




在当今复杂的互联网环境下,我们的系统时时刻刻都暴露在风险(刷单党、羊毛党)的攻击之中,如果我们不采取有效防御措施,那么这些风险就会对业务造成很大的损失。
用公式可以表达出风控规则和风险数据的系统关系:z=f(x, y),f 为系统风控规则,x 为系统实时输入风险数据,y 为系统的事实数据。
挑战性
数据量大,计算延时严重
风控策略多变
目标
准确及时识别风险
采取有效防御措施
总体架构
基于大数据实时计算和可热更新的通用规则引擎,搭建一套业务风控系统。
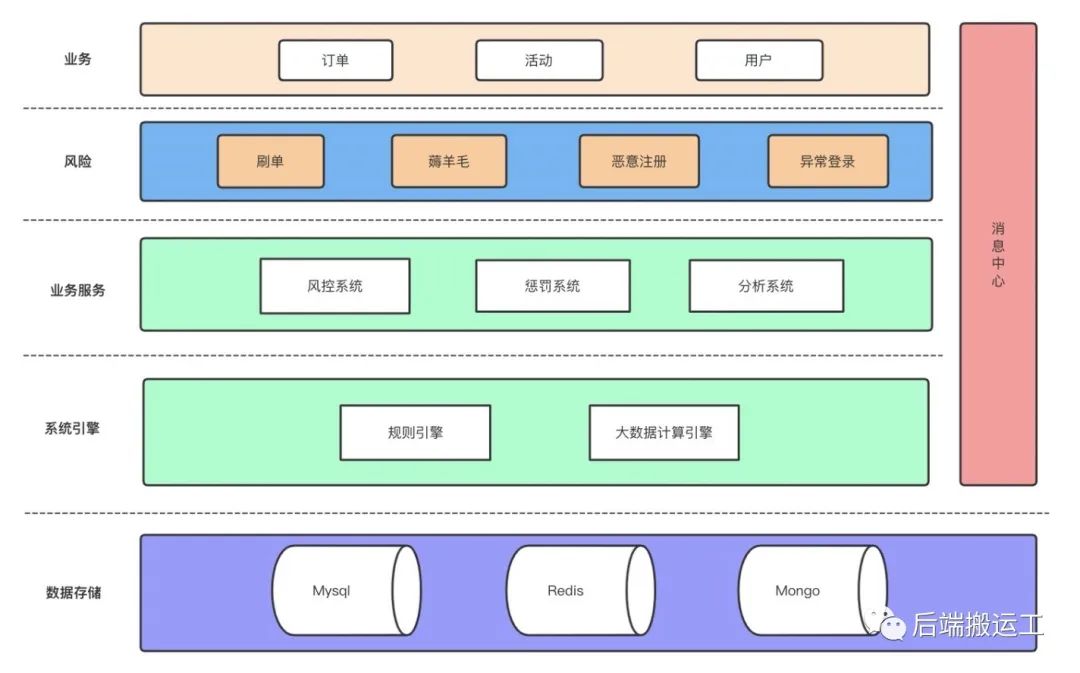
业务风险:刷单(订单)、薅羊毛(活动)、恶意注册和异常登录(用户)
业务服务:
风控系统:识别业务风险,根据业务或埋点数据判断当前用户或事件有无风险;
惩罚系统:对系统风险操作进行控制或惩罚,如禁止下单、增加验证码、限制登录;
分析系统(管理系统):提供系统管理和数据展示分析。系统管理如规则管理,分析业务数据如风险的订单,分析系统指标数据如某策略规则拦截率,以及时修正策略规则;
系统引擎:
规则引擎:策略规则的解析和执行,选用 B 站开源的 gengine(golang) 规则引擎;
大数据计算引擎:实时在线或离线计算业务指标数据,选用 Flink + Kafka 流计算引擎,指标数据存储在 Redis(数据异构)。各云厂商提供相应服务,如腾讯云流计算 Oceanus;
消息中心:各系统之间通过事件驱动,选用 Kafka
存储:
MySQL:风控规则等
Redis:指标数据
Mongo:操作日志、快照等
系统工作流程
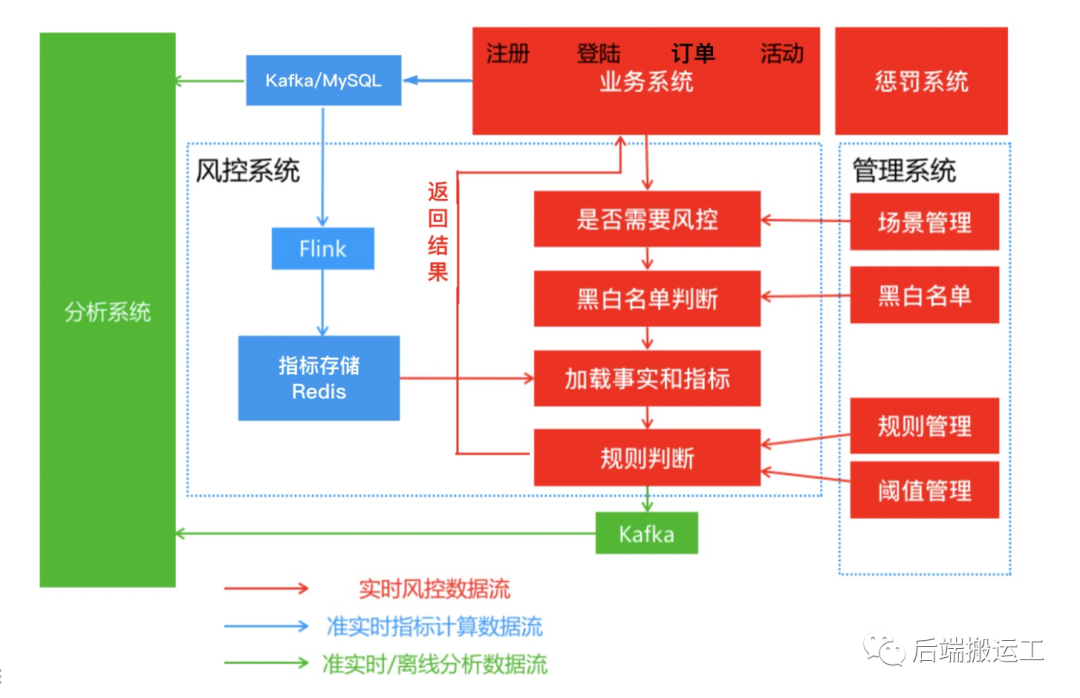
包含 3 个数据流。
实时风控数据流:由红线标识。业务同步调用风控系统,返回风险识别结果,并作相应惩罚,为系统核心链路;
准实时指标数据流:由蓝线标识。大数据计算引擎实时异步写入,准备业务指标数据并存储在 Redis,为系统准实时链路;
准实时/离线分析数据流:由绿线标识。异步写入,生成业务报表和评估风控系统表现的数据,以供进行数据分析;
风控规则抽象
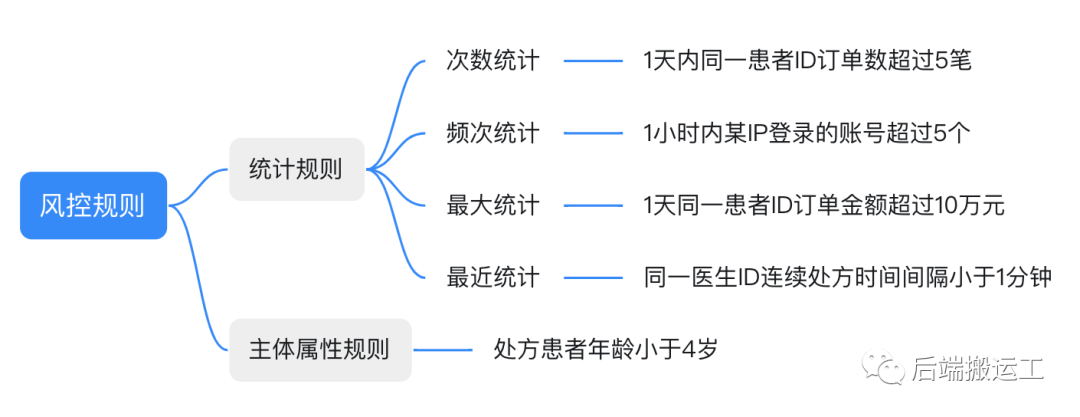
风控规则通常分 2 种,即统计规则和主体属性规则。都可以抽象为通用公式:
统计规则:{某时间段},{某主体} 在 {某个统计维度的结果} {比较操作符} {阈值}
主体属性规则:{主体}.{属性名}
下文将以 1天内同一患者ID订单数超过5笔 规则进行示例和说明。
大数据实时计算引擎
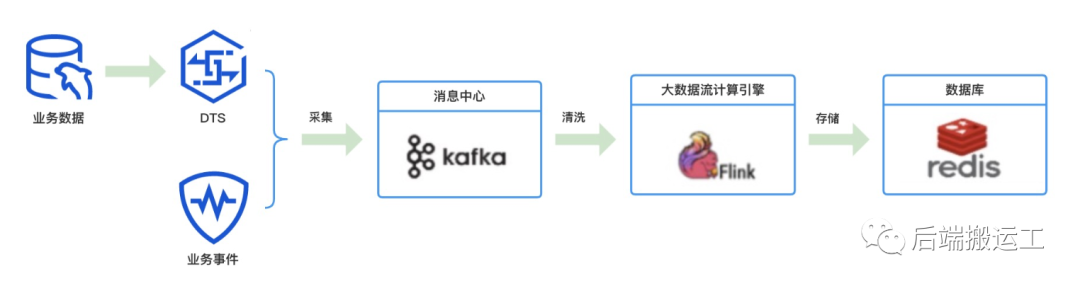
Flink 输入数据为 JSON 格式,Flink 的数据源有 2 种:
业务事件 -> Kafka -> Flink,业务事件需要转化为 JSON 消息格式
业务数据 -> DTS -> Kafka -> Flink,支持全量和增量读取数据
数据指标存储
指标数据异构,用空间换时间。Redis 的 zset 结构,通过 ZCOUNT key startTime endTime
操作即可统计任意时间段 startTime 至 endTime 内的统计需求。
| 规则 | 实现 | 写操作 | 读操作 |
|---|---|---|---|
1天内同一 患者ID订单数 超过5笔 | key:患者id value:订单id score:下单时间 | ZADD O(M*log(N) | ZCOUNT O(log(N)+M) |
形如 1天内同一患者ID订单数超过5笔 规则,数据指标存储格式:
risk:order-patient-id:123456|--111111 1652929153|--222222 1652932753|--333333 1652939953
统计指标为:
// startTime 和 endTime 对应为1天时间间隔ZCOUNT risk:order-patient-id:123456 1652940185 16528537853
随着时间的推移,zset 会出现元素越来越多的情况,后续可以通过定期升级 key 版本号的方式来解决,每次升级版本号之后需要批处理初始化所有指标数据。
创建指标数据实时计算作业
选用 Flink 的 SQL 作业类型,见 创建 SQL 作业。
形如 1天内同一患者ID订单数超过5笔 规则,定义源表和目标表是为了 SQL 中方便使用。
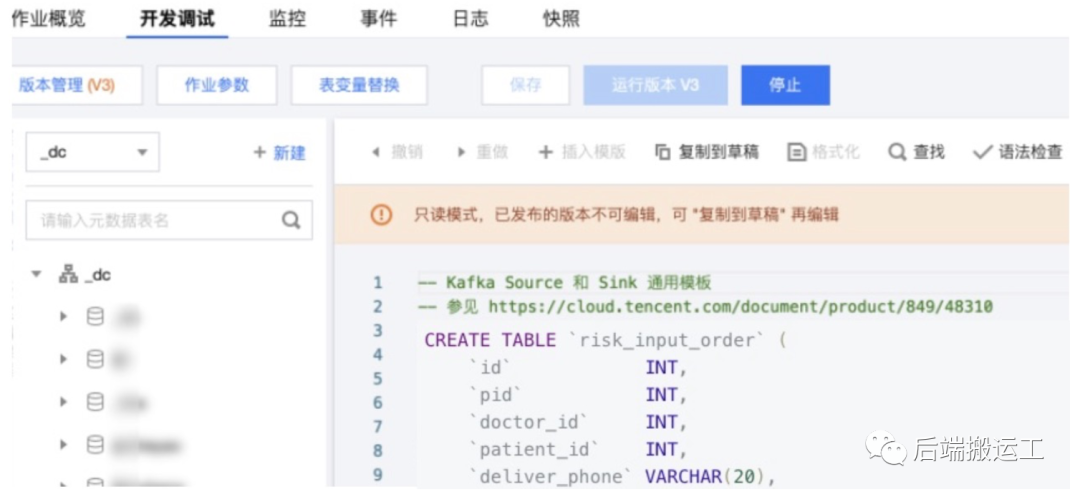
数据源表
定义 Kafka 数据源表,字段跟数据表一一对应映射。
CREATE TABLE `risk_input_order` (`id` INT,`pid` INT,`doctor_id` INT,`patient_id` INT,`deliver_phone` VARCHAR(20),`deliver_name` VARCHAR(20),`delivery_address` VARCHAR(200),`prescription_id` INT,`total_price` INT,`is_test` TINYINT,`created_at` TIMESTAMP) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'med_dts_b_convert', -- 消费的 Topic'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset earliest-offset specific-offsets group-offsets timestamp 的任何一种'properties.bootstrap.servers' = '172.0.0.1:9092', -- Kafka 连接地址'properties.group.id' = 'risk_input_order', -- 指定 Group ID-- 定义数据格式 (JSON 格式)'format' = 'json','json.fail-on-missing-field' = 'false', -- 遇到缺失字段不会报错'json.ignore-parse-errors' = 'true' -- 忽略任何解析报错);
目标表
定义 Redis 目标表,对应 ZADD key value score
操作写入数据。
CREATE TABLE `risk_output_order_patient_id` (`key` STRING,`value` STRING`score` DOUBLE) WITH ('connector' = 'redis','command' = 'zadd', -- redis zadd命令写入数据'nodes' = '172.0.0.1:6379', -- redis连接地址。'password' = 'yourpassword');
数据计算逻辑
直接使用 SQL 来清洗和合并数据。
-- 清洗患者id维度订单数据INSERT INTO risk_output_order_patient_idSELECTCONCAT('risk:order-patient-id:', patient_id) AS `key`,id AS value,UNIX_TIMESTAMP(created_at) AS scoreFROM risk_input_orderWHERE pid = 0;
流批一体(流处理和批处理一套逻辑)
在首次初始化指标数据或者新增数据指标的场景下,需要支持读取全量和增量数据,流批一体后,这样无需维护两套流程。
源表数据过期时间
其实要做到流批一体,只需要 Flink 源表历史数据的过期时间不小于指标数据统计周期即可。系统 Kafka 消息过期时间增大为 30 天,则指标数据统计周期最大也为 30 天(已经满足风控规则要求),因此系统是可以做到流批一体的。
初始化和新增指标数据
因为在风控场景,规则中的指标数据只需要最近统计周期时间的数据,可以直接重置 Kafka 消息位点来批处理源表历史数据,即可清洗出对应的指标数据。
CREATE TABLE `risk_input_order` () WITH (-- 定义 Kafka 参数'connector' = 'kafka','scan.startup.mode' = 'earliest-offset', -- 最早消费位点);
风控系统
封装规则引擎形成 risk-service 服务,供业务直接调用。
风险识别流程:
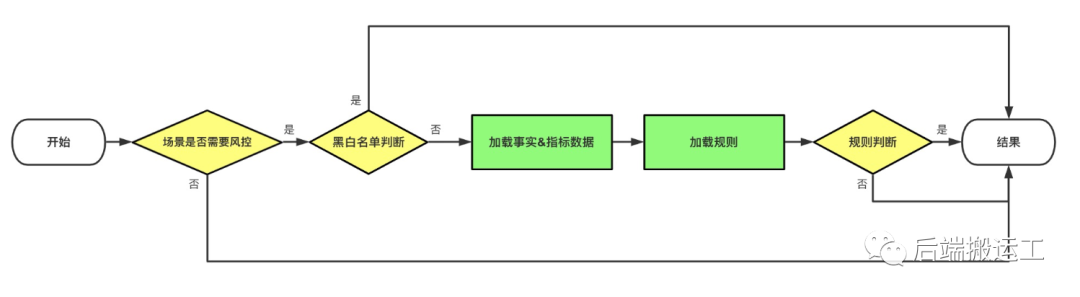
接口
对外提供业务风险识别接口、业务数据或事件上报接口。
// 订单风控service RiskOrder {// 风险识别rpc CheckRisk (CheckRiskReq) returns (CheckRiskResp);// 数据/事件上报rpc Report (ReportReq) returns (ReportResp);}
规则引擎
大量的规则形成规则集,规则集组成一颗决策树,决策树是规则引擎核心的判断逻辑。
规则体语法
是一种自定义的 DSL 语法。支持运算符、支持基础数据类型、支持条件语句、支持并发语句块、并支持结构体和方法注入。
// 规则名必须唯一rule "rulename" "rule-describtion" salience prioritybegin//规则体end
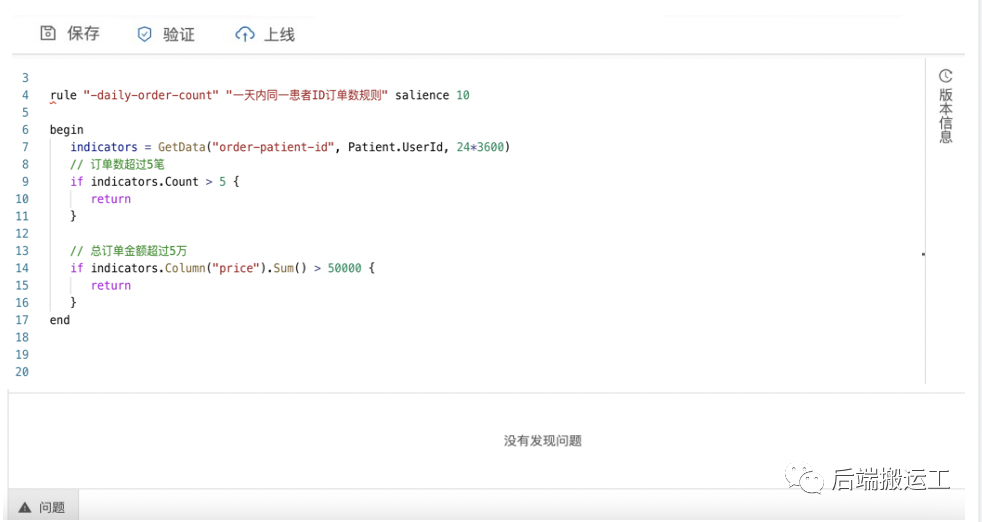
形如 一天内同一患者ID订单数超过5笔 规则,规则体语法为:
rule "pa-daily-order-count" "一天内同一患者ID订单数规则" salience 10beginif GetData("order-patient-id", Patient.UserId, 24*3600) > 5 {return // 命中规则}end
获取事实和指标数据
通过对规则引擎注入预定义的结构体和方法,可以实现在规则体中获取事实和指标数据。
事实数据
对规则引擎注入 User、Patient 结构体引用(指针),在规则体中通过 {主体}.{属性} 的方式即可获取到事实的某个属性。
// 获取事实数据user := xuser.GetUserInfo(userId)patient := xuser.GetPatientInfo(userId)dataContext := context.NewDataContext()// 事实数据注入dataContext.Add("User", user)dataContext.Add("Patient", patient)
指标数据
对规则引擎注入 GetData() 方法,参数是一个三元组,在规则体中通过 GetData(“指标名”, “主体id”, “时间周期”) 的方式即可获得指标数据。
// 获取指标数据函数func (s *DataService) GetData(indicator string, subjectId string, period int64) int64 {key := fmt.sprintf("risk:%s:%s", indicator, subjectId)endTime := time.Now().Unix()startTime := endTime - perioderr, res := redis.SCount(key, startTime, endTime)if err != nil {// 注入函数会忽略 error 返回值,通过错误标志来区分报错和默认值的情况s.SetError(err)return 0}return res}// 函数注入规则引擎dataContext := context.NewDataContext()dataSvc := &DataService{}dataContext.Add("GetData", dataSvc.GetData)
执行模式
支持并行模式和混合模式执行,目前只考虑并行模式。
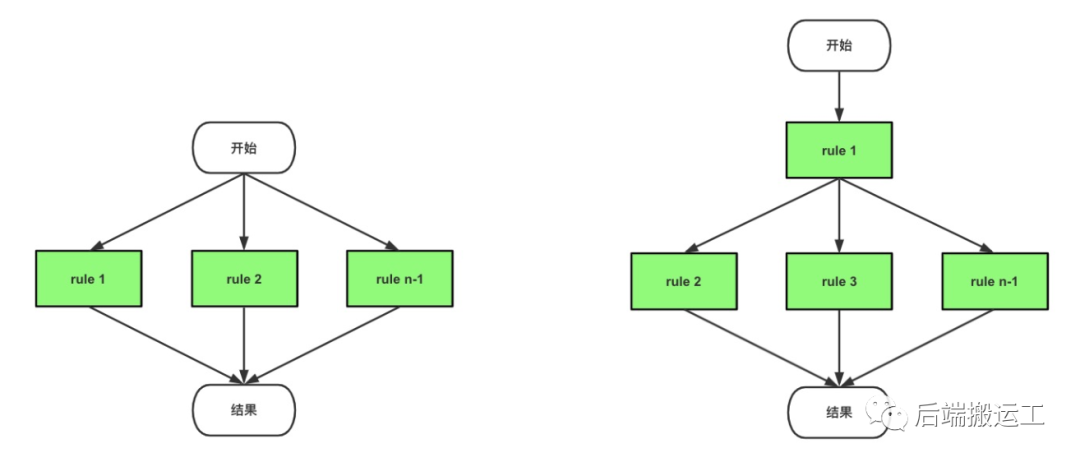
规则编译与执行
dataContext := context.NewDataContext()// 数据、函数注入var rules []string// rules from MySQL...// 规则编译ruleBuilder := builder.NewRuleBuilder(dataContext)for _, r := range rules {if err := ruleBuilder.BuildRuleWithIncremental(r); nil != err {return err}}// 规则并行模式执行eng := engine.NewGengine()if err := eng.ExecuteConcurrent(ruleBuilder); nil != err {return err}if dataSvc.HasError() {// 规则执行过程中,获取数据发生的报错return dataSvc.FirstError()}// 执行结果 map[命中规则ID]interface{}resMap, _ := eng.GetRulesResultMap()
管理系统
管理系统包含惩罚系统和分析系统。系统功能如下:
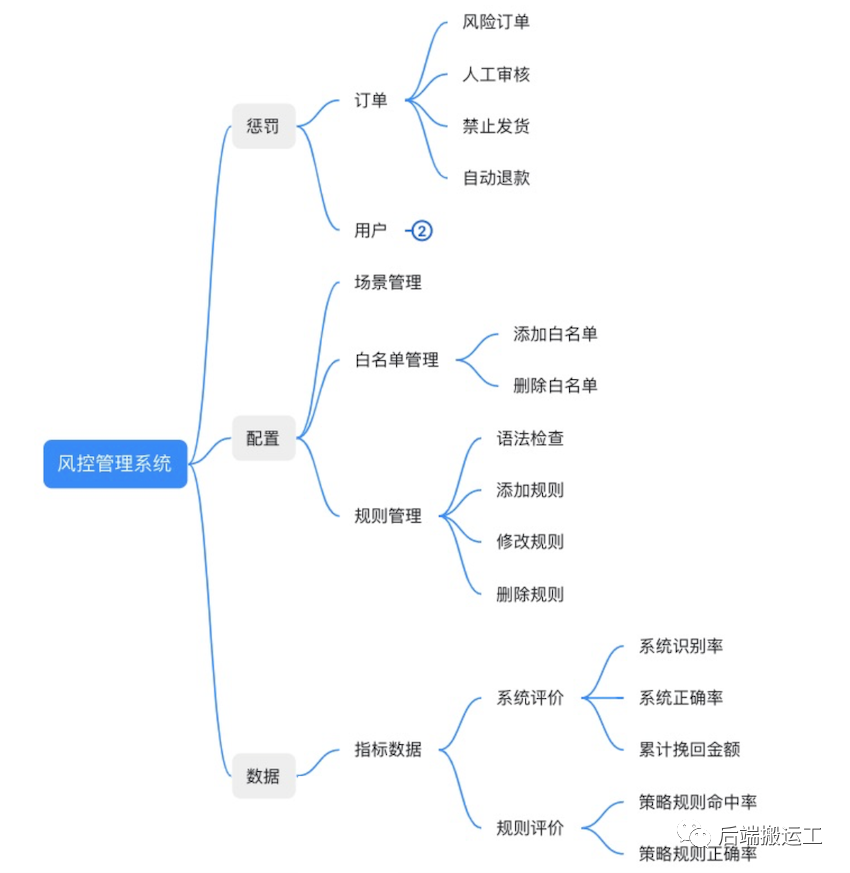
怎样发布一个规则
一个完整的风控规则发布流程:
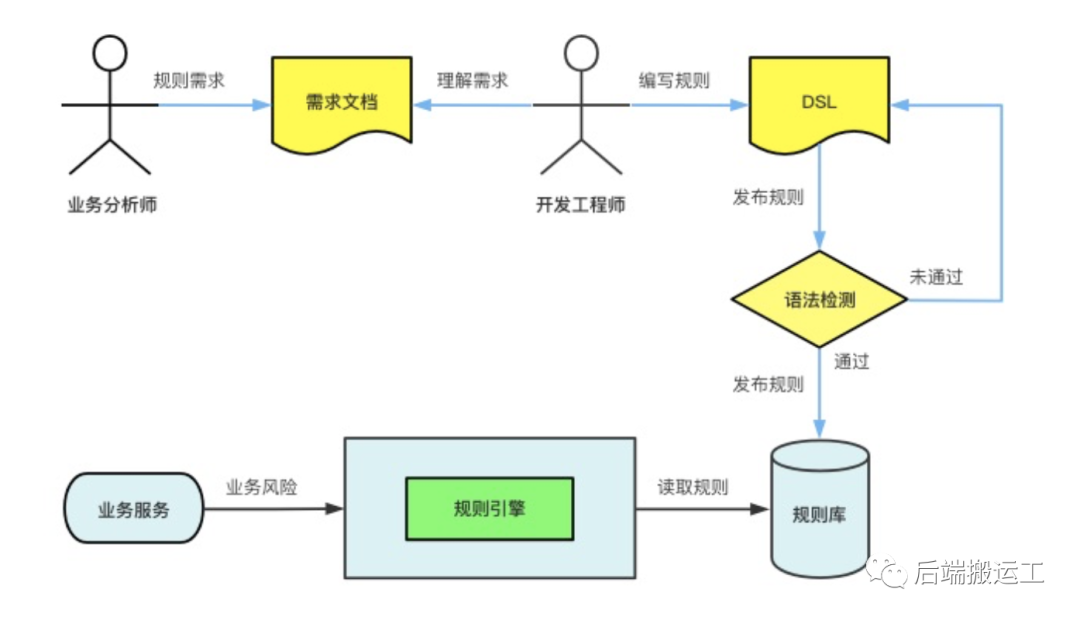
研发工程师可以在管理后台很方便地编写规则,并支持版本管理:
怎样接入一个新的业务风险
只需要做 2 件事:
生成业务指标数据
配置业务风控规则
系统降级
因为业务系统会同步调用风控系统进行风险识别,如果风控系统不可用时,则业务系统也不可用,因此需要系统降级措施。
关闭场景开关
紧急情况可关闭场景开关,业务风险识别接口则直接返回无风险。
