




本周介绍了 5 个计算机视觉领域的 SoTA 模型,均于最近发表于 2022 年顶会 CPVR 和 ECCV:
RepMLP 带 MLP 进军智能驾驶, ConvNeXt 用 Transformer 里的技术改进卷积, WaveViT 加入小波变换改进视觉 Transformer , EclipSE 处理长视频离不开视听结合, GraphVid 将图神经网络应用到视频理解。
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些免费的鼓励:点赞、喜欢、或者分享给你的小伙伴。
https://github.com/towhee-io/towhee/tree/main/towhee/models
CVPR 2022 新模型 RepMLP,用 MLP 主宰计算机视觉模型
出品人:Towhee 技术团队 顾梦佳
RepMLP 改善了全连接层在视觉任务中的表现,并且将 MLP 成功地对接到下游任务中。实验结果结果表明 RepMLP 比其他MLP模型更快、更强、训练代价更低。另外,RepMLP 是第一个可以直接用于 Cityscapes 语义分割(智能驾驶场景)的 MLP backbone。
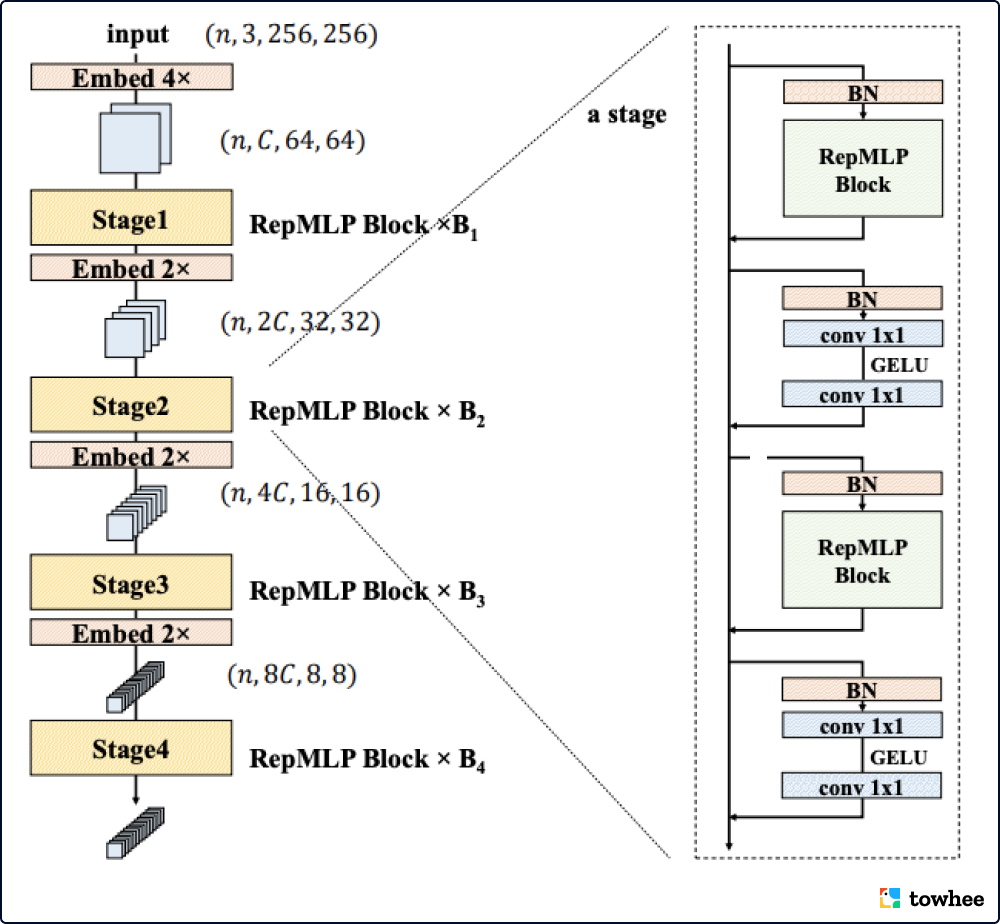
与卷积层相比,全连接(FC)层更适于建模长程依赖,但不擅长捕捉局部特征。RepMLP 模型中提出一种新的结构重参数化(Structural Re-parameterization)方法 Localtiy Injection,用于解决这一问题。它将卷积核的参数等效合并并行的 FC 中去,从而将局部先验注入 FC 层。此外,RepMLP 的核心是一种包含了三个全连接层的 MLP 模块(RepMLP Block)与一种层次化的 MLP 模型(RepMLPNet)。与同时期的多个 MLP 不同,RepMLPNet 是层次化设计的,这使其可以自然地接入下游任务(如语义分割)的 backbone。
相关资料:
模型代码:https://github.com/towhee-io/towhee/tree/main/towhee/models/repmlp 论文:https://arxiv.org/abs/2112.11081 更多资料:https://zhuanlan.zhihu.com/p/524878219;https://www.cityscapes-dataset.com/
ConvNeXt:Transformer 只是吃了技术迭代的红利?纯卷积模型也可以!
出品人:Towhee 技术团队 顾梦佳
ConvNeXt 系列模型完全由标准卷积模块构建而成,其准确性和可扩展性方面与 Transformers 竞争激烈,在 ImageNet 图像数据集上达到了 87.8% 的 top-1 准确性。而在 COCO 数据集的目标检测任务和 ADE20K 数据集的语义分割任务上,ConvNeXt 的性能已经超越 Swin Transformers。
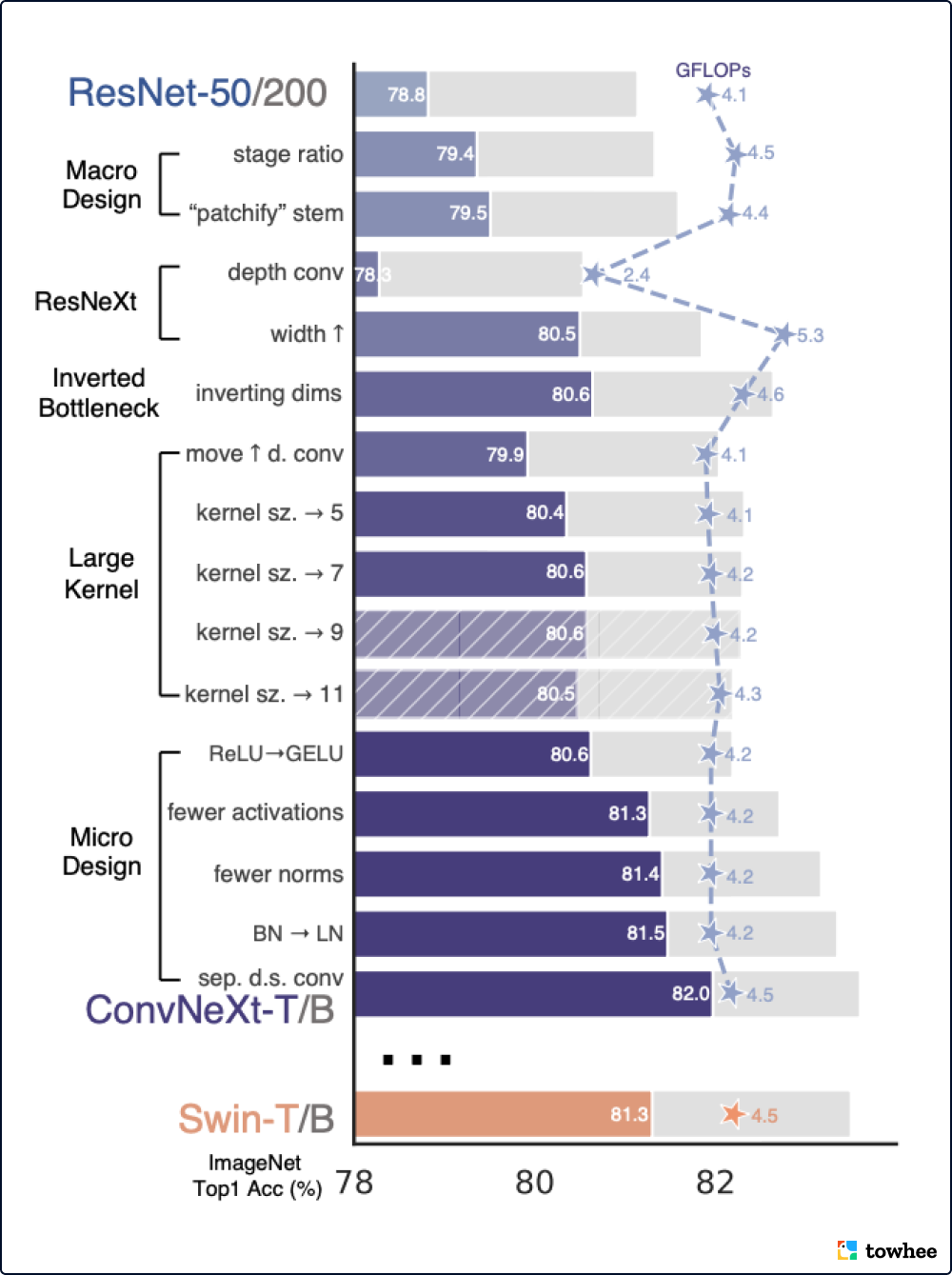
ConvNeXt 以改进卷积性能为导向,重新探索了 Transformers 系列模型的框架设计。它在 Transformers 的训练方法和结构设计中找到改进卷积的方向和方法,在保持传统卷积模型的简洁性和易用性的同时,达到高效与精准。ConvNeXt 学习和使用了 Transformer 模型的训练技术,增强的训练方法能够将 ResNet-50 模型的性能从提高 2.7%。利用改进后重新训练的标准 ResNet 为起点,ConvNeXt 按照 hierarchical vision Transformer (例如 Swin-T)的架构设计,重新构建了“现代化”的卷积模型框架。
相关资料:
模型代码:https://github.com/facebookresearch/ConvNeXt 论文:https://arxiv.org/abs/2201.03545 更多资料:https://www.361shipin.com/blog/1551282811518844928
超越SoTA!WaveViT 用小波变换优化多尺度视觉 Transformer
出品人:Towhee 技术团队 张晨、顾梦佳
WaveViT 是一种改良的新型视觉 Transformer,通过引入小波理论实现可逆、无损失的下采样,能够更好地平衡效率和精度。通过对多个视觉任务(如图像识别、物体检测和实例分割)进行广泛的实验,Wave-ViT 证明了它的优越性,其性能超过了目前最先进的 ViT 骨干模型,展现出强有竞争力的 FLOPs。
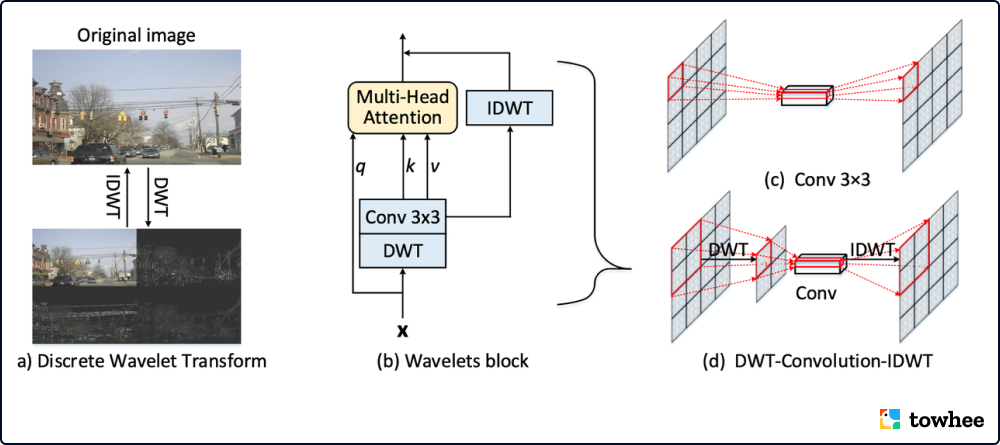
多尺度视觉 Transformer(Multiscale ViT)已经成为计算机视觉任务的强大支柱,而 Transformer 中的自注意力机制是按输入 patch 数量的四次方扩展的。为了大幅降低计算成本,现有的解决方案通常会采用对键/值的下采样操作(例如,平均池化)。然而,这种过于激进的下采样设计是不可逆转的,并且不可避免地导致信息丢失,特别是对于物体中的高频成分(如纹理细节)。在小波理论的启发下,一个新的小波视觉 Transformer(WaveViT)诞生了。该结构用统一的方式把小波变换和自注意力机制结合起来,使自注意力学习能够在键/值上进行无损的下采样,有利于追求在效率与准确率上更好的权衡。此外,反小波变换也被用来加强自注意力的输出,拥有更大感受野的局部环境。
相关资料:
模型代码:https://github.com/YehLi/ImageNetModel 论文:https://arxiv.org/pdf/2207.04978.pdf
视听结合,EclipSE 带来更高效的文本-长视频检索
出品人:Towhee 技术团队 张晨、顾梦佳
与以往为短视频检索(5-15秒)设计的方法不同,EclipSE(Efficient CLIP with Sound Encoding) 用音频数据替代部分视频特征,能够在更长的视频中捕捉复杂的人类行为。实验证明,该方法比单纯的长视频检索方法快 2.92 倍,内存效率也提高了 2.34 倍。除了更高的效率与更低的成本外,EclipSE 在多个公开的长视频数据集(ActivityNet、QVHighlights、YouCook2、DiDeMo、Charades)上也取得了更高的文本-视频检索精度。
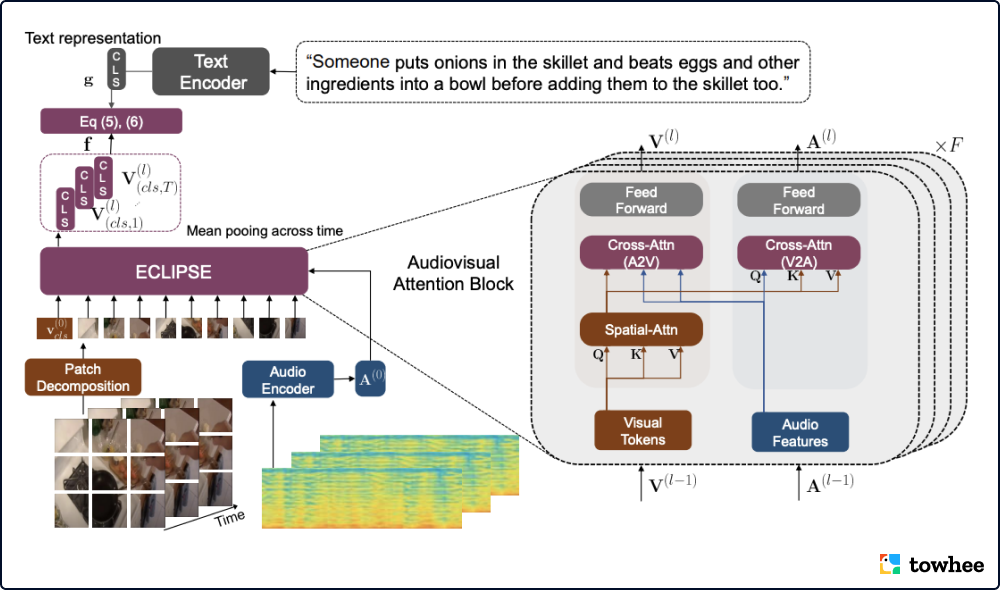
标准的纯视频检索方法在处理长视频时,会提取出数百个密集的视频帧,导致了巨大的计算成本。为了解决这个问题,EclipSE 选择用简洁的音频线索取代部分视频。这些线索能够简单概括动态的音频事件,并且处理成本更低。通过增加一个统一的视听转换模块,模型能够从视频帧和音频流中捕捉互补的线索,使流行的 CLIP 模型适用于视听视频环境。
相关资料:
模型代码:https://github.com/GenjiB/ECLIPSE 论文:https://arxiv.org/pdf/2204.02874v1.pdf
图神经网络 GraphVid 仅需几个节点就能理解视频
出品人:Towhee 技术团队 王翔宇、顾梦佳
图神经网络 GraphVid 用更简单的图特征表示视频,实现视频理解任务。通过在公开可用的数据集 Kinetics-400 和 Charades 上的实验, GraphVid 证明了其仅需十分之一的计算资源,就能达到具有竞争力的结果。这表明图神经网络在视频理解领域能够有效地权衡成本和性能,带来更高的效益。
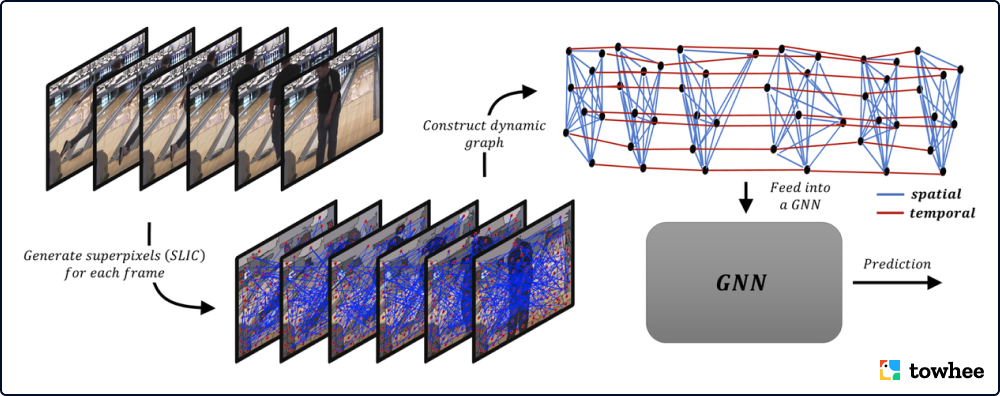
GraphVid 提出了一种简洁的视频特征表示,能够将感知上有意义的特征编码成图形。这种视频表征可以充分利用视频中的冗余信息,以此减少计算量。该方法首先通过将超像素视作图形节点,构建基于超像素的视频图形表征,并且在相邻的超像素之间创建时空连接。然后,模型利用图卷积网络处理该表征,预测所需的输出。这样我们就可以用更少的参数训练模型,从而减少训练时间和所需的计算资源。
相关资料:
论文:https://arxiv.org/pdf/2207.01375.pdf
Zilliz 是向量数据库系统领域的开拓者和全球领先者,研发面向 AI 生产系统的向量数据库系统。Zilliz 以发掘非结构化数据价值为使命,致力于打造面向 AI 应用的新一代数据库技术,帮助企业便捷地开发 AI 应用。Zilliz 的产品能显著降低管理 AI 数据基础设施的成本,帮助 AI 技术赋能更多的企业、组织和个人。

