




从今天开始,我们将进入Redis系列的学习。由于Redis的快,Redis经常用在秒杀、分布式锁等高频方法场景,它是怎样做到快的呢?
大家第一反应肯定是:Redis是基于内存的存储中间键,对内存的操作当然相对于磁盘IO快多了。
除了利用内存的读写速度,Redis是如何高效的维护其数据结构的策略也是其“快”的原因。这一节我们将聊聊Redis是如何维护hash表的?
hash表
在Mysql系列章节中,我们已经提过hash表,哈希表是一种key-value键值对的存储数据结构。当数据量比较大时,不可避免的出现多个key哈希的结果是相同的,这个时候会拉出一个链表来存储多个value。数据存储示意图如下:
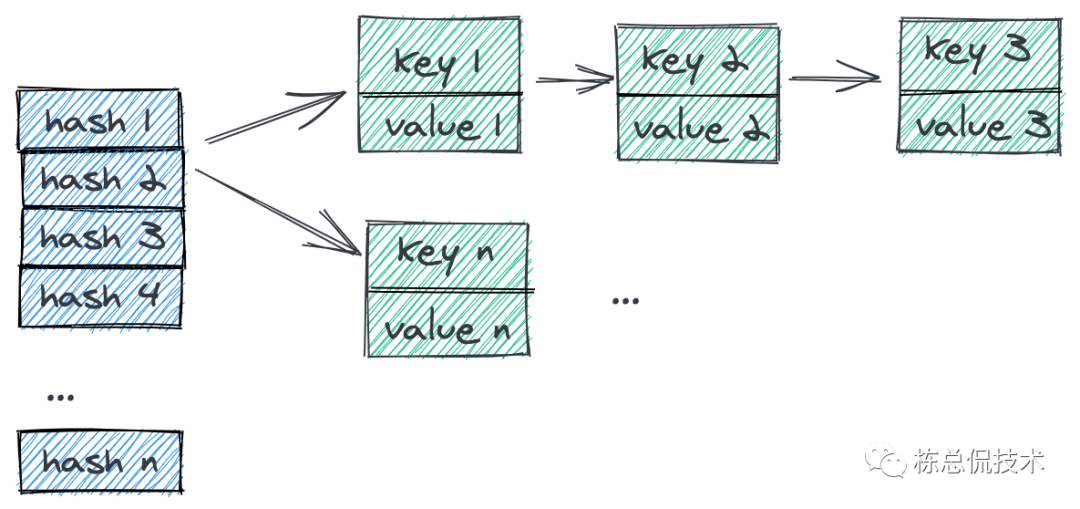
那么当hash表存储的数据愈来越多,越来越多的key哈希的结果一样,这样某个hash值下的链表就相当的长了,方法某个key其需要遍历的元素可能就类似访问链表了。当Hash表中产生的哈希冲突(负载因子)超过某个阈值时,出于性能考虑,Redis会进行rehash操作:
申请一片原来hash表(称为ht0)空间2倍的内存区域ht1
把表ht0中的数据重新映射到ht1
释放ht0的表空间
这里大家有没有发出疑问,此时ht0已经非常大了,如何把表ht0中的数据映射到ht1的呢?在映射的过程中对正常的业务有何影响呢?我们通过下面这张示意图来看下数据重新映射的过程:
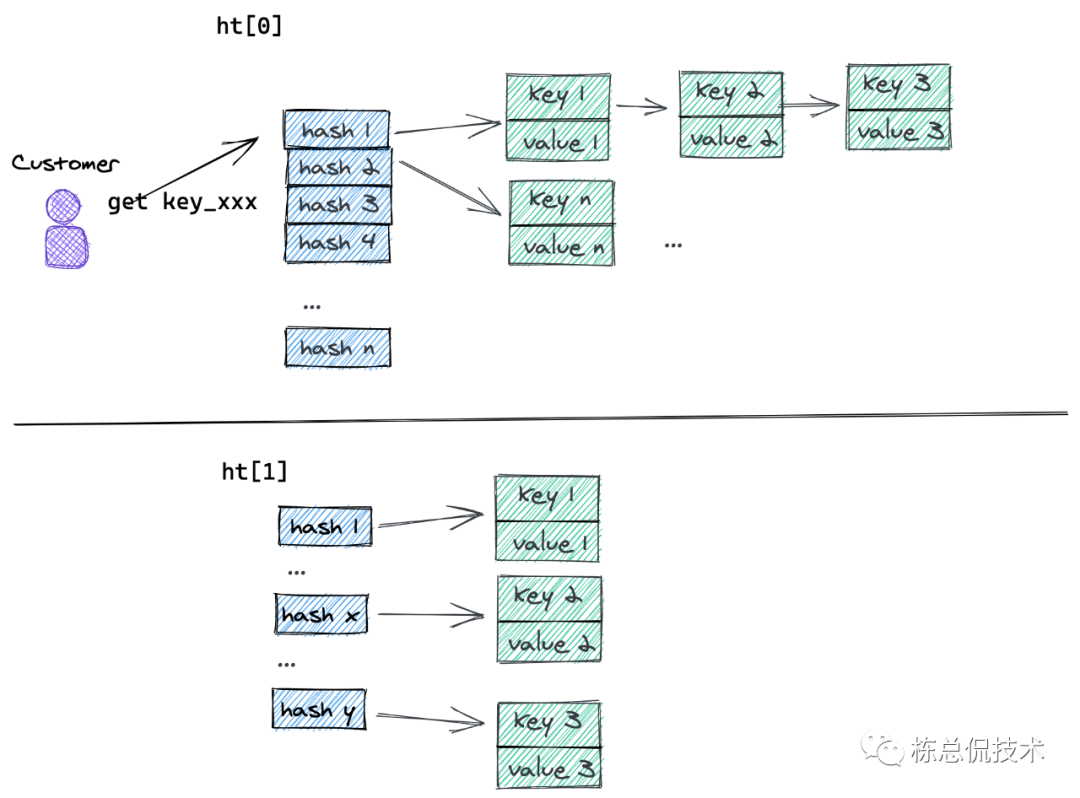
可以看到当用户访问某个key的时候,如果此时ht0正在rehash,那么会把hash0值中对应的所有键值对重新映射到ht1中,这个时候可以会把rehash到不同的hashkey对应的桶中。
那什么时候hash表会进行rehash操作呢?我们先来看下Redis中hash表的结构:
/* hash表结构定义 */typedef struct dictht {dictEntry **table; // 哈希表数组unsigned long size; // 哈希表的大小unsigned long sizemask; // 哈希表大小掩码unsigned long used; // 哈希表现有节点的数量} dictht;/* 哈希桶 */typedef struct dictEntry {void *key; // 键定义// 值定义union {void *val; // 自定义类型uint64_t u64; // 无符号整形int64_t s64; // 有符号整形double d; // 浮点型} v;struct dictEntry *next; //指向下一个哈希表节点} dictEntry;/* 哈希表 */typedef struct dict {dictType *type; // 字典类型void *privdata; // 私有数据dictht ht[2]; // 哈希表[两个]long rehashidx; // 记录rehash 进度的标志,值为-1表示rehash未进行int iterators; // 当前正在迭代的迭代器数} dict;
负载因子的计算公式:
load_factor = ht[0].used ht[0].size
当满足下列条件之一,Redis会进行rehash扩容操作
目前没有执行BGSAVE命令或者BGREWRITEAOF命令,且load_factor >1;
目前正在执行BGSAVE命令BGREWRITEAOF命令,且load_factor >5;
(BGSAVE命令和BGREWRITEAOF命令在后面的文章会介绍)
在扩容的时候,如果此时内存空间不足,就会有内存淘汰机制来淘汰在内存中的数据。这里是否想到了我们生产实践中遇到的Redis抖动呢,除了网络因素,机器CPU的占用,我们还可以得出Redis的rehash过程如果达到容量瓶颈也会使你的访问速度出现抖动。
所以,我们需要增加监控来预警内存不足。同时,在秒杀等活动前需要提前预估存储容量避免内存达到容量瓶颈。
在这一节我们了解了Redis是如何处理哈希表的扩容。如果hash表中数据大量被删除了,当 load_factor < 0.1 时,Redis也会进行进行缩容。下一节将会带来Redis怎样清理Key来完成缩容的过程的详细讲解。

