




概述
本实验搭建PostgreSQL一主两备一监证节点群集,使用repmgrd监控主备并自动切换,使用PgBouncer连接池连接主库,便于用户在主备切换时无感知。
部署架构
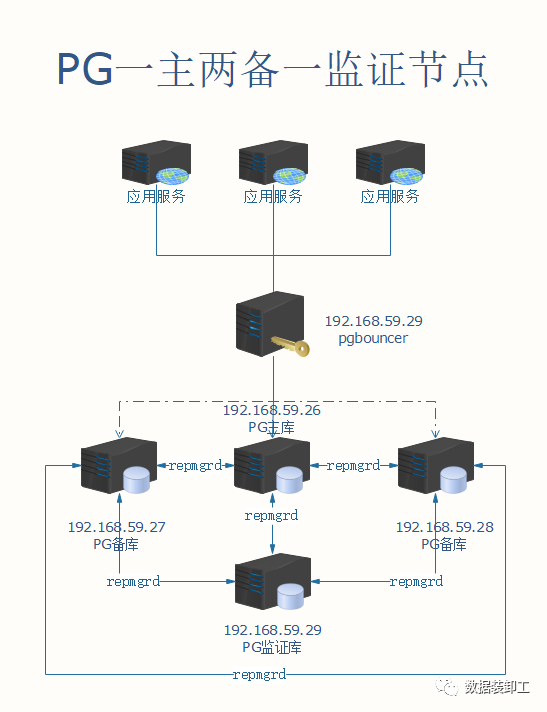
服务器信息
| 服务 | IP地址 | 主机名称 | 操作系统 | 安装服务 |
| 主节点 | 192.168.59.26 | node1 | CentOS 7.6 | PostgreSQL 14.4、repmgr 5.3.1 |
| 备节点 | 192.168.59.27 | node2 | CentOS 7.6 | PostgreSQL 14.4、repmgr 5.3.1 |
| 备节点 | 192.168.59.28 | node3 | CentOS 7.6 | PostgreSQL 14.4、repmgr 5.3.1 |
监证 节点 | 192.168.59.29 | node4 | CentOS 7.6 | PostgreSQL 14.4、repmgr 5.3.1 Pgbouncer 1.17.0 |
安装过程
1.四台主机关闭防火墙操作
如下操作在node1、node2、node3、node4都执行并重启
[root@node1 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@node1 ~]# systemctl stop firewalld.service
[root@node1 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
Aug 25 11:38:51 node1 systemd[1]: Starting firewalld - dynamic firewall daemon...
Aug 25 11:38:56 node1 systemd[1]: Started firewalld - dynamic firewall daemon.
Aug 25 11:54:09 node1 systemd[1]: Stopping firewalld - dynamic firewall daemon...
Aug 25 11:54:09 node1 systemd[1]: Stopped firewalld - dynamic firewall daemon.
[root@node1 ~]# sed -i '/^SELINUX=/d' /etc/selinux/config
[root@node1 ~]# echo "SELINUX=disabled" >> /etc/selinux/config
[root@node1 ~]# cat /etc/selinux/config|grep "SELINUX=disabled"
SELINUX=disabled2.配置四台主机postgres账号ssh互信
根据此篇脚本配置:多台Linux主机一键配置SSH互信
3.规划安装目录
以下目录需四台主机都创建
mkdir -p /opt/postgres/logs #日志目录
mkdir -p /opt/postgres/pgsql/ #PostgreSQL软件安装目录
mkdir -p /opt/postgres/data #PostgreSQL数据库目录
mkdir -p /opt/postgres/pgsql/etc/ #配置文件目录
chown postgres:postgres /opt/postgres/ -R #修改目录所属用户
在监证节点node4上还需创建Pgbouncer安装目录
mkdir -p /opt/postgres/pgbouncer #pgbouncer安装目录
mkdir -p /opt/postgres/pgbouncer/etc #pgbouncer配置文件目录
chown postgres:postgres /opt/postgres/pgbouncer/ -R #修改目录所属用户
4.软件下载
PostgreSQL-14.4:https://ftp.postgresql.org/pub/source/v14.4/postgresql-14.4.tar.gz
Pgbouncer 1.17.0:http://www.pgbouncer.org/downloads/files/1.17.0/pgbouncer-1.17.0.tar.gz
repmgr-5.3.1:https://codeload.github.com/EnterpriseDB/repmgr/zip/refs/heads/master
5.软件安装
node1、node2、node3、node4节点如下步骤安装PostgreSQL-14.4和repmgr-5.3.1
- PostgreSQL编译安装参考此篇:PostgreSQL在Linux下的两种安装方式
repmgr编译安装
使用root用户执行如下命令安装编译依赖包yum install -y yum-utils openjade docbook-dtds docbook-dsssl docbook-style-l flex libselinux-devel libxml2-devel libxslt-devel openssl-devel pam-devel readline-devel unzip zlib-devel readline-devel python perl perl-ExtUtils-Embed gcc python-devel
编译安装repmgr过程
[postgres@node1 repmgr-master]$ ./configure
checking for a sed that does not truncate output... /bin/sed
checking for pg_config... /opt/postgres/pgsql/bin/pg_config
configure: building against PostgreSQL 14.4
checking for gnused... no
checking for gsed... no
checking for sed... yes
configure: creating ./config.status
config.status: creating Makefile
config.status: creating Makefile.global
config.status: creating config.h
[postgres@node1 repmgr-master]$ make && make install
Building against PostgreSQL 14
gcc -std=gnu99 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fPIC -std=gnu89 -I/opt/postgres/pgsql/include/internal -I/opt/postgres/pgsql/include -Wall -Wmissing-prototypes -Wmissing-declarations -I. -I./ -I/opt/postgres/pgsql/include/server -I/opt/postgres/pgsql/include/internal -D_GNU_SOURCE -c -o repmgr.o repmgr.c
.
..
...
/bin/mkdir -p '/opt/postgres/pgsql/lib'
/bin/mkdir -p '/opt/postgres/pgsql/share/extension'
/bin/mkdir -p '/opt/postgres/pgsql/share/extension'
/bin/mkdir -p '/opt/postgres/pgsql/bin'
/bin/install -c -m 755 repmgr.so '/opt/postgres/pgsql/lib/repmgr.so'
/bin/install -c -m 644 .//repmgr.control '/opt/postgres/pgsql/share/extension/'
/bin/install -c -m 644 .//repmgr--unpackaged--4.0.sql .//repmgr--unpackaged--5.1.sql .//repmgr--unpackaged--5.2.sql .//repmgr--unpackaged--5.3.sql .//repmgr--4.0.sql .//repmgr--4.0--4.1.sql .//repmgr--4.1.sql .//repmgr--4.1--4.2.sql .//repmgr--4.2.sql .//repmgr--4.2--4.3.sql .//repmgr--4.3.sql .//repmgr--4.3--4.4.sql .//repmgr--4.4.sql .//repmgr--4.4--5.0.sql .//repmgr--5.0.sql .//repmgr--5.0--5.1.sql .//repmgr--5.1.sql .//repmgr--5.1--5.2.sql .//repmgr--5.2.sql .//repmgr--5.2--5.3.sql .//repmgr--5.3.sql .//repmgr--5.3--5.4.sql .//repmgr--5.4.sql '/opt/postgres/pgsql/share/extension/'
/bin/install -c -m 755 repmgr repmgrd '/opt/postgres/pgsql/bin/'
6.配置主库
在node1节点上配置主库
创建用于主从复制的repmgr用户和数据库
[postgres@node1 postgres]$ initdb
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /opt/postgres/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... PRC
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
pg_ctl -D /opt/postgres/data -l logfile start
[postgres@node1 postgres]$ pg_ctl start
waiting for server to start....2022-08-25 15:31:49.047 CST [9791] LOG: starting PostgreSQL 14.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
2022-08-25 15:31:49.047 CST [9791] LOG: listening on IPv6 address "::1", port 5432
2022-08-25 15:31:49.047 CST [9791] LOG: listening on IPv4 address "127.0.0.1", port 5432
2022-08-25 15:31:49.049 CST [9791] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2022-08-25 15:31:49.051 CST [9792] LOG: database system was shut down at 2022-08-25 15:31:43 CST
2022-08-25 15:31:49.053 CST [9791] LOG: database system is ready to accept connections
done
server started
[postgres@node1 postgres]$ psql
psql (14.4)
Type "help" for help.
postgres=# create user repmgr with superuser replication;
CREATE ROLE
postgres=# alter user repmgr with password 'repmgr';
ALTER ROLE
postgres=# create database repmgr owner repmgr;
CREATE DATABASE修改pg_hba.conf文件
[postgres@node1 data]$ cat pg_hba.conf
# PostgreSQL Client Authentication Configuration File
# ===================================================
.
..
...
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
host repmgr all 192.168.59.26/32 trust
host repmgr all 192.168.59.27/32 trust
host repmgr all 192.168.59.28/32 trust
host repmgr all 192.168.59.29/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
host replication all 192.168.59.26/32 trust
host replication all 192.168.59.27/32 trust
host replication all 192.168.59.28/32 trust
host replication all 192.168.59.29/32 trust修改postgresql.conf的如下参数
listen_addresses = '*'
port = 5432
max_connections = 1000
wal_log_hints = on
logging_collector = on
log_destination = 'stderr'
log_directory = '/opt/postgres/logs'
log_filename = 'postgresql-%Y-%m-%d.log'
shared_preload_libraries = 'repmgr'重启PostgreSQL数据库使修改的参数生效
[postgres@node1 data]$ pg_ctl stop
waiting for server to shut down....2022-08-25 15:40:27.254 CST [9821] LOG: received fast shutdown request
2022-08-25 15:40:27.255 CST [9821] LOG: aborting any active transactions
2022-08-25 15:40:27.256 CST [9821] LOG: background worker "logical replication launcher" (PID 9828) exited with exit code 1
2022-08-25 15:40:27.256 CST [9823] LOG: shutting down
2022-08-25 15:40:27.266 CST [9821] LOG: database system is shut down
done
server stopped
[postgres@node1 data]$ pg_ctl start
waiting for server to start....2022-08-25 15:40:31.499 CST [9835] LOG: redirecting log output to logging collector process
2022-08-25 15:40:31.499 CST [9835] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started生成repmgr.conf文件
[postgres@node1 postgres]$ cp /opt/postgres/repmgr-master/repmgr.conf.sample /opt/postgres/pgsql/etc/repmgr.conf
修改repmgr.conf的参数如下
###################################################
# repmgr sample configuration file
###################################################
node_id=1 # A unique integer greater than zero
node_name='node1' # An arbitrary (but unique) string; we recommend
conninfo='host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2' # Database connection information as a conninfo string.
data_directory='/opt/postgres/data' # The node's data directory. This is needed by repmgr
config_directory='/opt/postgres/data' # If configuration files are located outside the data
log_level='INFO' # Log level: possible values are DEBUG, INFO, NOTICE,
log_facility='STDERR' # Logging facility: possible values are STDERR, or for
log_file='/opt/postgres/logs/repmgr-node1.log' # STDERR can be redirected to an arbitrary file
#------------------------------------------------------------------------------
# Environment/command settings
#------------------------------------------------------------------------------
pg_bindir='/opt/postgres/pgsql/bin' # Path to PostgreSQL binary directory (location
repmgr_bindir='/opt/postgres/pgsql/bin' # Path to repmgr binary directory (location of the repmgr
#------------------------------------------------------------------------------
# external command options
#------------------------------------------------------------------------------
priority=3 # indicates a preferred priority for promoting nodes;
reconnect_attempts=6 # Number of attempts which will be made to reconnect to an unreachable
reconnect_interval=10 # Interval between attempts to reconnect to an unreachablenode1节点注册为主服务
[postgres@node1 etc]$ repmgr primary register
INFO: connecting to primary database...
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (ID: 1) registered
[postgres@node1 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | * running | | default | 3 | 1 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
开启node1的repmgr主库守护进程并查看日志
[postgres@node1 etc]$ ps -uax|grep repmgrd
postgres 9862 0.0 0.0 112816 984 pts/2 R+ 15:46 0:00 grep --color=auto repmgrd
[postgres@node1 etc]$ repmgrd -d
[2022-08-25 15:46:31] [NOTICE] redirecting logging output to "/opt/postgres/logs/repmgr-node1.log"
[postgres@node1 etc]$ cat /opt/postgres/logs/repmgr-node1.log
[2022-08-25 15:46:31] [NOTICE] repmgrd (repmgrd 5.4dev) starting up
[2022-08-25 15:46:31] [INFO] connecting to database "host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2"
INFO: set_repmgrd_pid(): provided pidfile is /tmp/repmgrd.pid
[2022-08-25 15:46:31] [NOTICE] starting monitoring of node "node1" (ID: 1)
[2022-08-25 15:46:31] [INFO] "connection_check_type" set to "ping"
[2022-08-25 15:46:31] [NOTICE] monitoring cluster primary "node1" (ID: 1)
[postgres@node1 etc]$ ps -uax|grep repmgrd
postgres 9866 0.0 0.0 13360 1056 ? S 15:46 0:00 repmgrd -d
postgres 9884 0.0 0.0 112816 984 pts/2 S+ 15:46 0:00 grep --color=auto repmgrd
7.配置备库
在node2、node3上配置备库,如下操作node2、node3节点都需要执行
修改/opt/postgres/data/pg_hba.conf文件
[postgres@node2 data]$ cat pg_hba.conf
# PostgreSQL Client Authentication Configuration File
# ===================================================
.
..
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
host repmgr all 192.168.59.26/32 trust
host repmgr all 192.168.59.27/32 trust
host repmgr all 192.168.59.28/32 trust
host repmgr all 192.168.59.29/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
host replication all 192.168.59.26/32 trust
host replication all 192.168.59.27/32 trust
host replication all 192.168.59.28/32 trust
host replication all 192.168.59.29/32 trust
修改/opt/postgres/data/postgresql.conf的如下参数
listen_addresses = '*'
port = 5432
max_connections = 1000
wal_log_hints = on
logging_collector = on
log_destination = 'stderr'
log_directory = '/opt/postgres/logs'
log_filename = 'postgresql-%Y-%m-%d.log'
shared_preload_libraries = 'repmgr'重启PostgreSQL数据库使修改的参数生效
[postgres@node2 data]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
[postgres@node2 data]$ pg_ctl start
waiting for server to start....2022-08-25 15:54:09.434 CST [7777] LOG: redirecting log output to logging collector process
2022-08-25 15:54:09.434 CST [7777] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started从样例中生成repmgr.conf文件
[postgres@node3 etc]$ cp /opt/postgres/repmgr-master/repmgr.conf.sample /opt/postgres/pgsql/etc/repmgr.conf
修改node2的repmgr.conf如下:
###################################################
# repmgr sample configuration file
###################################################
node_id=2
node_name='node2'
conninfo='host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2'
data_directory='/opt/postgres/data'
config_directory='/opt/postgres/data'
log_level='INFO'
log_facility='STDERR'
log_file='/opt/postgres/logs/repmgr-node2.log'
#------------------------------------------------------------------------------
# Environment/command settings
#------------------------------------------------------------------------------
pg_bindir='/opt/postgres/pgsql/bin'
repmgr_bindir='/opt/postgres/pgsql/bin'
#------------------------------------------------------------------------------
# external command options
#------------------------------------------------------------------------------
priority=2
reconnect_attempts=6
reconnect_interval=10修改node3节点repmgr.conf参数如下:
###################################################
# repmgr sample configuration file
###################################################
node_id=3
node_name='node3'
conninfo='host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2'
data_directory='/opt/postgres/data'
config_directory='/opt/postgres/data'
log_level='INFO'
log_facility='STDERR'
log_file='/opt/postgres/logs/repmgr-node3.log'
#------------------------------------------------------------------------------
# Environment/command settings
#------------------------------------------------------------------------------
pg_bindir='/opt/postgres/pgsql/bin'
repmgr_bindir='/opt/postgres/pgsql/bin'
#------------------------------------------------------------------------------
# external command options
#------------------------------------------------------------------------------
priority=2
reconnect_attempts=6
reconnect_interval=10node2、node3上分别关闭数据库
[postgres@node2 etc]$ pg_ctl stop
waiting for server to shut down.... done
server stopped在node2、node3使用--dry-run选项检查待机是否可以克隆
[postgres@node2 etc]$ repmgr -h 192.168.59.26 -U repmgr -d repmgr standby clone --dry-run
WARNING: following problems with command line parameters detected:
"config_directory" set in repmgr.conf, but --copy-external-config-files not provided
NOTICE: destination directory "/opt/postgres/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=192.168.59.26 user=repmgr dbname=repmgr
DETAIL: current installation size is 33 MB
INFO: "repmgr" extension is installed in database "repmgr"
WARNING: target data directory appears to be a PostgreSQL data directory
DETAIL: target data directory is "/opt/postgres/data"
HINT: use -F/--force to overwrite the existing data directory
INFO: replication slot usage not requested; no replication slot will be set up for this standby
INFO: parameter "max_wal_senders" set to 10
NOTICE: checking for available walsenders on the source node (2 required)
INFO: sufficient walsenders available on the source node
DETAIL: 2 required, 10 available
NOTICE: checking replication connections can be made to the source server (2 required)
INFO: required number of replication connections could be made to the source server
DETAIL: 2 replication connections required
NOTICE: standby will attach to upstream node 1
HINT: consider using the -c/--fast-checkpoint option
INFO: would execute:
/opt/postgres/pgsql/bin/pg_basebackup -l "repmgr base backup" -D /opt/postgres/data -h 192.168.59.26 -p 5432 -U repmgr -X stream
INFO: all prerequisites for "standby clone" are met
在node2、node3上执行如下操作克隆node1节点主数据库
[postgres@node2 etc]$ repmgr -h 192.168.59.26 -U repmgr -d repmgr standby clone -F
WARNING: following problems with command line parameters detected:
"config_directory" set in repmgr.conf, but --copy-external-config-files not provided
NOTICE: destination directory "/opt/postgres/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=192.168.59.26 user=repmgr dbname=repmgr
DETAIL: current installation size is 33 MB
INFO: replication slot usage not requested; no replication slot will be set up for this standby
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
WARNING: directory "/opt/postgres/data" exists but is not empty
NOTICE: -F/--force provided - deleting existing data directory "/opt/postgres/data"
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
INFO: executing:
/opt/postgres/pgsql/bin/pg_basebackup -l "repmgr base backup" -D /opt/postgres/data -h 192.168.59.26 -p 5432 -U repmgr -X stream
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /opt/postgres/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"在node2、node3上启动备库,并注册为standby
[postgres@node2 etc]$ pg_ctl start
waiting for server to start....2022-08-25 16:03:49.805 CST [7810] LOG: redirecting log output to logging collector process
2022-08-25 16:03:49.805 CST [7810] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started
[postgres@node2 etc]$ repmgr standby register
INFO: connecting to local node "node2" (ID: 2)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID: 1)
INFO: standby registration complete
NOTICE: standby node "node2" (ID: 2) successfully registered在node2上启动repmgr守护进程,查看主从信息
[postgres@node2 etc]$ ps -uax|grep repmgrd
postgres 7863 0.0 0.0 112816 980 pts/1 R+ 16:06 0:00 grep --color=auto repmgrd
[postgres@node2 etc]$ repmgrd -d
[2022-08-25 16:06:15] [NOTICE] redirecting logging output to "/opt/postgres/logs/repmgr-node2.log"
[postgres@node2 etc]$ cat /opt/postgres/logs/repmgr-node2.log
[2022-08-25 16:06:15] [NOTICE] repmgrd (repmgrd 5.4dev) starting up
[2022-08-25 16:06:15] [INFO] connecting to database "host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2"
INFO: set_repmgrd_pid(): provided pidfile is /tmp/repmgrd.pid
[2022-08-25 16:06:15] [NOTICE] starting monitoring of node "node2" (ID: 2)
[2022-08-25 16:06:15] [INFO] "connection_check_type" set to "ping"
[2022-08-25 16:06:15] [INFO] monitoring connection to upstream node "node1" (ID: 1)
[postgres@node2 etc]$ ps -aux|grep repmgrd
postgres 7867 0.0 0.0 13360 1104 ? S 16:06 0:00 repmgrd -d
postgres 7880 0.0 0.0 112816 984 pts/1 R+ 16:06 0:00 grep --color=auto repmgrd
[postgres@node2 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | * running | | default | 3 | 1 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | standby | running | node1 | default | 2 | 1 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
node3上启动repmgr守护进程,查看主从信息
[postgres@node3 etc]$ pg_ctl start
waiting for server to start....2022-08-25 16:18:36.781 CST [2040] LOG: redirecting log output to logging collector process
2022-08-25 16:18:36.781 CST [2040] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started
[postgres@node3 etc]$ repmgr standby register
INFO: connecting to local node "node3" (ID: 3)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID: 1)
INFO: standby registration complete
NOTICE: standby node "node3" (ID: 3) successfully registered
[postgres@node3 etc]$ ps -aux|grep repmgrd
postgres 2050 0.0 0.0 112816 984 pts/1 R+ 16:18 0:00 grep --color=auto repmgrd
[postgres@node3 etc]$ repmgrd -d
[2022-08-25 16:19:01] [NOTICE] redirecting logging output to "/opt/postgres/logs/repmgr-node3.log"
[postgres@node3 etc]$ cat /opt/postgres/logs/repmgr-node3.log
[2022-08-25 16:19:01] [NOTICE] repmgrd (repmgrd 5.4dev) starting up
[2022-08-25 16:19:01] [INFO] connecting to database "host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2"
INFO: set_repmgrd_pid(): provided pidfile is /tmp/repmgrd.pid
[2022-08-25 16:19:01] [NOTICE] starting monitoring of node "node3" (ID: 3)
[2022-08-25 16:19:01] [INFO] "connection_check_type" set to "ping"
[2022-08-25 16:19:01] [INFO] monitoring connection to upstream node "node1" (ID: 1)
[postgres@node3 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | * running | | default | 3 | 1 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | standby | running | node1 | default | 2 | 1 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | node1 | default | 2 | 1 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
[postgres@node3 etc]$ ps -uax|grep repmgrd
postgres 2054 0.0 0.0 13360 1104 ? S 16:19 0:00 repmgrd -d
postgres 2093 0.0 0.0 112816 984 pts/1 R+ 16:20 0:00 grep --color=auto repmgrd
测主备同步
主库操作
[postgres@node1 etc]$ psql
psql (14.4)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
repmgr | repmgr | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(4 rows)
postgres=# create database test;
CREATE DATABASE
postgres=# \c test;
You are now connected to database "test" as user "postgres".
test=# \d
Did not find any relations.
test=# create table t (id int,name varchar(50));
CREATE TABLE
test=# insert into t values (1,'deitylee');
INSERT 0 1
test=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t | table | postgres
(1 row)
test=# select * from t;
id | name
----+----------
1 | deitylee
(1 row)
test=#
备库可以查询到主库创建的表和写入的数据,主备同步建立成功
[postgres@node2 ~]$ psql
psql (14.4)
Type "help" for help.
postgres=# \d
Did not find any relations.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
repmgr | repmgr | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(5 rows)
postgres=# \c test;
You are now connected to database "test" as user "postgres".
test=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t | table | postgres
(1 row)
test=# select * from t;
id | name
----+----------
1 | deitylee
(1 row)8.配置监证节点
先初始化数据库
[postgres@node4 postgres]$ initdb
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /opt/postgres/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... PRC
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
pg_ctl -D /opt/postgres/data -l logfile start修改/opt/postgres/data/pg_hba.conf文件
[postgres@node4 data]$ cat pg_hba.conf
# PostgreSQL Client Authentication Configuration File
# ===================================================
.
..
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
host repmgr all 192.168.59.26/32 trust
host repmgr all 192.168.59.27/32 trust
host repmgr all 192.168.59.28/32 trust
host repmgr all 192.168.59.29/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
host replication all 192.168.59.26/32 trust
host replication all 192.168.59.27/32 trust
host replication all 192.168.59.28/32 trust
host replication all 192.168.59.29/32 trust
启动数据库服务
[postgres@node4 data]$ pg_ctl start
waiting for server to start....2022-08-22 15:18:40.035 CST [2873] LOG: starting PostgreSQL 14.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
2022-08-22 15:18:40.036 CST [2873] LOG: listening on IPv6 address "::1", port 5432
2022-08-22 15:18:40.036 CST [2873] LOG: listening on IPv4 address "127.0.0.1", port 5432
2022-08-22 15:18:40.037 CST [2873] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2022-08-22 15:18:40.040 CST [2874] LOG: database system was shut down at 2022-08-22 15:17:48 CST
2022-08-22 15:18:40.041 CST [2873] LOG: database system is ready to accept connections
done
server started创建repmgr账号及数据库
[postgres@node4 data]$ psql
psql (14.4)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=# create user repmgr with superuser replication;
CREATE ROLE
postgres=# create database repmgr owner repmgr
postgres-# ;
CREATE DATABASE修改/opt/postgres/data/postgresql.conf的如下参数
listen_addresses = '*'
port = 5432
log_destination = 'stderr'
logging_collector = on
log_directory = '/opt/postgres/logs'
log_filename = 'postgresql-%Y-%m-%d.log'
shared_preload_libraries = 'repmgr重启PostgreSQL数据库使修改的参数生效
[postgres@node4 data]$ pg_ctl stop
waiting for server to shut down....2022-08-25 16:30:55.359 CST [2367] LOG: received fast shutdown request
2022-08-25 16:30:55.360 CST [2367] LOG: aborting any active transactions
2022-08-25 16:30:55.361 CST [2367] LOG: background worker "logical replication launcher" (PID 2374) exited with exit code 1
2022-08-25 16:30:55.361 CST [2369] LOG: shutting down
2022-08-25 16:30:55.368 CST [2367] LOG: database system is shut down
done
server stopped
[postgres@node4 data]$ pg_ctl start
waiting for server to start....2022-08-25 16:30:59.518 CST [2384] LOG: redirecting log output to logging collector process
2022-08-25 16:30:59.518 CST [2384] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started从样例中生成repmgr.conf文件
[postgres@node4 etc]$cp /opt/postgres/repmgr-master/repmgr.conf.sample /opt/postgres/pgsql/etc/repmgr.conf
修改node4的repmgr.conf如下:
###################################################
# repmgr sample configuration file
###################################################
node_id=4
node_name='node4'
conninfo='host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2'
data_directory='/opt/postgres/data'
config_directory='/opt/postgres/data'
log_level='INFO'
log_facility='STDERR'
log_file='/opt/postgres/logs/repmgr-node4.log'
#------------------------------------------------------------------------------
# Environment/command settings
#------------------------------------------------------------------------------
pg_bindir='/opt/postgres/pgsql/bin'
repmgr_bindir='/opt/postgres/pgsql/bin'
#------------------------------------------------------------------------------
# external command options
#------------------------------------------------------------------------------
monitoring_history=true
primary_visibility_consensus=truenode4重启数据库服务
[postgres@node4 etc]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
[postgres@node4 etc]$ pg_ctl start
waiting for server to start....2022-08-22 15:26:30.934 CST [2908] LOG: redirecting log output to logging collector process
2022-08-22 15:26:30.934 CST [2908] HINT: Future log output will appear in directory "/opt/postgres/logs".
done
server started注册node4节点为监证节点
[postgres@node4 etc]$ repmgr witness register -h 192.168.59.26 -d repmgr
INFO: connecting to witness node "node4" (ID: 4)
INFO: connecting to primary node
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
INFO: witness registration complete
NOTICE: witness node "node4" (ID: 4) successfully registered在node4节点上查看群集信息
[postgres@node4 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | * running | | default | 3 | 1 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | standby | running | node1 | default | 2 | 1 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | node1 | default | 2 | 1 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
4 | node4 | witness | * running | node1 | default | 0 | n/a | host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2
在node4上启动repmgr守护进程
[postgres@node4 etc]$ ps -uax|grep repmgrd
postgres 2474 0.0 0.0 112816 984 pts/1 R+ 16:39 0:00 grep --color=auto repmgrd
[postgres@node4 etc]$ repmgrd -d
[2022-08-25 16:39:17] [NOTICE] redirecting logging output to "/opt/postgres/logs/repmgr-node4.log"
[postgres@node4 etc]$ cat /opt/postgres/logs/repmgr-node4.log
[2022-08-25 16:39:17] [NOTICE] repmgrd (repmgrd 5.4dev) starting up
[2022-08-25 16:39:17] [INFO] connecting to database "host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2"
INFO: set_repmgrd_pid(): provided pidfile is /tmp/repmgrd.pid
[2022-08-25 16:39:17] [NOTICE] starting monitoring of node "node4" (ID: 4)
[2022-08-25 16:39:17] [INFO] "connection_check_type" set to "ping"
[2022-08-25 16:39:17] [INFO] witness monitoring connection to primary node "node1" (ID: 1)
[postgres@node4 etc]$ ps -uax|grep repmgrd
postgres 2478 0.0 0.0 13360 1112 ? S 16:39 0:00 repmgrd -d
postgres 2506 0.0 0.0 112816 984 pts/1 R+ 16:39 0:00 grep --color=auto repmgrd9.安装pgbouncer配置连接池
编译安装pgbouncer
[postgres@node4 postgres]$ tar -zxvf pgbouncer-1.17.0.tar.gz
pgbouncer-1.17.0/
pgbouncer-1.17.0/win32/
.
..
...
pgbouncer-1.17.0/src/server.c
[postgres@node4 postgres]$ cd pgbouncer-1.17.0
[postgres@node4 pgbouncer-1.17.0]$ ls
AUTHORS autogen.sh config.guess config.mak.in config.sub configure configure.ac COPYRIGHT doc etc include install-sh lib Makefile NEWS.md README.md src test win32
[postgres@node4 pgbouncer-1.17.0]$ ./configure --prefix=/opt/postgres/pgbouncer
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking target host type... unix
.
..
...
checking whether to fail on warnings... no
configure: creating ./config.status
config.status: creating config.mak
config.status: creating lib/usual/config.h
Results:
adns = c-ares
pam = no
systemd = no
tls = yes
[postgres@node4 pgbouncer-1.17.0]$ make && make install
CC src/admin.c
CC src/client.c
CC src/dnslookup.c
src/dnslookup.c: In function ‘impl_launch_query’:
src/dnslookup.c:905:2: warning: #warning c-ares <=1.10 has buggy IPv6 support; this PgBouncer build will use IPv4 only. [-Wcpp]
#warning c-ares <=1.10 has buggy IPv6 support; this PgBouncer build will use IPv4 only.
^
CC src/hba.c
.
..
...
INSTALL pgbouncer /opt/postgres/pgbouncer/bin
INSTALL README.md /opt/postgres/pgbouncer/share/doc/pgbouncer
INSTALL NEWS.md /opt/postgres/pgbouncer/share/doc/pgbouncer
INSTALL etc/pgbouncer.ini /opt/postgres/pgbouncer/share/doc/pgbouncer
INSTALL etc/userlist.txt /opt/postgres/pgbouncer/share/doc/pgbouncer
INSTALL doc/pgbouncer.1 /opt/postgres/pgbouncer/share/man/man1
INSTALL doc/pgbouncer.5 /opt/postgres/pgbouncer/share/man/man5 从示例复制pgbouncer.ini和userlist.txt文件并修改权限
[postgres@node4 pgbouncer]$ cp /opt/postgres/pgbouncer/share/doc/pgbouncer/pgbouncer.ini /opt/postgres/pgbouncer/etc/
[postgres@node4 pgbouncer]$ cp /opt/postgres/pgbouncer/share/doc/pgbouncer/userlist.txt /opt/postgres/pgbouncer/etc/
[postgres@node4 pgbouncer]$ cd etc
[postgres@node4 etc]$ ls
pgbouncer.ini userlist.txt
[postgres@node4 etc]$ vi pgbouncer.ini
[postgres@node4 etc]$ chmod 700 userlist.txt修改pgbouncer.ini参数如下
[databases]
masterdb = host=192.168.59.26 user=repmgr port=5432 dbname=repmgr
[pgbouncer]
logfile = /opt/postgres/logs/pgbouncer.log
pidfile = /opt/postgres/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = trust
auth_file = /opt/postgres/pgbouncer/etc/userlist.txt
admin_users = pgbouncer
pool_mode = session
max_client_conn = 1000
default_pool_size = 25
reserve_pool_size = 5userlist.txt内容如下
"marko" "asdasd"
"postgres" "postgres"
"pgbouncer" "pgbouncer"启动pgbouncer服务
[postgres@node4 bin]$ ./pgbouncer -d /opt/postgres/pgbouncer/etc/pgbouncer.ini
[postgres@node4 bin]$ ps -uax|grep pgbouncer
postgres 9968 0.0 0.0 43452 1616 ? S 16:00 0:00 ./pgbouncer -d /opt/postgres/pgbouncer/etc/pgbouncer.ini
postgres 9973 0.0 0.0 112816 980 pts/0 S+ 16:00 0:00 grep --color=auto pgbouncer连接测试连接的名称为pgbouncer.ini定义的masterdb名称
[postgres@node4 etc]$ psql -p 6432 -h 192.168.59.29 masterdb
psql (14.4)
Type "help" for help.
masterdb=# \c
You are now connected to database "masterdb" as user "postgres".
masterdb=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
repmgr | repmgr | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
vzoom | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(5 rows)
masterdb=# SELECT CURRENT_USER usr,inet_server_addr() host ,inet_server_port() port;
usr | host | port
--------+---------------+------
repmgr | 192.168.59.26 | 5432
(1 row)10.配置主备自动切换,并使pgbouncer连接到新的主库
编写failover.sh脚本在主备切换时使用
脚本内容如下,其中MASTER_IP在node1、node2、node3上为本地对应IP地址。
#!/bin/bash
PGHOME=/opt/postgres/pgsql
PGBIN=$PGHOME/bin
PGDATA=/opt/postgres/data
PGPORT=5432
PGUSER=postgres
LOG_FILE=/opt/postgres/logs/failover.log
BOUN_SERVER=node4
BOUN_FILE=/opt/postgres/pgbouncer/etc/pgbouncer.ini
BOUN_LISTEN_PORT=6432
BOUN_ADMIN_USER=pgbouncer
STANDBY_IP=192.168.59.*
MASTER_IP=192.168.59.26
CONN_INFO="user=repmgr port=5432 dbname=repmgr"
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "$TIME进入备机升级为主机操作" >> $LOG_FILE
$PGBIN/repmgr standby promote >> $LOG_FILE
echo "$?切换是否成功,0表示成功!" >> $LOG_FILE
if [ $? == 0 ];then
echo "$? 操作是否成功?0表示成功!" >> $LOG_FILE
IF_RECOVERY=" t"
while [ "$IF_RECOVERY" = " t" ];do
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "$TIME 查看本机postgres数据库是否为主机!" >> $LOG_FILE
IF_RECOVERY=`psql -c "select pg_is_in_recovery()" | sed -n '3,3p'`
echo "查询执行完!结果:|$IF_RECOVERY|" >> $LOG_FILE
if [ "$IF_RECOVERY" == " f" ];then
echo "$TIME FAILOVER-INFO:切换成功!">>$LOG_FILE
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "$TIME 替换鉴证节点pgbouncer.ini文件内所有连接地址为本地" >> $LOG_FILE
echo "sed -i 's/host=$STANDBY_IP/host=$MASTER_IP $CONN_INFO/g' $BOUN_FILE" | ssh $PGUSER@$BOUN_SERVER bash
echo "$?替换是否成功,0表示成功" >> $LOG_FILE
if [ $? == 0 ];then
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "TIME FAILVOER-INFO:更新监证节点上pgbouncer.init成功!" >> $LOG_FILE
ssh postgres@node4 "/opt/postgres/pgbouncer/bin/pgbouncer -R -d $BOUN_FILE" &>>$LOG_FILE
if [ $? == 0 ];then
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "#################################新的连接池信息#############################################################################">>$LOG_FILE
$PGBIN/psql -h $BOUN_SERVER -p $BOUN_LISTEN_PORT -U $BOUN_ADMIN_USER pgbouncer -c "show databases">> $LOG_FILE
echo "############################################################################################################################">>$LOG_FILE
else
echo "$TIME FAILOVER-ERROR:pgbouncer重启失败!" >> $LOG_FILE
fi
else
echo "$TIME FAILOVER-ERROR:更新监证节点上pgbouncer.ini失败!" >> $LOG_FILE
fi
else
echo "$TIME FAILOVER-ERROR:备库还在升级到主库,稍后再试!" >> $LOG_FILE
echo "休息10秒!" >> $LOG_FILE
sleep 10
echo "休息完成!" >> $LOG_FILE
fi
done
else
TIME=`date '+%Y-%m-%d %H:%M:%S'`
echo "$TIME ERROR: 备库升级为主库失败!"
fi
- 修改node1、node2、node3上repmgr.conf如下对应参数
failover='automatic'
promote_command='/opt/postgres/etc/failover.sh'
follow_command='repmgr standby follow -f /opt/postgres/pgsql/etc/repmgr.conf --log-to-file --upstream-node-id=%n'重启repmgr守护进程,node1、node2、node3都需要执行
[postgres@node1 etc]$ ps -aux|grep repmgrd
postgres 9866 0.0 0.0 13360 1152 ? S 15:46 0:01 repmgrd -d
postgres 17982 0.0 0.0 112816 984 pts/0 R+ 17:17 0:00 grep --color=auto repmgrd
[postgres@node1 etc]$ kill -9 9866
[postgres@node1 etc]$ ps -aux|grep repmgrd
postgres 17999 0.0 0.0 112816 984 pts/0 R+ 17:17 0:00 grep --color=auto repmgrd
[postgres@node1 etc]$ repmgrd -d
[2022-08-25 17:17:47] [NOTICE] redirecting logging output to "/opt/postgres/logs/repmgr-node1.log"
[postgres@node1 etc]$ ps -aux|grep repmgrd
postgres 18008 0.0 0.0 13360 1096 ? S 17:17 0:00 repmgrd -d
postgres 18019 0.0 0.0 112816 984 pts/0 S+ 17:17 0:00 grep --color=auto repmgrd
11.验证主备自动切换
查看群集信息并且停止主服务
[postgres@node1 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | * running | | default | 3 | 7 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | standby | running | node1 | default | 2 | 7 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | node1 | default | 2 | 7 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
4 | node4 | witness | * running | node1 | default | 0 | n/a | host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2
[postgres@node1 etc]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
在备节点上查看群集状态
[postgres@node3 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+---------------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | ? unreachable | ? | default | 3 | | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | standby | running | ? node1 | default | 2 | 7 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | ? node1 | default | 2 | 7 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
4 | node4 | witness | * running | ? node1 | default | 0 | n/a | host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2
WARNING: following issues were detected
- unable to connect to node "node1" (ID: 1)
- node "node1" (ID: 1) is registered as an active primary but is unreachable
- unable to connect to node "node2" (ID: 2)'s upstream node "node1" (ID: 1)
- unable to determine if node "node2" (ID: 2) is attached to its upstream node "node1" (ID: 1)
- unable to connect to node "node3" (ID: 3)'s upstream node "node1" (ID: 1)
- unable to determine if node "node3" (ID: 3) is attached to its upstream node "node1" (ID: 1)
- unable to connect to node "node4" (ID: 4)'s upstream node "node1" (ID: 1)
HINT: execute with --verbose option to see connection error messages
[postgres@node3 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | primary | - failed | ? | default | 3 | | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | primary | * running | | default | 2 | 8 | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | node2 | default | 2 | 7 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
4 | node4 | witness | * running | node2 | default | 0 | n/a | host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2
WARNING: following issues were detected
- unable to connect to node "node1" (ID: 1)
HINT: execute with --verbose option to see connection error messages
查看node2节点的failover日志
2022-08-26 11:10:13进入备机升级为主机操作
0切换是否成功,0表示成功!
0 操作是否成功?0表示成功!
2022-08-26 11:10:14 查看本机postgres数据库是否为主机!
查询执行完!结果:| f|
2022-08-26 11:10:14 FAILOVER-INFO:切换成功!
2022-08-26 11:10:14 替换鉴证节点pgbouncer.ini文件内所有连接地址为本地
0替换是否成功,0表示成功
TIME FAILVOER-INFO:更新监证节点上pgbouncer.init成功!
2022-08-26 11:10:15.037 CST [19535] LOG takeover_init: launching connection
2022-08-26 11:10:15.037 CST [19535] LOG S-0x1048830: pgbouncer/pgbouncer@unix:6432 new connection to server
2022-08-26 11:10:15.037 CST [19535] LOG S-0x1048830: pgbouncer/pgbouncer@unix:6432 login OK, sending SUSPEND
2022-08-26 11:10:15.037 CST [19535] LOG SUSPEND finished, sending SHOW FDS
2022-08-26 11:10:15.038 CST [19535] LOG got pooler socket: 0.0.0.0:6432
2022-08-26 11:10:15.038 CST [19535] LOG got pooler socket: [::]:6432
2022-08-26 11:10:15.038 CST [19535] LOG got pooler socket: unix:6432
2022-08-26 11:10:15.038 CST [19535] LOG SHOW FDS finished
2022-08-26 11:10:15.038 CST [19535] LOG disko over, going background
#################################新的连接池信息#############################################################################
name | host | port | database | force_user | pool_size | min_pool_size | reserve_pool | pool_mode | max_connections | current_connections | paused | disabled
-----------+---------------+------+-----------+------------+-----------+---------------+--------------+-----------+-----------------+---------------------+--------+----------
masterdb | 192.168.59.27 | 5432 | repmgr | repmgr | 25 | 0 | 0 | | 0 | 0 | 0 | 0
pgbouncer | | 6432 | pgbouncer | pgbouncer | 2 | 0 | 0 | statement | 0 | 0 | 0 | 0
(2 rows)
############################################################################################################################
验证连接池链接是否正常
连接信息不变,但实际已经连接到192.168.58.27数据库上。
[postgres@node4 etc]$ psql -p 6432 -h 192.168.59.29 masterdb
psql (14.4)
Type "help" for help.
masterdb=# \d
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+--------
repmgr | events | table | repmgr
repmgr | monitoring_history | table | repmgr
repmgr | nodes | table | repmgr
repmgr | replication_status | view | repmgr
repmgr | show_nodes | view | repmgr
repmgr | voting_term | table | repmgr
(6 rows)
masterdb=# SELECT CURRENT_USER usr,inet_server_addr() host ,inet_server_port() port;
usr | host | port
--------+---------------+------
repmgr | 192.168.59.27 | 5432
(1 row)恢复故障主节点,并注册为备机
[postgres@node1 etc]$ repmgr node rejoin -d 'host=192.168.59.27 dbname=repmgr user=repmgr' --force-rewind
NOTICE: rejoin target is node "node2" (ID: 2)
NOTICE: executing pg_rewind
DETAIL: pg_rewind command is "/opt/postgres/pgsql/bin/pg_rewind -D '/opt/postgres/data' --source-server='host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2'"
NOTICE: 0 files copied to /opt/postgres/data
NOTICE: setting node 1's upstream to node 2
WARNING: unable to ping "host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: starting server using "/opt/postgres/pgsql/bin/pg_ctl -w -D '/opt/postgres/data' start"
NOTICE: NODE REJOIN successful
DETAIL: node 1 is now attached to node 212.报错总结
故障主机恢复后作为备机加入群集时报错
报错信息:
[postgres@node1 logs]$ repmgr node rejoin -d 'host=192.168.59.27 dbname=repmgr user=repmgr' --force-rewind
NOTICE: rejoin target is node "node2" (ID: 2)
NOTICE: pg_rewind execution required for this node to attach to rejoin target node 2
DETAIL: rejoin target server's timeline 2 forked off current database system timeline 1 before current recovery point 0/9008E50
ERROR: --force-rewind specified but pg_rewind cannot be used
DETAIL: "wal_log_hints" is set to "off" and data checksums are disabled 解决方案:
修改主备所有节点上/opt/postgres/data/postgres.conf中wal_log_hints为on
出现双主问题
通过failover.sh脚本切换后出现如下错误
[postgres@node1 etc]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+----------------------+----------+----------+----------+----------+------------------------------------------------------------------
1 | node1 | standby | ! running as primary | ? node2 | default | 3 | 9 | host=node1 port=5432 dbname=repmgr user=repmgr connect_timeout=2
2 | node2 | primary | ? unreachable | ? | default | 2 | | host=node2 port=5432 dbname=repmgr user=repmgr connect_timeout=2
3 | node3 | standby | running | node1 | default | 2 | 8 | host=node3 port=5432 dbname=repmgr user=repmgr connect_timeout=2
4 | node4 | witness | * running | node1 | default | 0 | n/a | host=node4 port=5432 dbname=repmgr user=repmgr connect_timeout=2
WARNING: following issues were detected
- node "node1" (ID: 1) is registered as standby but running as primary
- unable to connect to node "node1" (ID: 1)'s upstream node "node2" (ID: 2)
- unable to determine if node "node1" (ID: 1) is attached to its upstream node "node2" (ID: 2)
- unable to connect to node "node2" (ID: 2)
- node "node2" (ID: 2) is registered as an active primary but is unreachable
HINT: execute with --verbose option to see connection error messages 查看repmgr日志发现repmgr守护进程已经中断
[2022-08-26 12:01:01] [INFO] checking state of node "node2" (ID: 2), 5 of 6 attempts
[2022-08-26 12:01:01] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=node2 port=5432 fallback_application_name=repmgr"
[2022-08-26 12:01:01] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2022-08-26 12:01:01] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2022-08-26 12:01:11] [INFO] checking state of node "node2" (ID: 2), 6 of 6 attempts
[2022-08-26 12:01:11] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=node2 port=5432 fallback_application_name=repmgr"
[2022-08-26 12:01:11] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2022-08-26 12:01:11] [WARNING] unable to reconnect to node "node2" (ID: 2) after 6 attempts
[2022-08-26 12:01:11] [INFO] 2 active sibling nodes registered
[2022-08-26 12:01:11] [INFO] 4 total nodes registered
[2022-08-26 12:01:11] [INFO] primary node "node2" (ID: 2) and this node have the same location ("default")
[2022-08-26 12:01:11] [INFO] local node's last receive lsn: 0/F016E80
[2022-08-26 12:01:11] [INFO] checking state of sibling node "node3" (ID: 3)
[2022-08-26 12:01:11] [INFO] node "node3" (ID: 3) reports its upstream is node 2, last seen 51 second(s) ago
[2022-08-26 12:01:11] [INFO] standby node "node3" (ID: 3) last saw primary node 51 second(s) ago
[2022-08-26 12:01:11] [INFO] last receive LSN for sibling node "node3" (ID: 3) is: 0/F016E80
[2022-08-26 12:01:11] [INFO] node "node3" (ID: 3) has same LSN as current candidate "node1" (ID: 1)
[2022-08-26 12:01:11] [INFO] node "node3" (ID: 3) has lower priority (2) than current candidate "node1" (ID: 1) (3)
[2022-08-26 12:01:11] [INFO] checking state of sibling node "node4" (ID: 4)
[2022-08-26 12:01:11] [INFO] node "node4" (ID: 4) reports its upstream is node 2, last seen 50 second(s) ago
[2022-08-26 12:01:11] [INFO] witness node "node4" (ID: 4) last saw primary node 50 second(s) ago
[2022-08-26 12:01:11] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds
[2022-08-26 12:01:11] [NOTICE] promotion candidate is "node1" (ID: 1)
[2022-08-26 12:01:11] [NOTICE] this node is the winner, will now promote itself and inform other nodes
[2022-08-26 12:01:11] [INFO] promote_command is:
"/opt/postgres/etc/failover.sh"
[2022-08-26 12:01:12] [INFO] checking state of node 1, 1 of 6 attempts
[2022-08-26 12:01:12] [NOTICE] node 1 has recovered, reconnecting
[2022-08-26 12:01:12] [INFO] connection to node 1 succeeded
[2022-08-26 12:01:12] [INFO] original connection is still available
[2022-08-26 12:01:12] [INFO] 2 followers to notify
[2022-08-26 12:01:12] [NOTICE] notifying node "node3" (ID: 3) to follow node 1
INFO: node 3 received notification to follow node 1
[2022-08-26 12:01:12] [NOTICE] notifying node "node4" (ID: 4) to follow node 1
INFO: node 4 received notification to follow node 1
[2022-08-26 12:01:12] [INFO] switching to primary monitoring mode
[2022-08-26 12:01:12] [ERROR] connection to database failed
[2022-08-26 12:01:12] [DETAIL]
connection to server at "node2" (192.168.59.27), port 5432 failed: Connection refused
Is the server running on that host and accepting TCP/IP connections?
[2022-08-26 12:01:12] [DETAIL] attempted to connect using:
user=repmgr connect_timeout=2 dbname=repmgr host=node2 port=5432 fallback_application_name=repmgr options=-csearch_path=
[2022-08-26 12:01:12] [ERROR] unable connect to upstream node (ID: 2), terminating
[2022-08-26 12:01:12] [HINT] upstream node must be running before repmgrd can start
[2022-08-26 12:01:12] [INFO] repmgrd terminating...
[postgres@node1 logs]$ ps -aux|grep repmgrd
postgres 3345 0.0 0.0 112816 980 pts/0 R+ 12:05 0:00 grep --color=auto repmgrd
[postgres@node1 logs]$ 解决方法:
修改failover.sh切换主备的命令由原来pg_ctl promote变为repmgr standby promote


