




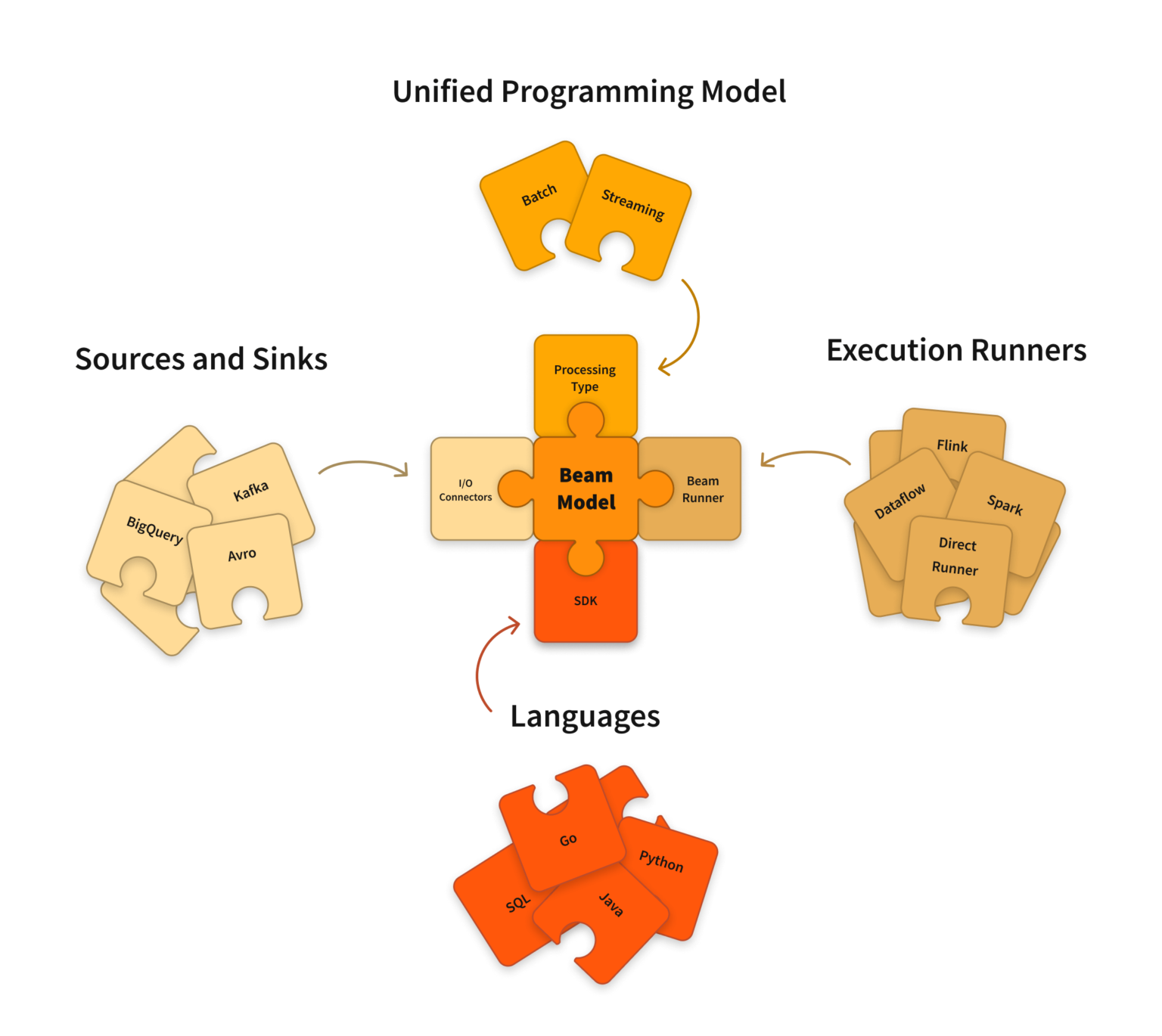
Apache Beam是用于定义批处理和流数据并行处理管道的统一模型。它是一个软件开发工具包(SDK),用于定义和构建数据处理管道以及执行这些管道的运行程序。
为什么是Apache Beam?
-
Apache Beam处理批处理和流式数据处理应用程序。很容易将流处理更改为批处理,反之亦然。
-
Apache Beam提供了灵活性。目前有Java、Python和Golang SDK可用于Apache Beam。我们可以使用我们选择的任何舒适的语言。
-
Apache Beam提供了可移植性。管道运行器将数据处理管道转换为与用户选择的后端兼容的API。目前,这些分布式处理后端由
- Apache Flink
- Apache Nemo
- Apache Samza
- Apache Spark
- Google Cloud Dataflow
- Hazelcast Jet
能力矩阵
能力矩阵试图说明单个转轮的能力,并提供了支持梁模型的每个转轮的高级视图。
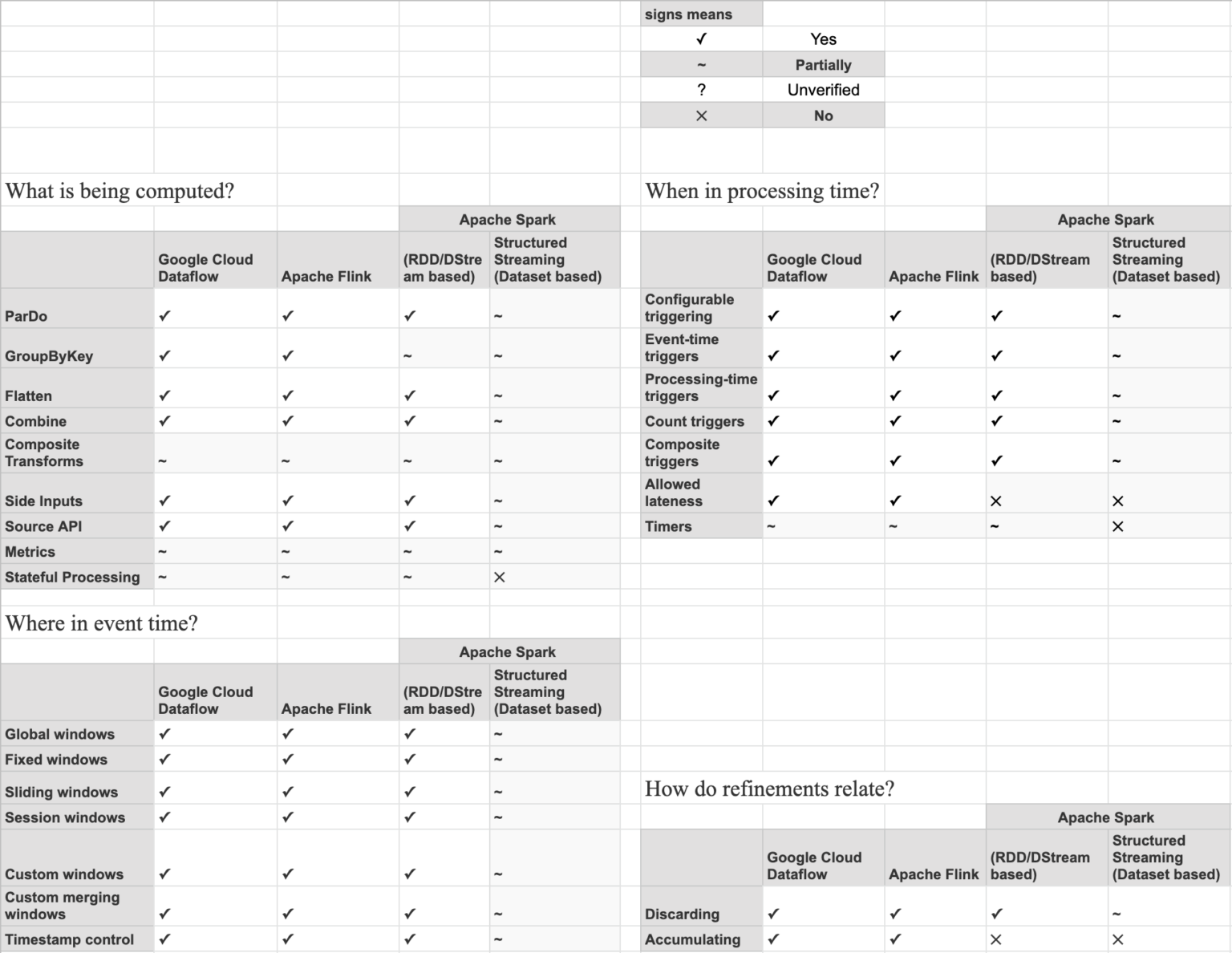
基于能力矩阵,用户可以决定哪个跑步者适合他的用例。
案例研究
在官方网站上,如前所述,有许多Apache Beam的用例可供参考:
有趣案例研究的一些细节:
-
实时机器学习流水线,在期望时间框架的窗口上,使用实时数据连续训练ML模型。
-
实时特征计算和模型执行。以亚秒的延迟实时处理事件,使我们的ML模型能够了解市场。
-
使用Beam实现搜索引擎扩展本地基础设施的经验,了解更多基于字节的数据洗牌的好处,以及Apache Beam可移植性和抽象带来最大价值的用例。
基本概念
编程模型中的关键概念是:
-
管道–管道是定义所需数据处理操作的用户构建的转换图(DAG)。它是PCollection和PTransform的组合。我们还可以说,它从头到尾都有完整的数据处理任务。
-
PCollection–PCollection是一个无序的元素包。每个PCollection是一个潜在的分布式、同质数据集或数据流,由特定管道拥有。数据集可以是有界的,也可以是无界的。
-
pttransform–pttransform(或transform)表示管道中的数据处理操作或步骤。变换应用于零个或多个PCollection对象,并生成零个或更多Pcollect对象。
-
PipelineRunner–runner使用所选数据处理引擎的功能运行梁管道。大多数运行程序是大规模并行大数据处理系统的翻译器或适配器,如Direct Runner、Apache Spark或Apache Flink等。
简单地说,我们可以说PipelineRunner执行一个管道,管道由PCollection和PTransform组成。
通过实例理解梁模型
让我们开始使用Python和Colab创建梁管道。本博客主要关注批处理。
谷歌实验室(Colab)是一个完全在云中运行的免费Jupyter笔记本互动开发环境。
在Colab中运行Beam管道的初始设置,转到新笔记本,通过在笔记本中运行以下命令安装apache Beam。
!{'pip install apache_beam'}
!{'pip install apache-beam[interactive]'}

在机器中创建目录和列表。

从本地上传文件。
from google.colab import files
upload = files.upload()
创建一个转换示例
源转换是转换类型之一,它具有TextIO。阅读并创建。源转换在概念上没有输入。
在下面的代码中,我们传递了用于创建Pcollection和写入文本文件的元素列表。
import apache_beam as beam
p3 = beam.Pipeline()
lines1 = (p3
| beam.Create([100,101,102,103,104,105,106,107,108,109])
| beam.io.WriteToText('output/file2')
)
p3.run()
输出:上述程序的结果
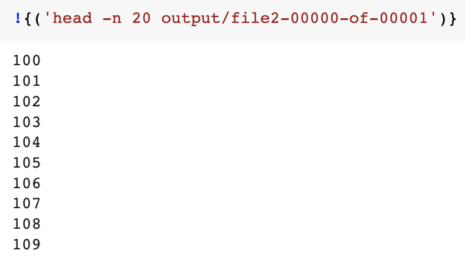
用于以下示例的示例数据
架构:id、empname、薪资、部门、加入日期
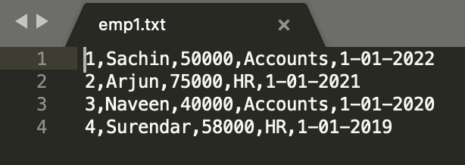
映射/过滤变换示例:
在这里,我们将使用映射/过滤转换获取人力资源部门员工数量。
import apache_beam as beam
p1 = beam.Pipeline()
emp_count = (
p1
|beam.io.ReadFromText('emp1.txt')
|beam.Map(lambda record: record.split(','))
|beam.Filter(lambda record: record[3] == 'HR')
|beam.Map(lambda record: (record[3], 1))
|beam.CombinePerKey(sum)
|beam.io.WriteToText('output/emp_output1')
)
p1.run()
管道简要说明:
-
创建包括Ptransform和Pcollection的光束管道。
-
ReadFromText(ptTransform)转换返回一个PCollection,它读取文本文件,PCollection包含文件中的所有行。
-
Map transform将数据wrt拆分为“”,并返回“”分隔的数据列表。为了更好地理解,我对上面的代码和结果进行了注释和运行,如下所示
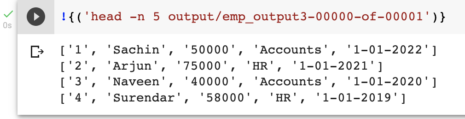
- Filter transform用于过滤数据,这里我将HR记录过滤为Pcollection。

CombinePerKey用于将值wrt组合到每个键。这是程序的最终结果。

分支管道示例:
分支管道用于在同一数据上运行2个或多个任务。
为了更好地理解,我们使用了相同的样本数据,并计算了各部门的计数。
在下面的代码中,我们试图获得每个部门的员工数量
import apache_beam as beam
p = beam.Pipeline()
input_collection = (
p
| "Read from text file" >> beam.io.ReadFromText('emp1.txt')
| "Splitting rows based on delimiters" >> beam.Map(lambda record: record.split(','))
)
accounts_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'Accounts')
| 'Pair each accounts with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Group and sum1' >> beam.CombinePerKey(sum)
#| 'Write the results of ACCOUNTS' >> beam.io.WriteToText('output/emp4')
)
hr_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'HR')
| 'Pair each HR with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Group and sum' >> beam.CombinePerKey(sum)
#| 'Write the results of HR' >> beam.io.WriteToText('output/emp5')
)
empcount = (
input_collection
| 'Pair each dept with 1' >> beam.Map(lambda record: ("ALL_Dept", 1))
| 'Group and sum2' >> beam.CombinePerKey(sum)
#| 'Write the results of all dept' >> beam.io.WriteToText('output/emp7')
)
output =(
(accounts_empcount,hr_empcount,empcount)
| beam.Flatten()
| beam.io.WriteToText('output/emp6')
)
p.run()
-
每个操作都可以在管道代码中标记,这有助于调试,特别是当您有复杂的管道,并且在管道中多次使用相同的代码行时。每个标签都必须是唯一的,否则Apache Beam将抛出错误。
-
在input_collection Pcollection中,我们在分支管道之前添加了公共代码(函数),因此在本例中,我们读取数据并根据分隔符拆分数据。
-
在hr_empcount:p集合中,我们统计的是人力资源部门的员工。

-
Accounts_empcount:Pcollections我们统计的是与会计部门相关的员工。

-
empcount Pcollections:我们统计所有部门的员工。

-
输出Pcollections:我们从代码中得到的结果如下所示。
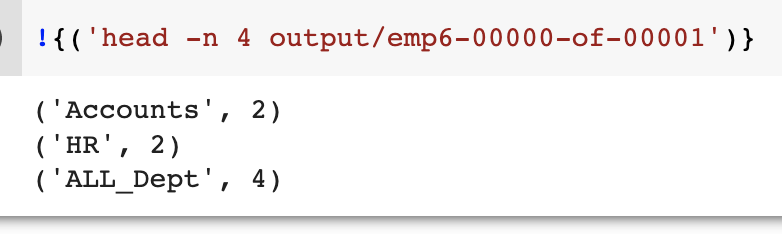
ParDo变换示例:
-
ParDo变换从输入Pcollection中获取元素,对其执行处理功能,并可以返回零、一或多个不同类型的元素。
-
对于ParDo,您需要提供DoFn对象。DoFn对象是一个定义分布式处理函数的Beam类。
-
DoFn类有许多函数,我们需要根据需求重写其中的流程函数。
-
在下面的示例中,我们试图获取会计部门的员工计数
-
如上所述,在SplitRow类、FilterAccountsEmp类、pairDept类和empcount类的代码中,我们提供了DoFn对象,并根据我们的要求重写了流程函数。
import apache_beam as beam
class SplitRow(beam.DoFn):
def process(self, element):
# return type -> list
return [element.split(',')]
class FilterAccountsEmp(beam.DoFn):
def process(self, element):
if element[3] == 'Accounts':
return [element]
class pairDept(beam.DoFn):
def process(self, element):
return [(element[3], 1)]
class empcount(beam.DoFn):
def process(self, element):
(key, values) = element # [Accounts , [1,1] ]
return [(key, sum(values))]
p1 = beam.Pipeline()
account_empcount = (
p1
|beam.io.ReadFromText('emp1.txt')
|beam.ParDo(SplitRow())
|beam.ParDo(FilterAccountsEmp())
|beam.ParDo(pairDept())
| 'Group ' >> beam.GroupByKey()
| 'Sum using ParDo' >> beam.ParDo(empcount())
|beam.io.WriteToText('output/file5')
)
p1.run()
我们从代码中得到的结果如下所示。

复合变换示例
-
在复合变换中,我们将多个变换分组为单个单元。
-
在下面的示例中,我们创建了一个名为MyCompositeTransform的类,在这个类中,我们需要继承其相应的基类,即Beam.Ptransform。
-
PtTransform是我们使用的每个PtTransforms的基类,因此PtTransorm有一个需要重写的扩展方法。
-
此方法将pcollection作为输入,将对其应用多个变换,并返回Pcollect。
-
要使用此复合变换,请使用其唯一标记调用其对象。
-
在下面的示例中,我们将统计每个部门的员工数量。
import apache_beam as beam
def SplitRow(element):
return element.split(',')
class MyCompositeTransform(beam.PTransform):
def expand(self, input_coll):
a = (
input_coll
| 'Pair each respective department with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Grouping & sum' >> beam.CombinePerKey(sum)
)
return a
p = beam.Pipeline()
input_collection = (
p
| "Read from text file" >> beam.io.ReadFromText('emp1.txt')
| "Splitting rows based on delimiters" >> beam.Map(SplitRow)
)
accounts_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'Accounts')
| 'accounts MyCompositeTransform' >> MyCompositeTransform()
)
hr_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'HR')
| 'hr MyCompositeTransform' >> MyCompositeTransform()
)
output =(
(accounts_empcount,hr_empcount)
| beam.Flatten()
| beam.io.WriteToText('output/emp6')
)
p.run()
上述代码的结果:

在本博客中,我试图解释使用Beam模型的批处理,在下一篇博客中,我们将尝试使用Beam模式来介绍流处理。
结论
Apache Beam是流式和批处理数据并行处理的强大模型。它也是便携式和灵活的。
此时最有能力的运行者显然是谷歌云数据流(用于在GCP上运行)和Apache Flink(用于本地和非谷歌云),如能力矩阵所示。
Apache Beam能成为数据处理的未来吗?在评论中分享你的想法,不要忘记注册下一篇文章。
原文标题:APACHE BEAM: THE FUTURE OF DATA PROCESSING?
原文作者:Shashi Kumar
原文链接:https://blog.pythian.com/apache-beam-the-future-of-data-processing/
