




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!


近期由于flink集群的CPU总核数限制,flink集群已经没有看可用的slot资源,无法继续在集群上新增flink任务,所以需要横向拓展flink集群的计算节点。
设置主机环境
#修改主机名称
# for hadoop
export HADOOP_HOME=/home/shsnc/domp-product/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export YARN_CONF_DIR=$HADOOP_CONF_DIR
export HADOOP_CLASSPATH=`hadoop classpath`
修改所有主机的/etc/hosts文件,加入新加入机器的IP和主机名,新加入主机的/etc/hosts文件中加入所有主机的IP和主机名.
配置免密登录
安装并配置hadoop
#修改hadoop的slaves配置,添加所有的主机节点IP地址.
vi /home/shsnc/domp-product/hadoop/etc/hadoop/slaves
tar -Pczvf home/shsnc/domp-product.tar.gz home/shsnc/domp-
product/* --exclude=/home/shsnc/domp-product/hadoop/data --
exclude=/home/shsnc/domp-product/hadoop/logs
scp domp-product.tar.gz ***@***:./domp-product/
tar -xzvf domp-product.tar.gz
<property>
<name>fs.default.name</name>
<value>hdfs://主节点主机名:服务端口</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>主节点主机名</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://主节点主机名:服务端口/jobhistory/logs/</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>主节点主机名:服务端口</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>当前节点主机名:服务端口</value>
</property>
启动新节点上的datanode和nodemanager服务
#启动服务:
./hadoop-deamon.sh start datanode
./yarn-deamon.sh start nodemanager
vi /home/shsnc/domp-product/hadoop/data/hdfs/datanode/current/VERSION
将VERSION文件中的clusterID修改为和原集群一样后,重启datanode.
刷新并调整集群状态
#刷新数据节点,将新节点加载到集群中:
hadoop/bin/hdfs refreshNodes
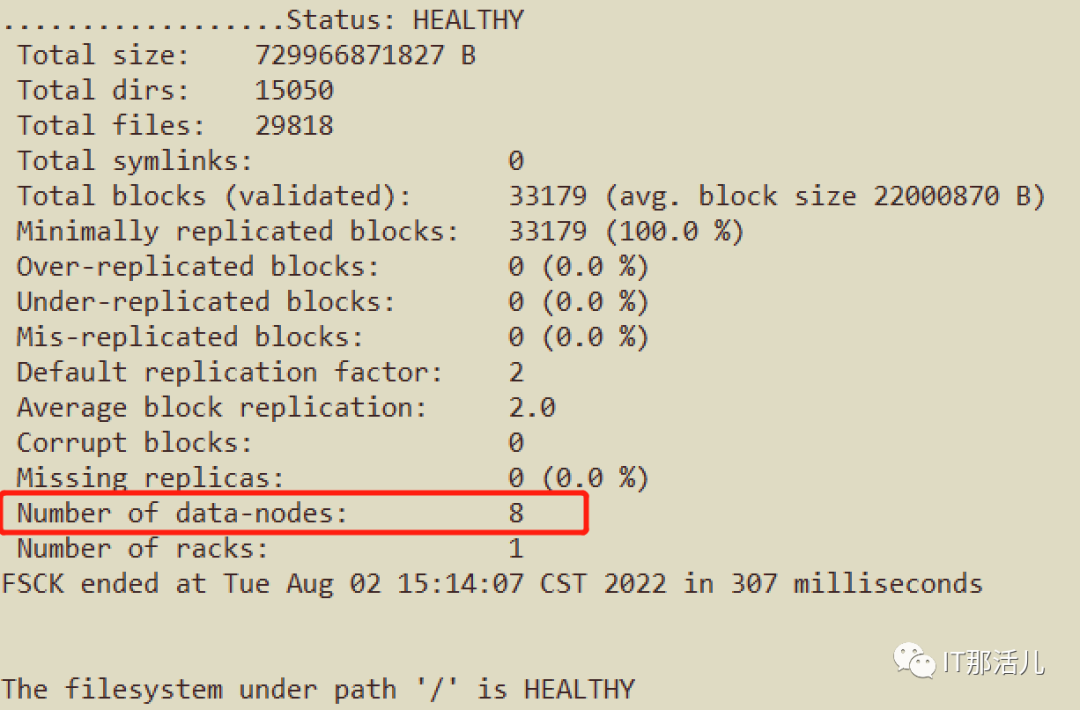
hdfs fsck
#平衡节点数据:
start-balancer.sh
#查看所有节点信息:
hdfs dfsadmin -report
以上就完成了整个集群的动态拓展!

本文作者:胡京康(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
