





随着组织应对当今数据量的爆炸性增长,存储的效率和可扩展性成为运营成功数据平台以推动业务洞察力和价值的关键。Apache Ozone 是一个分布式、可扩展和高性能的对象存储,可用于Cloudera Data Platform Private Cloud。CDP 私有云使用 Ozone 将存储与计算分开,这使其能够在本地处理数十亿个对象,类似于受益于 S3 之类的公共云部署。Ozone 还与 S3 API* 完全兼容,将其确立为面向未来的解决方案,并使 CDP 混合云能够满足对混合数据云不断增长的需求。
Apache Ozone 在HDDS-2939 中添加了一项名为文件系统优化 (“FSO”) 的新功能. 此功能已在上游合并到 master 分支,并将在下一个 Ozone 版本中提供。FSO 功能有效地提供了文件系统语义(分层命名空间),同时保留了对象存储的固有可伸缩性。使用 FSO,Apache Ozone 保证了原子目录操作,即使目录中有大量子路径(目录/文件),重命名或删除目录也是一个简单的元数据操作。事实上,这使 Apache Ozone 比数据分析生态系统中的其他对象存储具有显着的性能优势。此外,Ozone 与 Hive、Spark 和 Impala 等 Apache 数据分析工具无缝集成。此外,各种用例,如 Apache Hive 删除表查询、递归目录删除等。
Apache Ozone 支持不同用例的相同数据的互操作性。例如,用户可以使用 FileSystem API 将数据摄取到 Apache Ozone,并且可以通过 Ozone S3 API* 访问相同的数据。这可能会通过本地 ObjectStore 提高用户平台的效率。
有关 Apache Ozone 原子性保证的更多详细信息,请参阅Apache Ozone 文档。
在这篇博文中,我们将研究衡量 Apache Hadoop Teragen 性能的基准测试结果,以及使用 Apache Ozone(原生 o3fs)与 Ozone S3 API* 进行的目录/文件重命名操作。我们为基准测试启用了 Apache Ozone 的 FSO 功能。
工作提交者
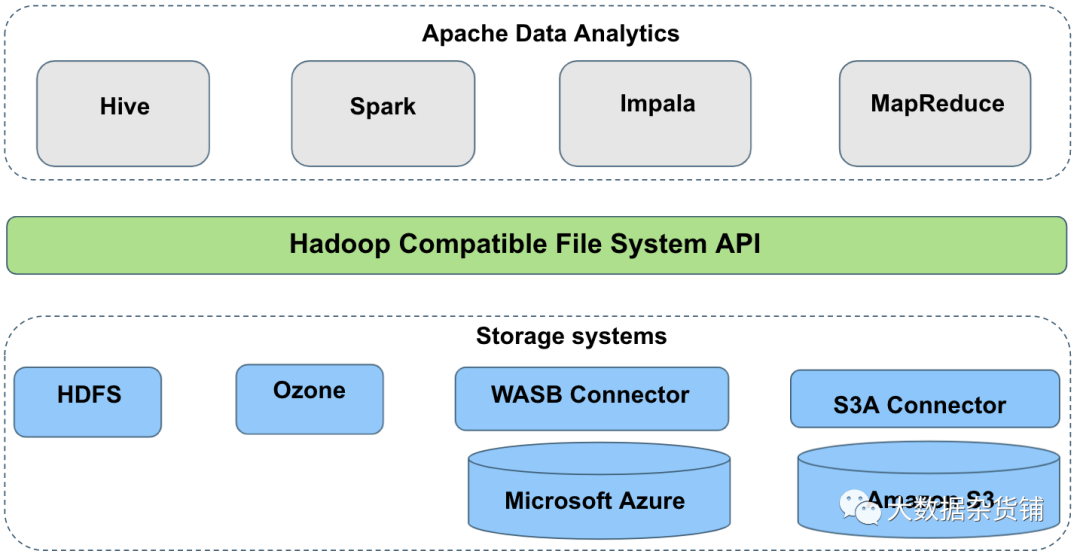
Apache 数据分析传统上假设重命名和删除操作是严格原子的。大多数数据分析工具,如 Apache Hive、Apache Impala、Apache Spark、MR 等,经常将输出写入临时位置,然后在作业结束时将其重命名为公开可见。例如,Hive 和 Impala 的作业提交者需要目录列表的一致性和重命名操作的原子性。因此,查询的性能直接受到中间重命名操作完成速度的影响。这意味着读者在全有或全无的基础上观察到工作输出。下面是 Apache 数据分析以及 Apache HDFS、Apache Ozone、类似 S3 的对象存储等存储系统之间的交互的高级视图。尽管 Ozone 是一个对象存储,但它不需要任何特殊的输出提交者。
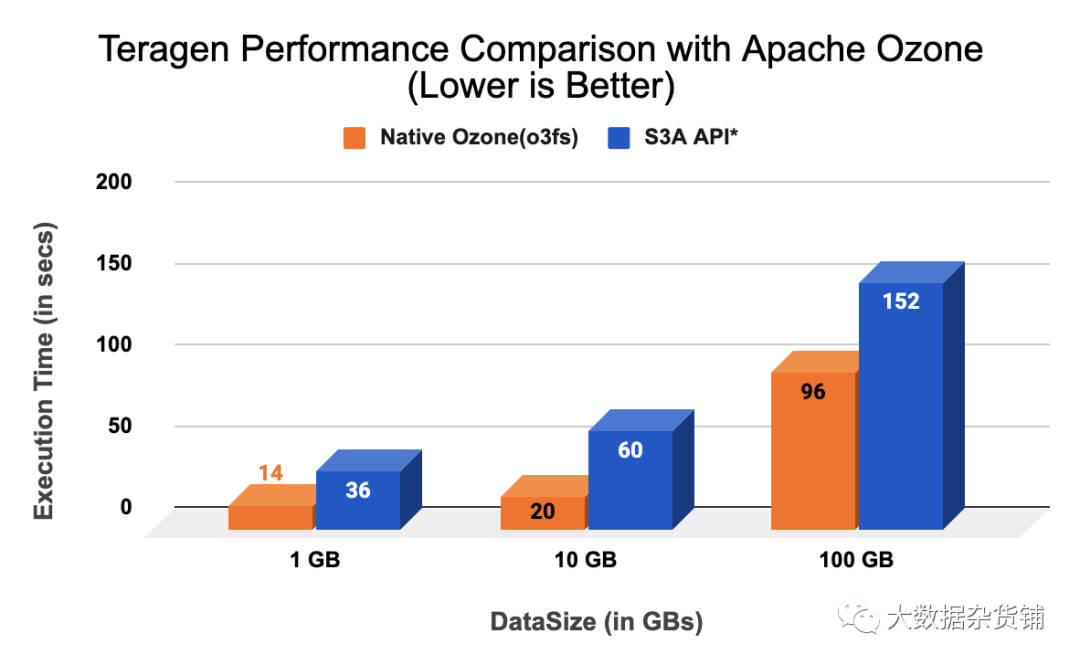
Apache Ozone 和 S3 API 之间的性能比较*
使用 Teragen 对 Apache Ozone 与 S3 API* 进行基准测试:
我们在由 YARN 和 HDFS 与 Apache Ozone 组成的传统 Hadoop 堆栈中运行 Apache Hadoop Teragen 基准测试。我们使用 Apache Hadoop S3A 文件系统连接器连接到 S3 API*,还使用 Hadoop 的默认文件提交器将工作提交到 S3。
以下测量结果是使用 Teragen 对数据大小分别在1GB、10GB和100GB范围内的各种运行获得的。我们对每个数据大小进行了多次运行测试(3 次运行),并且性能数据已被平均,运行之间的最大偏差约为 10%。结果表明,Native Ozone 的性能比 S3 对象存储(例如 S3 API* 等)更快。
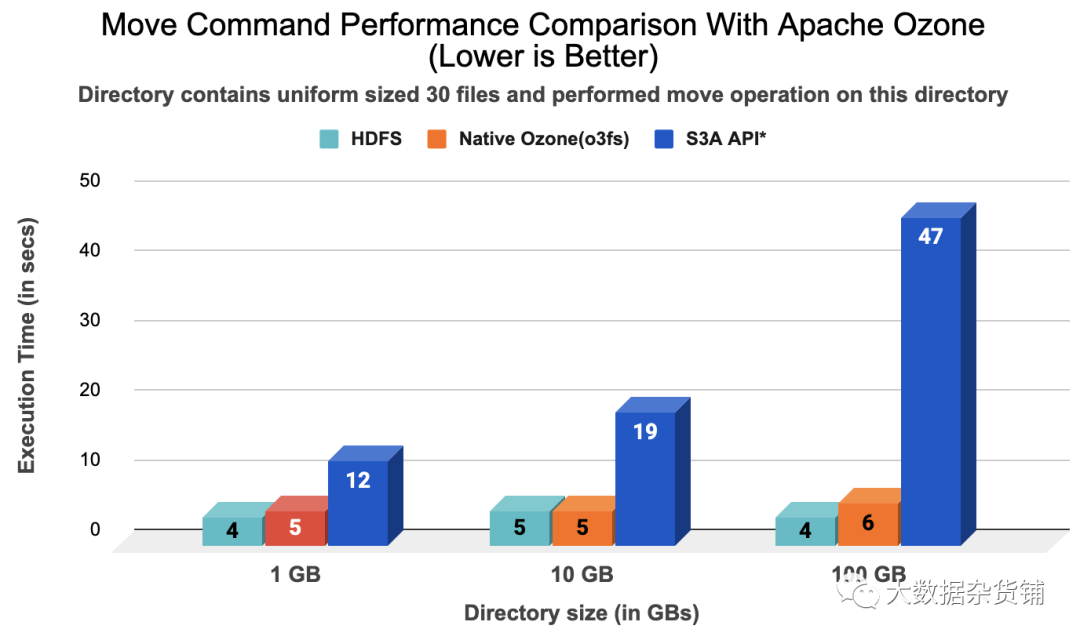
文件移动性能对比:
我们对大小分别在1GB、10GB和100GB范围内的目录运行了“hadoop mv 命令”测试,这些目录存储在 Apache Ozone 和 S3 API* 中。这个目录包含一个统一大小的 30 个文件。Apache Native Ozone (o3fs) 执行了将源目录重命名为目标目录的操作,类似于 HDFS,但与执行复制对象和删除原始对象操作的 S3a(S3 API* 等)不同。
下图显示了移动操作的 Ozone 性能与 HDFS 处于同一顺序,同时保留了原子性保证。我们对每个目录大小进行了多次运行测试(3 次运行),并且性能数据已经平均,运行之间的最大偏差约为 10%。
测试环境详情:
集群设置由 10 个统一物理节点组成,40 核 Intel® Xeon® 处理器、128 GB RAM、3 x 2 TB 磁盘、1 x 1 TB 磁盘和 10 Gb/s 网络,配置有 3 个专用磁盘用于数据存储. 该节点运行CentOS的7,和Cloudera的运行7.1.7,其中包含的Hadoop 3.1.1,3.5.5的ZooKeeper和Apache的主分支,版本内置臭氧1.1.0,github上提交哈希 19ed79464ca9ed2210ca8ac47a4736fb67d8bd3e 。
SSL/TLS 已关闭且处于不安全模式。为 Apache Ozone 服务启用了高可用性。
我们使用 Apache Hadoop S3A 文件系统连接器连接到 AWS S3 对象存储,并使用 Hadoop 的默认文件提交器将工作提交到 S3。
结论
基准测试结果表明,启用了文件系统优化 (“FSO”) 功能的 Apache Ozone 比 S3 API* 之类的对象存储更快,并且对高性能数据密集型工作负载非常有吸引力。使用 FSO,臭氧目录/文件重命名和删除操作高度一致,并提供确定性的性能数字,而不管其中包含的大量子路径(目录/文件)如何。
简而言之,Ozone with FSO 通过作业和任务提交帮助用户实现与 HDFS 相同的原子性保证,从而使其与 Apache 数据分析工具(如 Hive、Spark 和 Impala 等)本地集成,而无需类似 S3Guard 的层,同时保留其性能特点。CDP 私有云中的 Ozone 提供了与 Apache Ranger 和 Apache Atlas 的开箱即用的安全集成。此外,存储在 Ozone 中的数据可以在作为 CDP 一部分部署的用例以及外部第三方分析之间共享,从而消除数据重复的需要,从而降低风险并优化资源利用率。
进一步阅读
Apache Ozone – 对象存储概述
Apache Ozone – 对象存储架构
S3 API* – 指 S3 API 协议的 Amazon S3 实现。
原文作者:Rakesh Radhakrishan和Mukul Kumar Singh
原文链接:https://blog.cloudera.com/apache-ozone-a-high-performance-object-store-for-cdp-private-cloud/
