




Kaggle项目GiveMeSomeCredit实战
逮噶猴,在上一次实战(详见上篇推送:Xgboost简单建模)中,我们初步得到了一个Xgboost模型,和一个还不错的AUC结果。可以看到,在建立模型的过程中Xgboost为我们提供了很多可以调试的入参项,那么问题来了,如何通过不同的入参取值使模型达到更好的预测效果呢?
在实际工作中,我们发现虽然部分参数在入参时存在所谓的“经验值”,但对于不同量级、不同特征,还有不同样本浓度的数据,如果想训练出效果更优的模型,往往需要通过对参数值进行反复调试,以观测不同入参取值对模型效果的影响。今天,我们就来进行一次Xgboost模型调参实验,详细瞧瞧参数调优的力量。
数据源:give me some credit数据集
数据源介绍:
来源于kaggle官网,主要为个人在银行的基本信息及信贷信息。

数据源地址:https://www.kaggle.com/c/GiveMeSomeCredit/data
建模目标:通过某客户在过去的个人信息及信贷信息信贷信息预测该客户在未来两年经理财务困境的概率,为银行的授信决策提供依据。
评价标准:AUC
关注重点:Xgboost模型调参效果
代码回顾
# 以下代码为前文代码回顾,本次实验将以此为基础进行# 详细代码注释见《Xgboost简单建模——Kaggle项目GiveMeSomeCredit实战》import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import KFold, cross_validatefrom sklearn.preprocessing import OneHotEncoderimport imblearnimport xgboost as xgbfrom sklearn.metrics import roc_curvefrom sklearn.metrics import auc,roc_auc_scorefrom sklearn.metrics import accuracy_score,confusion_matrix,f1_scorefrom sklearn.model_selection import cross_val_scoreimport toadfrom toad.plot import bin_plot,badrate_plotpd.set_option('precision',3)pd.set_option('display.float_format',lambda x:'{:.4f}'.format(x))sns.set(style='whitegrid',font='Simhei')import osos.chdir(r'C:\Users\28779\Desktop\GiveMeSomeCredit\GiveMeSomeCredit')from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = 'all'import warningswarnings.filterwarnings('ignore')data = pd.read_csv('cs-training.csv')data.drop(columns='Unnamed: 0',inplace=True)column = ['target', 'RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']data.columns = column
fea = ['RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']label = 'target'ex_lis = []data.target.value_counts()print('坏样本浓度为{:.4f}%'.format(100*data.target.mean()))data.duplicated().sum()missing_num = data.isna().sum()missing_rate = data.isnull().sum()/(data.isna().count())df_missing = pd.DataFrame({'num':missing_num,'rate':missing_rate})df_missing.rate = df_missing.rate.apply(lambda x :'{:.4f}%'.format(100*x))df_missingX_train,X_test,y_train,y_test = train_test_split(data[fea],data[label],test_size=0.3,random_state=42)data_training = pd.concat([X_train,y_train],axis=1)data_test = pd.concat([X_test,y_test],axis=1
评估函数
def model_evaluate(y_true,y_pre):'''input:y_true,series,样本标签,0或1y_pre,series,样本预测值,范围不限output:ks,auc,float,模型ks,auc指标值ROC图'''fpr,tpr,thresholds=roc_curve(y_true,y_pre,pos_label=None,sample_weight=None,drop_intermediate=True)ks_cal = abs(fpr-tpr)ks = max(ks_cal)print('ks:',ks)auc = roc_auc_score(y_true,y_pre)print('auc:',auc)# plotplt.figure()plt.plot([0,1],[0,1],lw=2,linestyle='--')plt.plot(fpr,tpr,label='ROC Curve')plt.title('ROC Curve')plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.legend()plt.show()return ks,auc
初始模型
# 参数设定model_xgb = xgb.XGBClassifier(n_estimators= 200,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.8,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=10,#叶子节点分裂时的损失减少量下限scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)
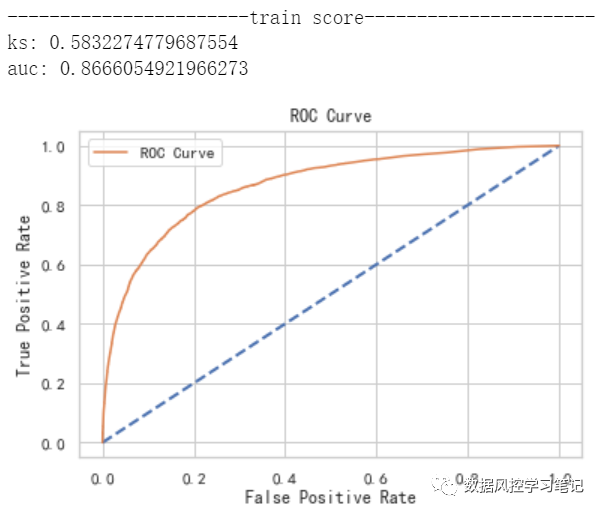
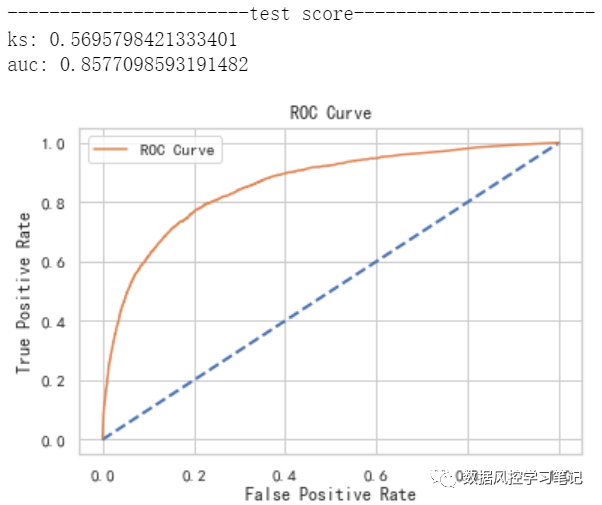
# 模型训练model_xgb.fit(X_train,y_train)# 模型预测y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 模型评估print('-----------------------train score----------------------')model_evaluate(y_train,y_pre_train_xgb)print('-----------------------test score-----------------------')model_evaluate(y_test,y_pre_test_xgb)
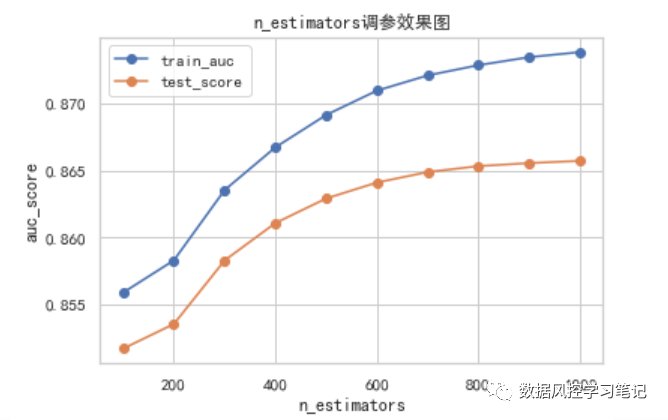
n_estimators调参实验
Xgboost与GBDT和LightGBM共属于集成算法中的Boosting算法,背后的原理可以简单理解为,把许多不同的评估器,也就是不同的树(可以是分类树,也可以是回归树)串联起来,通过不断拟合预测值与真实值之间的残差,使预测值逐步接近真实值。因此树的棵树越多,拟合程度也就越高,同时过拟合的风险也可能越大。n_estimators这个参数在这里代表的就是树的棵树。
我们尝试为n_estimators取不同的值,比较不同值下训练集和测试集的AUC表现,并将结果绘制成学习曲线,以便更直观地感受这一参数对于模型的影响。
# n_estimators调参# 指定参数的不同取值n_estimators_list = [100,200,300,400,500,600,700,800,900,1000]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in n_estimators_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= v,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(n_estimators_list,train_auc_list,marker='o',label='train_auc')plt.plot(n_estimators_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('n_estimators')plt.ylabel('auc_score')plt.title('n_estimators调参效果图')plt.show()
# 查看不同参数取值下的AUC得分test_auc_list
[0.8517023493127274,
0.8535354848601977,
0.8582802692230289,
0.8610660671332603,
0.862898120581762,
0.8640868043022017,
0.8648704116607943,
0.8653116005801008,
0.8655372401764581,
0.8657046181268747]
从上图的结果中,我们可以看出,当n_estimators<=600时,模型在训练集和测试集上的效果都有较为明显的提升,而当n_estimators>600时,训练集表现仍在提升,但测试集表现提升放缓,n_estimators>800时,测试集表现就几乎没有提升了。
考虑n_estimators的增加会影响运行时长,这里我们暂时选定n_estimators=800,此时测试集AUC为0.8653116005801008。
max_depth调参实验
max_depth代表xgboost算法中每个评估器,也就是每颗树的最大深度。树的深度越深,学习的信息也就越多,对训练数据拟合的更充分,模型也越复杂,也更有可能带来过拟合的风险。
我们尝试为max_depth取不同的值,比较不同值下训练集和测试集的AUC表现,并将结果绘制成学习曲线。
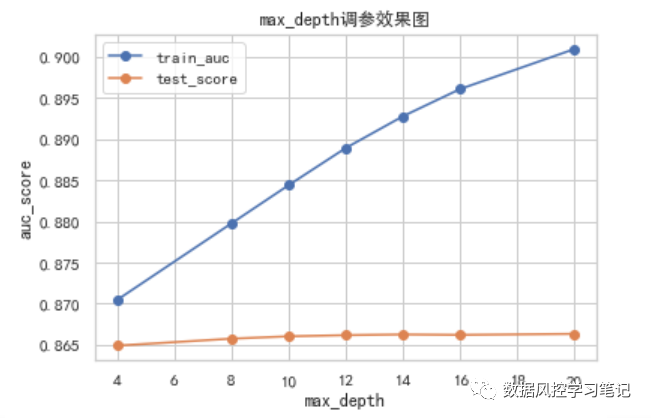
# max_depth调参# 指定参数的不同取值max_depth_list = [4,8,12,16,20]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in max_depth_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= v,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(max_depth_list,train_auc_list,marker='o',label='train_auc')plt.plot(max_depth_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('max_depth')plt.ylabel('auc_score')plt.title('max_depth调参效果图')plt.show()
test_auc_list
[0.8649096906554565,
0.8657547500551032,
0.8660379365530636,
0.8661812727400502,
0.8662658801018371,
0.8662136239055228,
0.8663374823110759]
从上图的结果中,我们可以看出,随着max_depth的逐步增加,模型在训练集上的效果有明显提升,当max_depth<=10时,测试集表现有所提升,当max_depth>10时,测试集的表现不再有明显提升,而是在max_depth=12时达到了一个小高峰,随后进入波动状态。
随着参数的调整,训练集的表现明显提升而测试集却不为所动,甚至出现表现下降的情况,我们通称为过拟合,过拟合也代表着随着参数的调整,模型由于过于适应训练集的数据,而无法在测试集上推广的状态。这种情况下,我们通常考虑降低模型复杂度,以确保模型在测试集上可以有良好的表现。
实时上,在实际应用中,max_depth常与n_estimators搭配进行调参,使用大量深度较低的树,与使用少量深度较高的树,可能达到一样的效果。
根据上面的实验结果,我们选定max_depth=12,此时测试集AUC为
0.8662658801018371。
subsample调参实验
subsample指对于每棵树,训练时的随机采样比例,如subsample=0.8,也就代表着每次生成一棵新的树时,我们随机抽取训练集中80%的样本对这棵树进行训练。降低subsample取值,可以降低过拟合风险,但如果subsample取值过低,也可能会造成模型学习不足的情况。
# subsample调参# 指定参数的不同取值subsample_list = [0.3,0.35,0.4,0.45,0.5,0.6,0.7,0.8]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in subsample_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= v,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(subsample_list,train_auc_list,marker='o',label='train_auc')plt.plot(subsample_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('subsample')plt.ylabel('auc_score')plt.title('subsample调参效果图')plt.show()
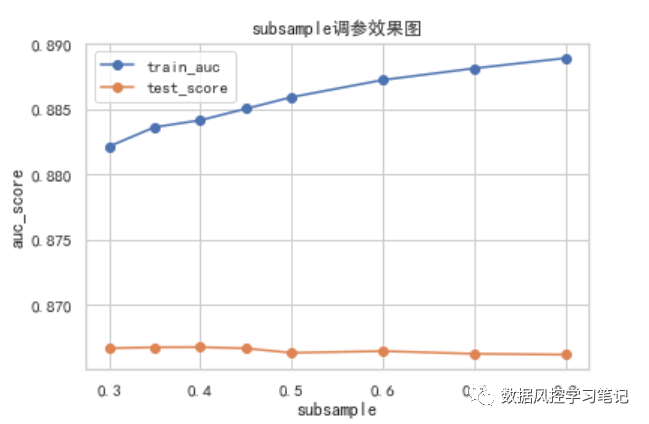
test_auc_list
[0.8666708007372648,
0.866743964203687,
0.8667571849774316,
0.8666601314810142,
0.8663202046644455,
0.8664508032288875,
0.8662452483477028,
0.8661812727400502]
从上面的图和数据中可以看出,随着subsample的上升,测试集AUC值呈现先上升后下降的趋势,最高值出现在subsample=0.4时,AUC达到
0.8667571849774316。
通常情况下,subsample的取值在[0.5,1]较多,主要原因是避免抽取样本不足导致欠拟合,但在本例中,n_estimators取值较高,树的棵树较多,同时0.4的取值偏离0.5不多,因此subsample取为0.4。
除了可以用于随机抽取样本的subsample外,Xgboost中还设置了两个参数colsample_bytree,colsample_bylevel,用于随机抽取特征。在本例中,由于特征本来就不多,我们就不再使用这两个参数,有兴趣的小伙伴也可以寻找一些特征量较大的数据集,尝试看下这两个参数的效果。
eta调参实验
eta在这里与learning_rate相同,代表着学习速率。我们了解,Xgboost是一种boosting集成算法,可以通过大量的树评估器的串行不断缩小预测值与真实值之间的残差,以达到较好的预测效果。损失函数就是用于度量残差的函数,在求解损失函数最小化的过程中,eta控制着不断迭代的速度,当eta越大时,损失函数能够越快地收敛,越快地接近极小值,但同时也容易错过最佳取值;eta越小时,损失函数收敛速度放慢,需要更多次数的迭代才能靠近极小值,但也有更大的机会接近最佳取值。
# eta调参# 指定参数的不同取值eta_list = [0.005,0.01,0.02,0.03,0.05,0.1]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in eta_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=v,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(eta_list,train_auc_list,marker='o',label='train_auc')plt.plot(eta_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('eta')plt.ylabel('auc_score')plt.title('eta调参效果图')plt.show()
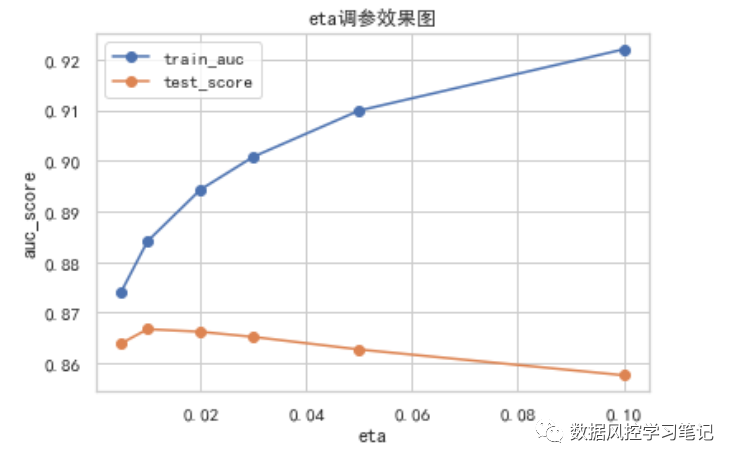
test_auc_list
[0.8639474650933241,
0.8667571849774316,
0.8662389514101626,
0.8652206403789823,
0.8627386926647266,
0.8576478282952509]
根据上面的实验结果,可以看出随着eta的上升,测试集的表现呈现先上升后下降的趋势,在eta=0.01时,模型取得AUC最高值0.8667571849774316。
gamma调参实验
gamma代表着叶子节点分裂时损失减小量的下限,也就是说,只有当叶子节点分裂后,损失的减小值>=gamma值时,叶子节点才会继续分裂,否则,叶子节点将不再分裂,树评估器也将停止生长。
gamma与n_estimators和max_depth一样,都是调节模型拟合程度的重要参数。如果gamma值设定过大,则叶子节点可能过早地停止分裂,造成学习不足,反之,如果gamma值设定过小,则叶子节点会分裂过盛,可能产生过拟合现象。
# gamma调参# 指定参数的不同取值gamma_list = [5,7,8,9,10,11,13,15]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in gamma_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=v,#叶子节点分裂时的损失减少量下限reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 1,#最小叶子节点样本权重和,用于控制每个节点上的样本数量scale_pos_weight= 1,#样本权重,通常用于处理样本不均衡的情况objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(gamma_list,train_auc_list,marker='o',label='train_auc')plt.plot(gamma_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('gamma')plt.ylabel('auc_score')plt.title('gamma调参效果图')plt.show()
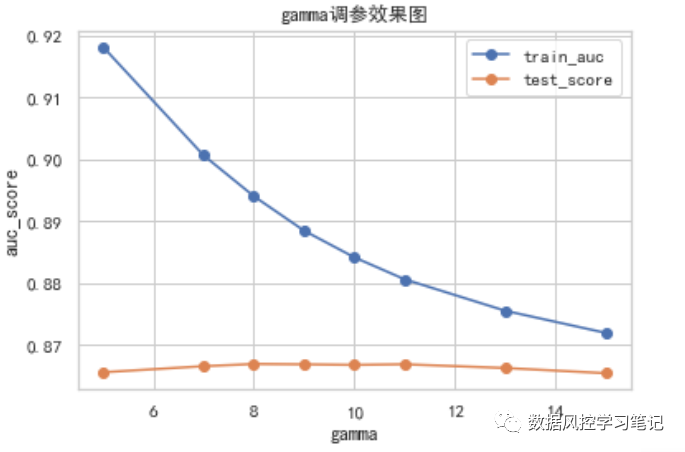
test_auc_list
[0.8655651231915771,
0.8665466308788718,
0.8669014475369671,
0.866844068340739,
0.8667571849774316,
0.8668555960887913,
0.8662544282205021,
0.8654155619407824]
从上面的实验结果来看,随着gamma取值的增加,训练集的表现呈现先上升再下降的趋势,在gamma=8时,AUC取得最高值0.8669014475369671,随后由于学习不足,出现欠拟合,训练集和测试集表现同步下降。
min_child_weight
调参实验
min_child_weight通常译为最小叶子节点样本权重和,指的是叶子节点上所有样本的损失函数(不考虑正则项)的二阶导数之和的最小值,主要用于控制叶子节点中的样本数。min_child_weight越大,每个叶子节点中样本数量的最小值就越大,每个叶子节点中的样本就越多,模型就越简单。因此,min_child_weight这一参数也可用于防止过拟合。
# min_child_weight调参# 指定参数的不同取值min_child_weight_list = [0.95,1,1.05,1.1]# 建立列表,储存不同参数取值下训练集和测试集的auc表现train_auc_list=[]test_auc_list=[]# 通过for循环,根据参数的不同取值分别生成模型、训练模型并获得评估结果for v in min_child_weight_list:# 生成模型model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= v,#最小叶子节点样本权重和,用于控制每个节点上的样本数量objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 训练模型model_xgb.fit(X_train,y_train)# 获取预测结果y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 计算auc值y_pre_train_auc = roc_auc_score(y_train,y_pre_train_xgb)y_pre_test_auc = roc_auc_score(y_test,y_pre_test_xgb)# 打印auc值print('train:',y_pre_train_auc,'test:',y_pre_test_auc)# 存储auc结果train_auc_list.append(y_pre_train_auc)test_auc_list.append(y_pre_test_auc)# 根据所有参数取值及AUC值绘制学习曲线plt.figure()plt.plot(min_child_weight_list,train_auc_list,marker='o',label='train_auc')plt.plot(min_child_weight_list,test_auc_list,marker='o',label='test_score')plt.legend()plt.xlabel('min_child_weight')plt.ylabel('auc_score')plt.title('min_child_weight调参效果图')plt.show()
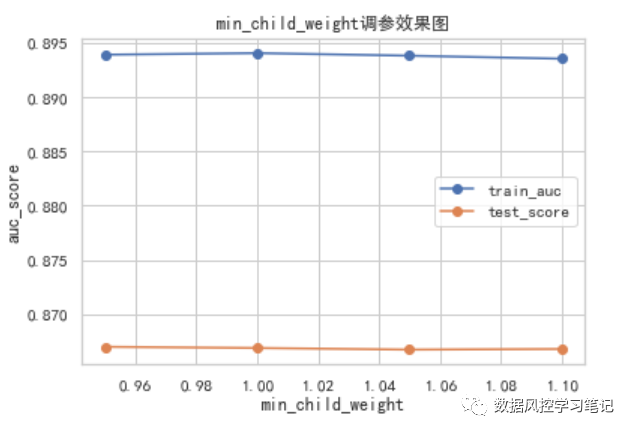
test_auc_list
[0.8670096614268055,
0.8669014475369671,
0.8667516706649758,
0.866809057847174]
可以看出,经过前面几轮的精调,再去调整min_child_weight的取值时,测试集AUC的变化已经不太显著了。我们此处选取min_child_weight=0.95,此时测试集的AUC表现达到0.8670096614268055。reg_alpha/reg_lambda
简要介绍
reg_alpha与reg_lambda分别为L1正则化项的系数和L2正则化项的系数,都是用于降低模型整体复杂度的的正则项,可以帮助我们更好地避免过拟合。Xgboost由大量的树组成,正则项就可以影响这些树评估器中部分叶子节点的权重,试想,如果一个叶子节点的权重接近于0,这个叶子节点就约等于并没有参与学习,这棵树的复杂度就会降低,模型的复杂度也随之降低了,过拟合的风险也就随之减小了。
在实际操作中,我们很少会通过调整这两个参数来优化模型效果。如需调整,我们可以通过GridSearchCV网格搜索的方法更准确地找到这两个参数的最佳取值,在此附上相关代码,感兴趣的小伙伴可以尝试跑跑看,这一过程可能耗时较长,大家要有耐心哦~
# 导入方法from sklearn.model_selection import GridSearchCV# 设置网格搜索参数params_grid = {'reg_alpha':[1,2,3,4,5],'reg_lambda':[1,2,3,4,5]}# 设置模型其他固定参数model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下限scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况min_child_weight= 0.95,#最小叶子节点样本权重和,用于控制每个节点上的样本数量objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)
# 网格搜索实例化grid_search = GridSearchCV(model_xgb,params_grid,cv=5,scoring='roc_auc')# 执行网格搜索grid_search.fit(X_train,y_train)# 查看网格搜索得出的最优参数和最优得分grid_search.best_params_grid_search.best_score_
scale_pos_weight
简要介绍
scale_pos_weight主要用于样本不均衡的调节,调节这个参数的本质是增加了对少数类样本的学习。scale_pos_weight的变换可能引起样本预测概率数值的变化,但并不影响样本正负排序的变化。因此,通常情况下,如果我们以AUC为目标训练模型,可以对这一参数进行调节,如果以损失函数最小化为目标训练模型,则不建议对这个参数进行调节。
更新模型
经过上述一系列的优化,我们就得到了下面的新模型:
# 模型参数设定model_xgb = xgb.XGBClassifier(n_estimators= 800,#评估器数量,也就是生成数的数量max_depth= 12,#树的最大深度subsample= 0.4,#训练时的采样比例eta=0.01,#学习率,控制每次学习的权重缩减gamma=8,#叶子节点分裂时的损失减少量下线scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况reg_alpha= 0,#L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合min_child_weight= 0.95,#最小叶子节点样本权重和,用于控制每个节点上的样本数量objective='binary:logistic',#训练目标,影响损失函数及输出结果seed= 42,#随机数种子verbosity=1,#训练日志打印等级nthread= -1,#并行线程数eval_metric= 'auc'#评估指标)# 模型训练model_xgb.fit(X_train,y_train)# 模型预测y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]# 模型评估print('-----------------------train score----------------------')model_evaluate(y_train,y_pre_train_xgb)print('-----------------------test score-----------------------')model_evaluate(y_test,y_pre_test_xgb)
并得到了如下效果:
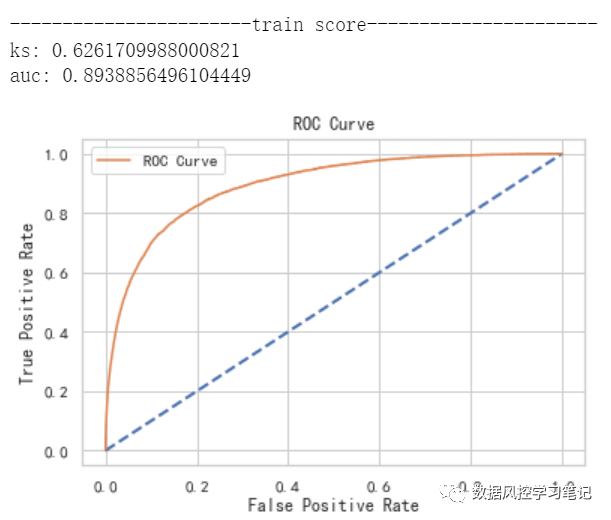
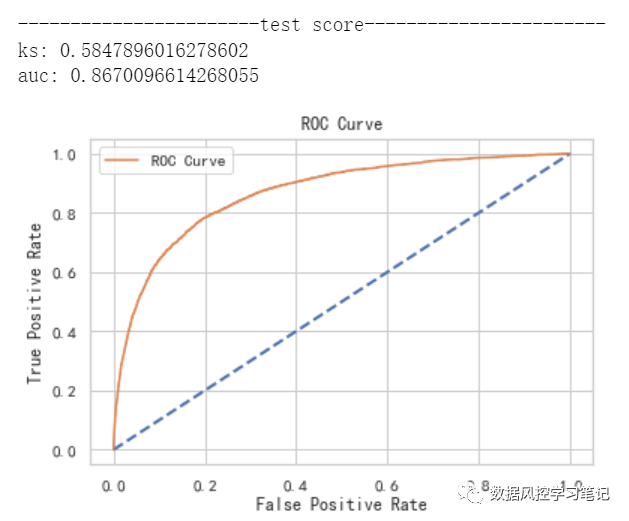
还记得吗,咱们初始模型的表现是这样的:
训练集:ks约为0.583,auc约为0.867
测试集:ks约为0.570,auc约为0.858
经过本次调参后,新模型的表现是这样的:
训练集:ks约为0.626,auc约为0.894
测试集:ks约为0.585,auc约为0.867
通过本次调参实验,我们对Xgboost中的常见参数有了更深入的理解,模型在训练集和测试集也都表现出了一些提升,在以后的实际运用中,小伙伴们也可以参考上述的调参思路,持续优化自己的模型了,不过,如果想要更深入得理解每个参数代表的含义,就需要进一步对Xgboost的原理和公式推导进行学习啦~


