点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
我们现有日志采集方式主要是基于开源flume 进行二次开发,已实现对应用日志、syslog、组件日志、sql查询等类型的日志进行采集,适用传统运行环境日志采集,长期实践过程中flume对文件数过多,量大的情况下采集存在资源消耗较高的现象(进程高cpu) 。应用大规模上K8s云环境后需要对容器及容器内部日志进行采集,flume 本身并不支持,需要找寻相应的开源解决方案,而今年推出的开源日志采集组件Loggie可以满足这种场景。Loggie是一个基于Golang的轻量级、高性能、云原生日志采集Agent和中转处理Aggregator,支持多Pipeline和组件热插拔,提供了基于日志可观测性、快速排障、异常预警、自动化运维能力。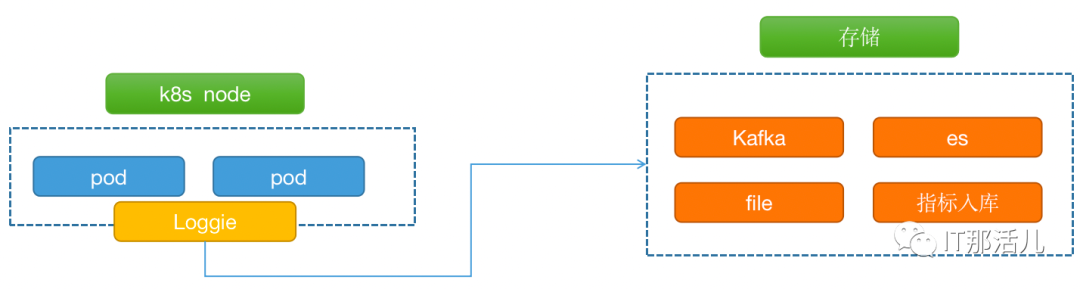
2.1 环境准备
helm下载地址:https://github.com/kubernetes/helm/releases,下载上传解压即可。下载好Loiggie安装包:https://github.com/loggie-io/installation/releases/download/v1.2.0/loggie-v1.2.0.tgzloggie官方文档:https://loggie-io.github.io/docs/2.2 部署
1)DaemonSet方式部署loggie,helm install loggie ./loggie -nloggie --create-namespace 可以通过kubectl get ds -n loggie命令查看loggie容器是否创建成功。3)定义输出源Sink,创建一个Loggie定义的CRD Sink实例,表明日志发送的后端。接收日志的后端存在多种,例如es、kafka、Prometheus,本次演示配置输出到loggie容器日志(dev)和kafka中。apiVersion: loggie.io/v1beta1
kind: Sink
metadata:
name: default
spec:
sink: |
type: dev
printEvents: true
apiVersion: loggie.io/v1beta1
kind: Sink
metadata:
name: default
spec:
sink: |
type: kafka
brokers: ["192.168.XX.XXX:9092"] # kafka地址
topic: "loggie" # topic名称
其他输出源配置详见:https://loggie-io.github.io/docs/reference/下的Sink节点。通过kubectl apply -f xxx.yaml创建sink。4)定义采集任务,Loggie定义CRD LogConfig,表示一个日志采集任务;本次演示两种采集方式,直接采集应用日志文件和采集容器日志。
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: tomcat-app
namespace: default
spec:
selector:
type: pod
labelSelector:
app: asdf
pipeline:
sources: |
- type: file
name: mylog
paths:
- stdout
sinkRef: default
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: tomcat-app
namespace: default
spec:
selector:
type: pod
labelSelector:
app: asdf
pipeline:
sources: |
- type: file
name: mylog
paths:
- usr/local/logs/app.log
sinkRef: default
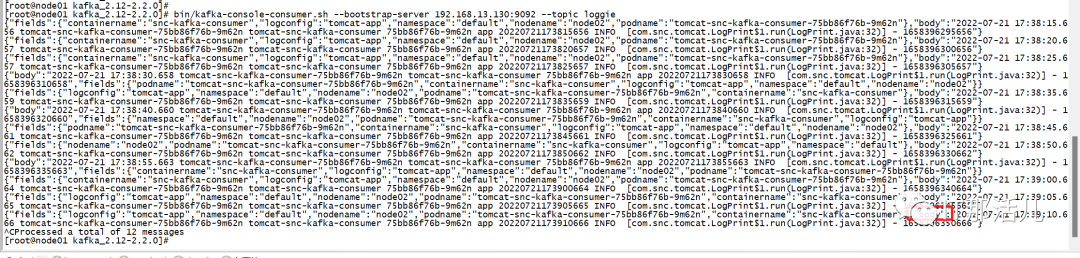
更多采集配置请详见:https://loggie-io.github.io/docs/reference/下的source节点。5)配置完成后查看测试pod所在节点(dev模式下日志只会采集到同一节点的loggie),kubectl get pods -l app=asdf -o wide ,查看loggie日志和kafka消费可以看到有数据,其中body字段为日志信息,日志采集成功。