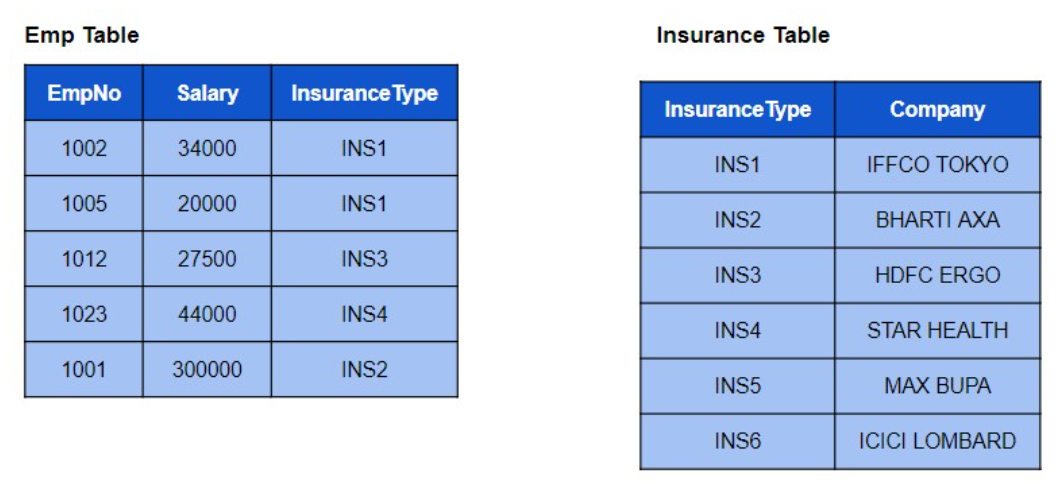
如何获得以下输出?
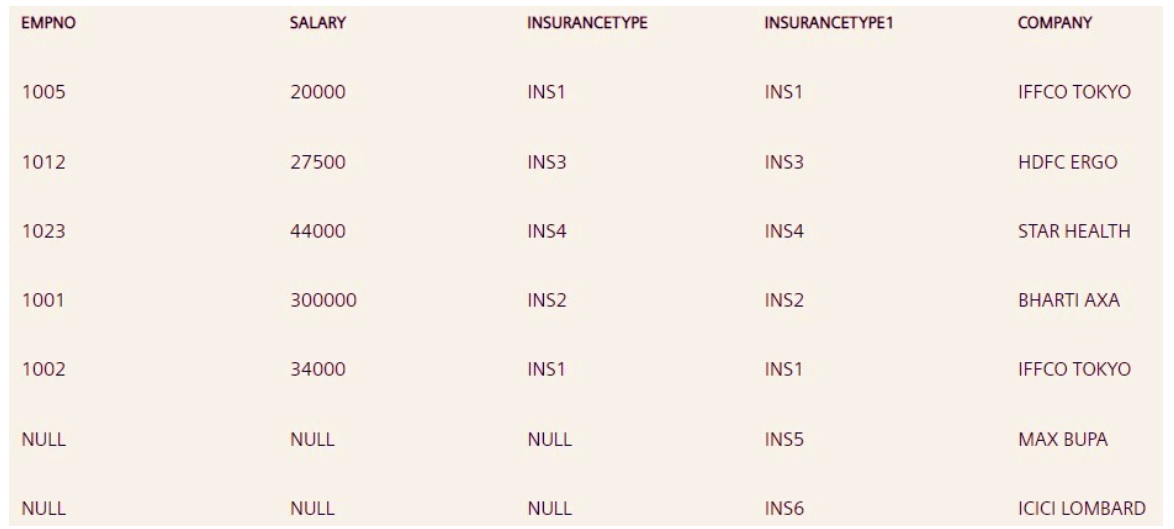
a. SELECT * FROM EMP1 LEFT JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
b. SELECT * FROM EMP1 JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
c. SELECT * FROM EMP1 RIGHT JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
d. SELECT * FROM EMP1 FULL JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
答案:c、d
右连接返回右表中的所有记录以及左表中匹配的记录。
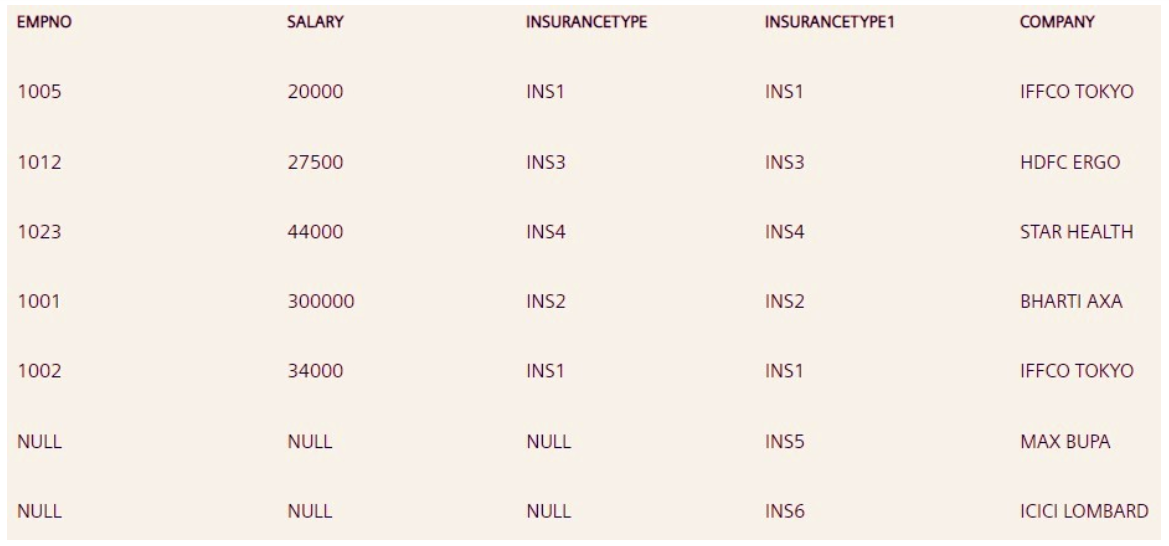
在这里,由于 emp(左)表的所有保险类型都存在于 insurance(右)表中,因此完全外连接也将返回相同的输出。
注 –在分析输出时,关注记录值而不是它们在输出中的顺序。
原文标题:20 SQL Coding Interview Questions
原文作者:Vikas Verma
原文链接:https://www.analyticsvidhya.com/blog/2022/06/20-sql-coding-interview-questions/
