




Kaggle项目GiveMeSomeCredit实战
逮噶猴,在第一次实战(详见推送:Xgboost简单建模——Kaggle项目GiveMeSomeCredit实战)中,我们初步得到了一个Xgboost模型,并且提到将在后续更新中进行风控评分卡建模实操,因此从本次更新开始,我们就来一步一步完成这个小目标。
在数据竞赛中,尤其对于表格型的数据集,我们常采用xgboost,或者LightGBM,catboost等模型进行训练,而在实际的风控场景中,尤其是对于银行等金融机构来说,逻辑回归即LR模型由于可解释性强、特征权重直观等原因,仍然是实际工作中的主流模型。由于评分卡模型涉及要素很多,今天,我们就先来对LR评分卡模型的整体建模流程作一个全面的了解,并进行简单的代码实操。后续,我们再对流程中的每个环节进行详细的拆解~
数据源:give me some credit数据集
数据源介绍:
来源于kaggle官网,主要为个人在银行的基本信息及信贷信息。

数据源地址:https://www.kaggle.com/c/GiveMeSomeCredit/data
注:也可通过在公众号后台回复“GiveMeSomeCredit数据集”获取数据
建模目标:通过某客户在过去的个人信息及信贷信息信贷信息预测该客户在未来两年经理财务困境的概率,为银行的授信决策提供依据。
评价标准:AUC
关注重点:LR评分卡建模流程实操
环境配置
# 基本功能import pandas as pdimport numpy as np# 画图import matplotlibimport matplotlib.pyplot as pltimport seaborn as sns# 数据处理from sklearn.model_selection import train_test_splitfrom sklearn.model_selection import KFold, cross_validatefrom sklearn.preprocessing import OneHotEncoderimport imblearn# 模型算法import statsmodels.api as smfrom sklearn.linear_model import LogisticRegression as LR# 模型评价from sklearn.metrics import roc_curvefrom sklearn.metrics import auc,roc_auc_scorefrom sklearn.metrics import accuracy_score,confusion_matrix,f1_scorefrom sklearn.model_selection import cross_val_score# 风控import toadfrom toad.plot import bin_plot,badrate_plot# pd显示配置pd.set_option('precision',3)pd.set_option('display.float_format',lambda x:'{:.4f}'.format(x))# sns风格与装饰sns.set(style='whitegrid',font='Simhei')# 系统路径,定义为数据集所在地址import osos.chdir(r'C:\Users\28779\Desktop\GiveMeSomeCredit')# 输出每个cell代码返回的所有结果from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = 'all'# 屏蔽提示import warningswarnings.filterwarnings('ignore')
读取数据
# 训练数据示例data = pd.read_csv('cs-training.csv')
数据字典信息如下:
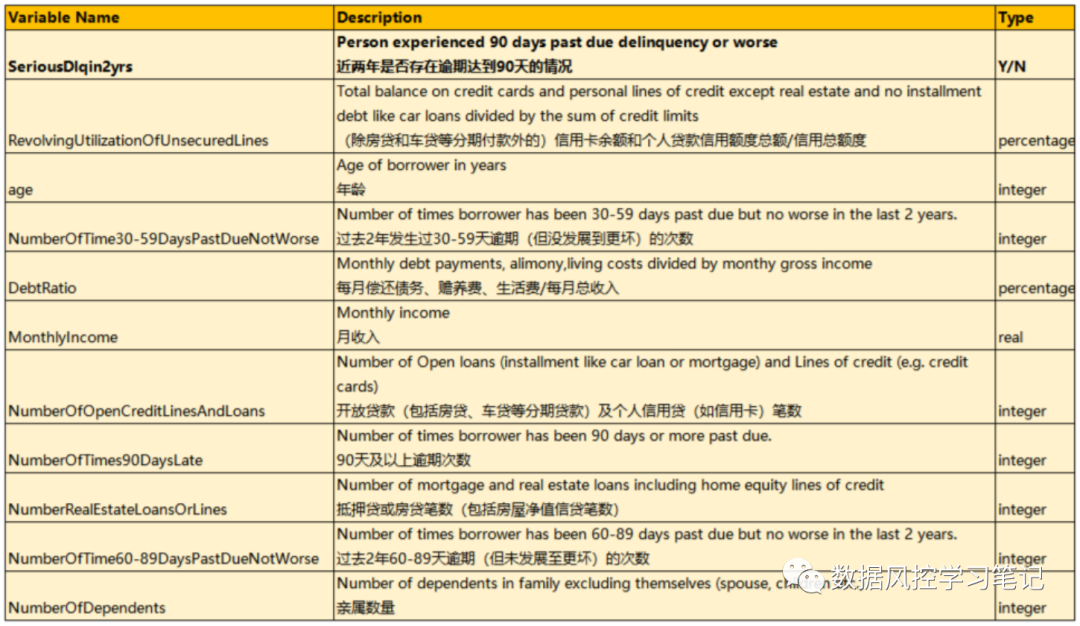
# 查看尾部两行data.tail(2)# 查看&重命名列data.columnsdata.drop(columns='Unnamed: 0',inplace=True)column = ['target', 'RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']data.columns = columndata.head()

# 区分特征与标签fea = ['RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']label = 'target'ex_lis = []
数据查看
# 样本概览data.info()data.shape
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 target 150000 non-null int64
1 RevUtilOfUnsecLines 150000 non-null float64
2 age 150000 non-null int64
3 30-59DPD 150000 non-null int64
4 DebtRatio 150000 non-null float64
5 MonthlyIncome 120269 non-null float64
6 NumOfOpCreAndLoans 150000 non-null int64
7 NumOf90DPD 150000 non-null int64
8 NumReaEstLoansOrLines 150000 non-null int64
9 60-89DPD 150000 non-null int64
10 NumberOfDependents 146076 non-null float64
dtypes: float64(4), int64(7)
memory usage: 12.6 MB可以看到,样本数量为150000,特征数为10个,特征值均为数值型,标签值无缺失,数据大小是12.6MB,不用压缩可以直接拿来分析
# 标签分析data.target.value_counts()print('坏样本浓度为{:.4f}%'.format(100*data.target.mean()))
0 139974
1 10026Name: target, dtype: int64坏样本浓度为6.6840%
# 特征分析data.describe()
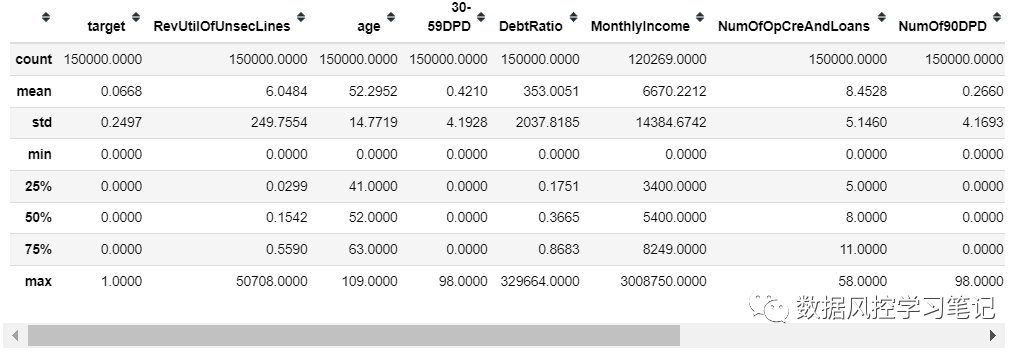
查看特征的非空数量、均值、方差、极大值、极小值和四分位值
数据预处理
1.重复值处理
# 查看数据重复情况data.duplicated().sum()# 查看重复数据明细data[data.duplicated()]# 查看重复值中坏样本数量data[data.duplicated()].target.sum()
17通过明细和重复值数量可以看出,拥有重复特征值的数据并没有表现出异常,可能是自然存在的,因此这里不做处理
2.缺失值处理在之前的《Xgboost简单建模——Kaggle项目GiveMeSomeCredit实战》一文中,我们对缺失值进行了查看,但并没有做处理,这是由于Xgboost中自带缺失值处理函数,我们将带有缺失值的数据直接扔进模型,模型也可以支持处理。而LR模型是不支持缺失值自动处理的,所以一定要记得先对缺失值做好处理再把数据丢进模型,不然模型训练时就会报错喔~# 查看数据缺失情况missing_num = data.isnull().sum()missing_rate = data.isnull().sum()/(data.isnull().count())df_missing = pd.DataFrame({'num':missing_num,'rate':missing_rate})df_missing.rate = df_missing.rate.apply(lambda x :'{:.4f}%'.format(100*x))df_missing
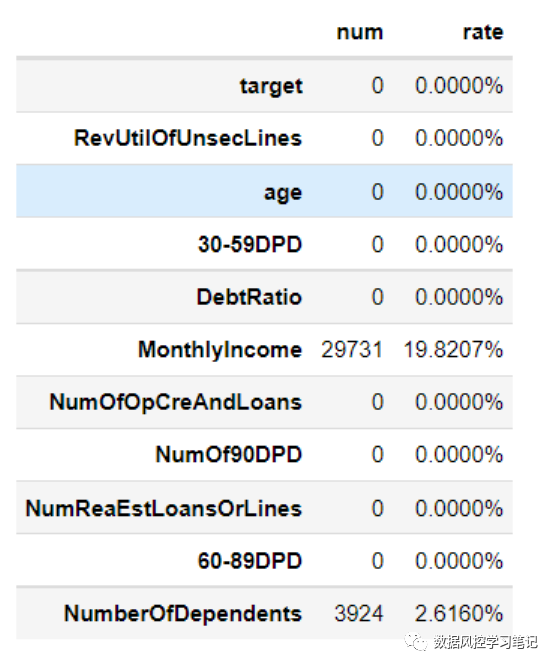
图表显示,有两个字段存在缺失,分别是MonthlyIncome和
NumberOfDependents,其中NumberOfDependents字段的缺失率比较低,我们可以直接丢掉,MonthlyIncome的缺失值接近20%,我们对缺失值进行填补,此处采用均值填补法,缺失值的处理其实方法有很多,先放一个坑在这里,我们在后续推送中再单独进行详细说明~
# 丢弃NumberOfDependents字段值为空的数据data.dropna(subset=['NumberOfDependents'],inplace=True)# 使用均值填补法对MonthlyIncome字段的缺失值进行填补data['MonthlyIncome'].fillna(data['MonthlyIncome'].mean(),inplace=True)
3.异常值处理
# 查看异常数据情况plt.figure(figsize=(20,15),dpi=100)for i in range(len(fea)):plt.subplot(3,4,i+1)sns.boxplot(y=data[fea[i]],orient='v',width=0.5)plt.title(fea[i])plt.tight_layout()plt.show()
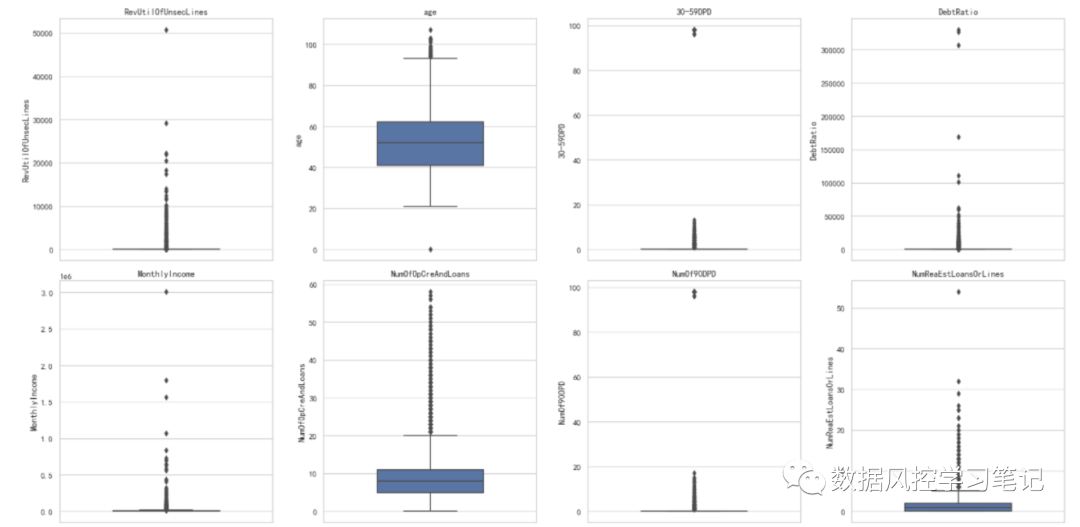
对每个特征的分布和极值情况进行观察,结合对字段的理解,我们将三个逾期字段30-59DPD,60-89DPD,和NumOf90DPD中逾期次数超过90的数据去除,同时也去除掉RevUtilOfUnsecLines字段值大于50000的数据
data = data[(data['RevUtilOfUnsecLines']<50000)&(data['30-59DPD']<90)]
数据探索性分析
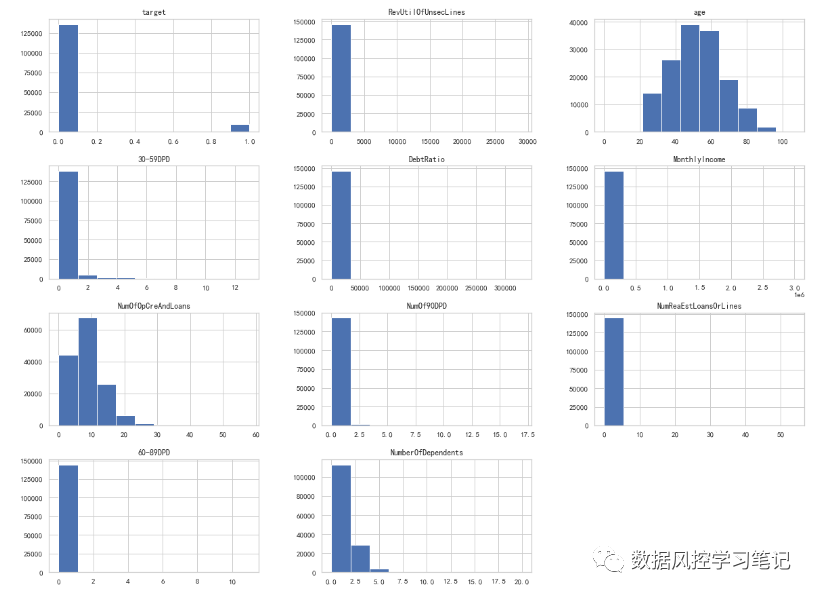
# 画出数据分布图data.hist(figsize=(20,15))
数据划分
# 抽取30%的验证集X_train,X_test,y_train,y_test = train_test_split(data[fea],data[label],test_size=0.3,random_state=42)data_training = pd.concat([X_train,y_train],axis=1)data_test = pd.concat([X_test,y_test],axis=1
特征分箱
# 生成分箱实例combiner_chi = toad.transform.Combiner()# 进行卡方分箱combiner_chi.fit(data_training,data_training[label],method='chi',min_samples = 0.05,\empty_separate=True,exclude=label)# 导出分箱节点bins_chi = combiner_chi.export()

bins_chi返回一个字典,里面包含了所有特征的切分点信息
这里我们看到,NumOf90DPD仅仅只划分出了1箱,NumOf90DPD甚至1箱也没分出,这是由于这两个特征本身的特征值较少,且与与30-59DPD存在一定的相关性导致的。此处,我们重新观察这两个特征的特征值分布,调用toad库的节点调整方法重新对分箱节点进行调整:
# 对上一步得到的节点直接进行调整adj_bin = {'RevUtilOfUnsecLines': [0.061872817999999996,0.299745148,0.48757002,0.8826939290000001],'age': [36, 44, 51, 56, 58, 63, 68],'30-59DPD': [1, 2],'DebtRatio': [0.016196761, 0.40660066, 0.7264729409999999, 3.9728435277938843],'MonthlyIncome': [5409.0, 7332.0],'NumOfOpCreAndLoans': [2.5],'NumOf90DPD': [1,4],'NumReaEstLoansOrLines': [1, 3],'NumOf90DPD': [1,3],'NumberOfDependents': [1.0, 2.0]}combiner_chi.set_rules(adj_bin)
将修改后的节点应用于分箱
# 根据节点实施分箱data_training_bins_adj = combiner_chi.transform(data_training)# 验证集同步划分data_test_bins_adj = combiner_chi.transform(data_test[data_training.columns])
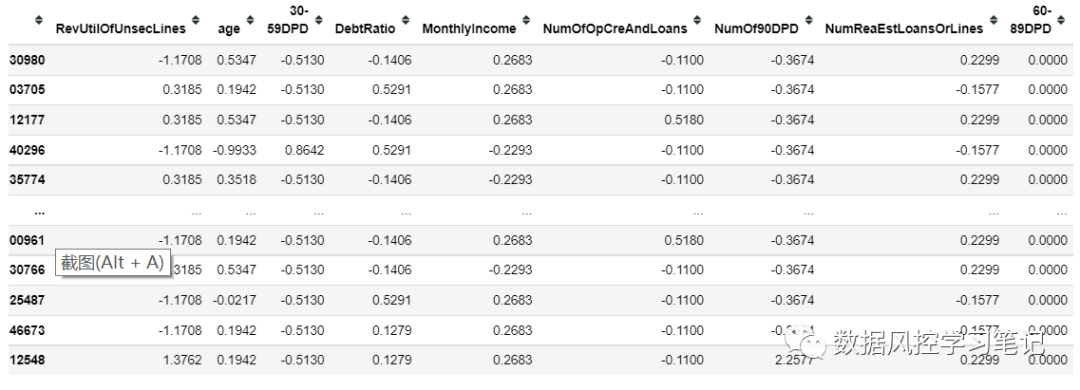
 data_training_bins_adj和data_test_bins_adj分别返回一个DataFrame,通过上图结果可以看到其中的特征值已经被箱子编号替代
data_training_bins_adj和data_test_bins_adj分别返回一个DataFrame,通过上图结果可以看到其中的特征值已经被箱子编号替代
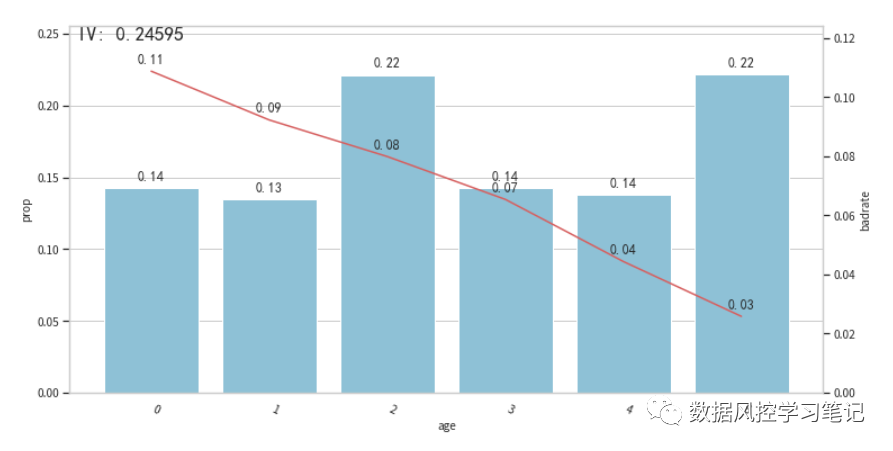
# 查看各箱标签分布for col in fea:bin_plot(data_training_bins_adj,x=col,target=label)
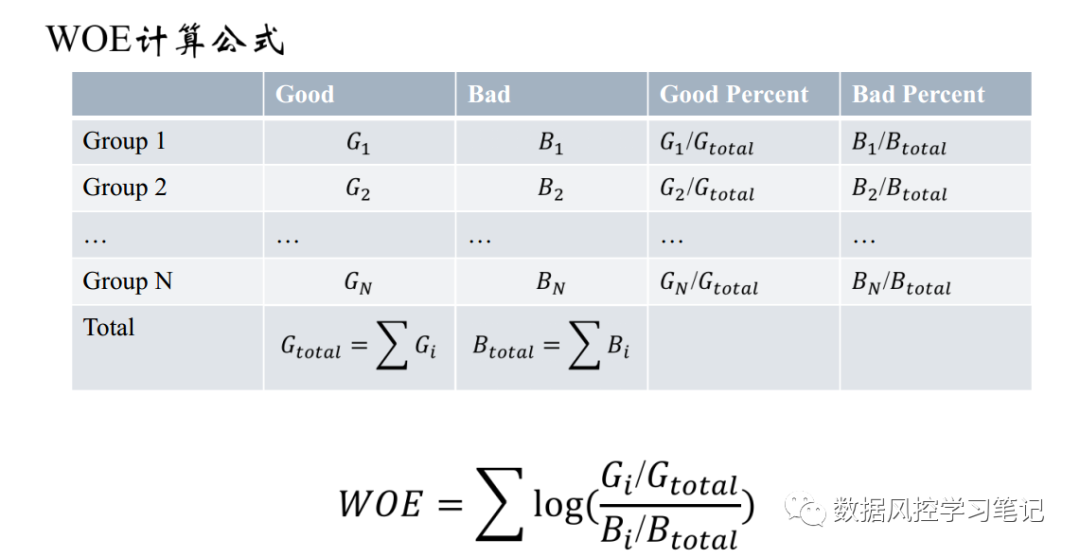
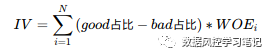
# WOE映射处理# 生成WOETransformer实例transer = toad.transform.WOETransformer()# 训练集、验证集WOE同步转换data_training_woe = transer.fit_transform(data_training_bins_adj, data_training_bins_adj[label], exclude=label)data_test_woe = transer.transform(data_training_bins_adj)
特征筛选
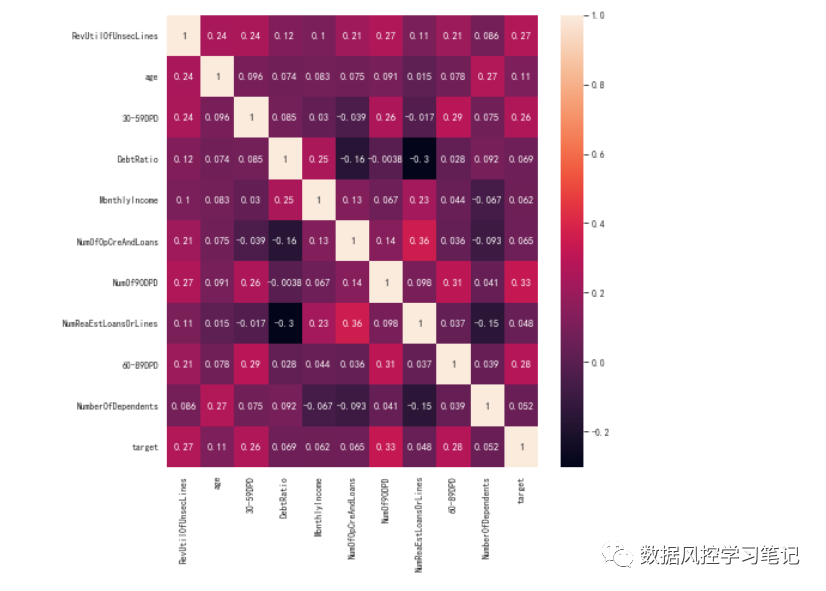
# 计算特征相关性data_training_woe_corr = data_training_woe.corr()# 设置画布大小plt.figure(figsize=(10,10),dpi=100)# 绘制热力图sns.heatmap(data=data_training_woe_corr,annot=True)
# 实施双向stepwise筛选data_training_woe_slct_stp,drop_lst_stp = toad.selection.stepwise(data_training_woe,data_training_woe[label],intercept = True,return_drop=True)# 查看drop的特征drop_lst_stp# 查看剩余特征数据data_training_woe_slct_stp# 保持验证集与训练集同步处理data_test_woe_slct_stp = data_test_woe_slct[data_training_woe_slct_stp.columns]# 更新特征列表,去除筛除的特征fea = data_training_woe_slct_stp.columns
['NumOfOpCreAndLoans']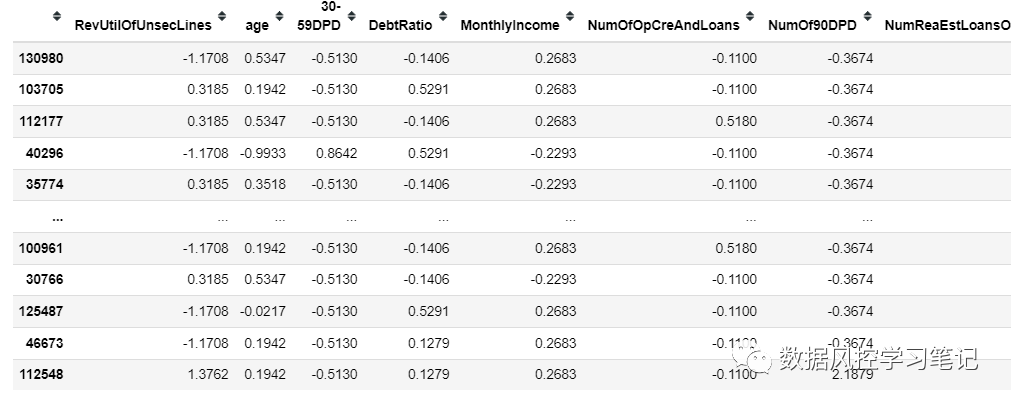
这一轮筛选掉了NumOfOpCreAndLoans这个特征,其余特征都保留了下来
LR建模
# 生成LR模型实例model_lr = LR(random_state=2022, solver='saga', penalty='l2', C=1.0, max_iter=500)# LR模型训练model_lr.fit(data_training_woe_slct[fea],data_training_woe[label])# LR模型预测y_pre_lr = model_lr.predict_proba(data_test_woe_slct[fea])[:,1]# 查看权重值model_lr.coef_
array([[0.62382961, 0.47817517, 0.52780345, 0.90017021, 0.04968211,
0.04383911, 0.53562691, 0.51525742, 0.43927112, 0.19261411]])# 定义y_testy_test = data_test_woe[label]# 计算auc值roc_auc_score(y_test,y_pre_lr)
0.8528142565736914可以看到,这个结果相比于xgboost还是略低的,但相差不多# 绘制roc曲线# 计算fpr_ci,tpr_cifpr,tpr,thresholds=roc_curve(y_test,y_pre_lr,pos_label=None,\sample_weight=None,drop_intermediate=True)# plotplt.figure()plt.plot([0,1],[0,1],lw=2,linestyle='--')plt.plot(fpr,tpr,label='ROC Curve')plt.title('ROC Curve')plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.legend()plt.show()
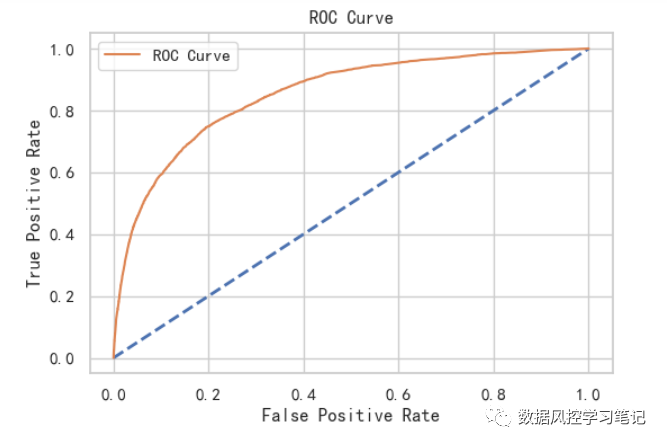
同步计算一下KS值
max(tpr_ci-fpr_ci)
0.5503761434091169这个结果相比于xgboost同样也是略低,但相差不多评分卡映射
Score = A + B * ln(Odds)
# 计算参数A、B的值A = base_score + PDO * np.log(Odds) np.log(2)B = PDO/np.log(2)# 定义评分卡映射函数def scorecard(p,A,B):p = min(p,0.9999)odds = p (1 - p)score = A - B * np.log(odds)score = max(300, score)score = min(1000, score)return score# 评分映射df_score = pd.DataFrame()df_score['pre'] = y_pre_lrdf_score['score'] = df_score['pre'].apply(lambda x: scorecard(p=x,A=A,B=B))df_score

# 绘制评分分布图sns.distplot(df_score['score'])
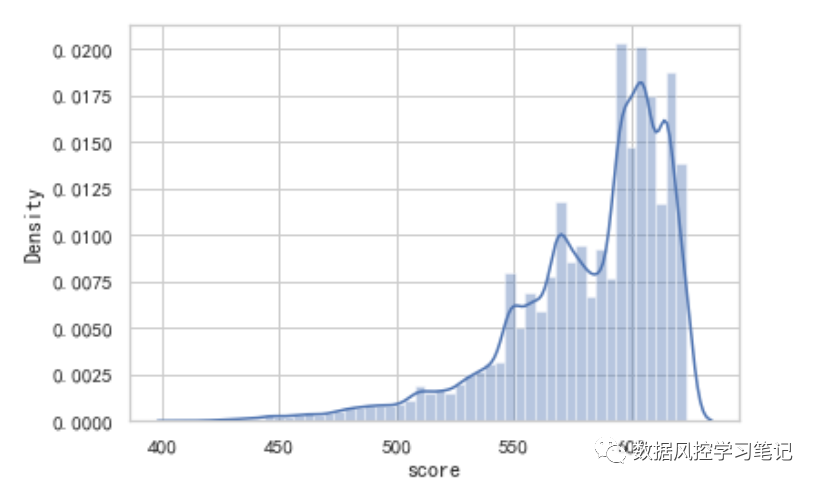
更具体地分析这个评分卡,我们可以得到下面这个表格:
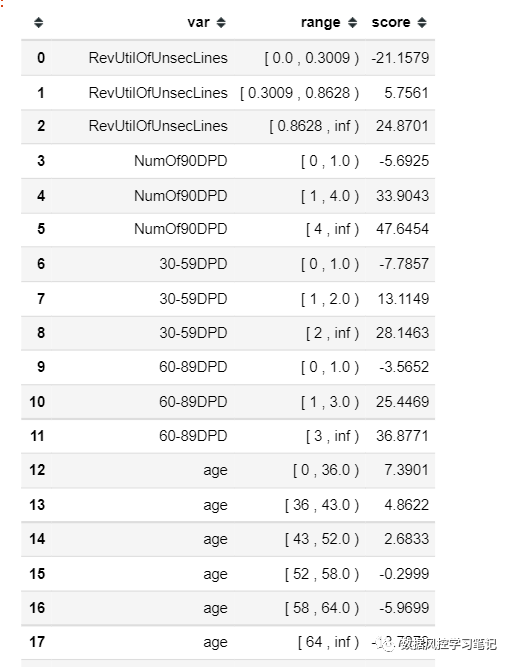
从中可以看到每个特征在各个箱体的阈值,和对应的得分,举个栗子,比如一个样本的年龄为50岁,那么该样本在age项的得分就是2.6833分,如该样本有过2次60-89DPD逾期,那么该样本在60-89DPD项的得分就是25.4469,我们对这个样本在所有特征上得到的分数进行求和,就是这个样本最后的评分卡得分啦~
在Xgboost简单建模一文中,Xgboost模型表现如下:
测试集:ks约为0.570,auc约为0.858
在Xgboost模型调参一文中,Xgboost模型表现如下:
测试集:ks约为0.585,auc约为0.867
在本文中,LR模型表现如下:
测试集:ks约为0.550,auc约为0.853
以上,我们建立了简单的LR模型,并且基于模型建立了评分卡,但其实这个过程中还有许多值得进一步探讨的具体细节,例如缺失值的处理、数据的探索、特征筛选、特征分箱、WOE和IV计算、评分变量得分计算等,小记也会持续和大家分享~


