




Kaggle项目GiveMeSomeCredit实战
逮噶猴,经过几个月的闭关修炼,小记逐渐掌握了一些python基础知识(随后也会逐渐通过公众号分享给大家),已经迫不及待磨拳擦掌地想要通过项目实战巩固下从B站和书本里学到的数据分析和风控建模技能了。正好碰上春节假期,二话不说,就从现在开始,着手做个项目试试看吧!
在自学数据分析和建模的过程中,很多小伙伴都希望能够寻找一些靠谱数据和项目练手,kaggle作为一个国际化的数据科学竞赛平台,可以说是小伙伴们试水的绝佳选择啦。小记就职于风控行业,接触最多了解最深的就是风控行业的数据分析及建模流程,所以本次特地选取了kaggle平台上的经典案例give me some credit,基于这个案例进行数据清洗、数据预处理、特征筛选、特征分箱、模型训练、模型评估和评分卡映射一系列的实操试验,并且持续分享在公众号里哦~
这次首先分享的是使用xgboost进行简单建模,xgboost具有高效率高精度的特点,在数据科学竞赛和工业生产中都有着广泛的运用,下面就是具体的建模流程啦:
数据源:give me some credit数据集
数据源介绍:
来源于kaggle官网,主要为个人在银行的基本信息及信贷信息。

数据源地址:https://www.kaggle.com/c/GiveMeSomeCredit/data
建模目标:通过某客户在过去的个人信息及信贷信息信贷信息预测该客户在未来两年经理财务困境的概率,为银行的授信决策提供依据。
评价标准:AUC
关注重点:使用xgboost进行简单建模
环境配置
# 基本功能import pandas as pdimport numpy as np# 画图import matplotlib.pyplot as pltimport seaborn as sns# 数据处理from sklearn.model_selection import train_test_splitfrom sklearn.model_selection import KFold, cross_validatefrom sklearn.preprocessing import OneHotEncoderimport imblearn# 模型算法import xgboost as xgb# 模型评价from sklearn.metrics import roc_curvefrom sklearn.metrics import auc,roc_auc_scorefrom sklearn.metrics import accuracy_score,confusion_matrix,f1_scorefrom sklearn.model_selection import cross_val_score# 风控import toadfrom toad.plot import bin_plot,badrate_plot# pd显示配置pd.set_option('precision',3)pd.set_option('display.float_format',lambda x:'{:.4f}'.format(x))# sns风格与装饰sns.set(style='whitegrid',font='Simhei')# 系统路径import osos.chdir(r'C:\Users\28779\Desktop\GiveMeSomeCredit\GiveMeSomeCredit')# 输出每个cell代码返回的所有结果from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = 'all'# 屏蔽提示import warningswarnings.filterwarnings('ignore')
读取数据
# 训练数据示例data = pd.read_csv('cs-training.csv')
数据字典信息如下:
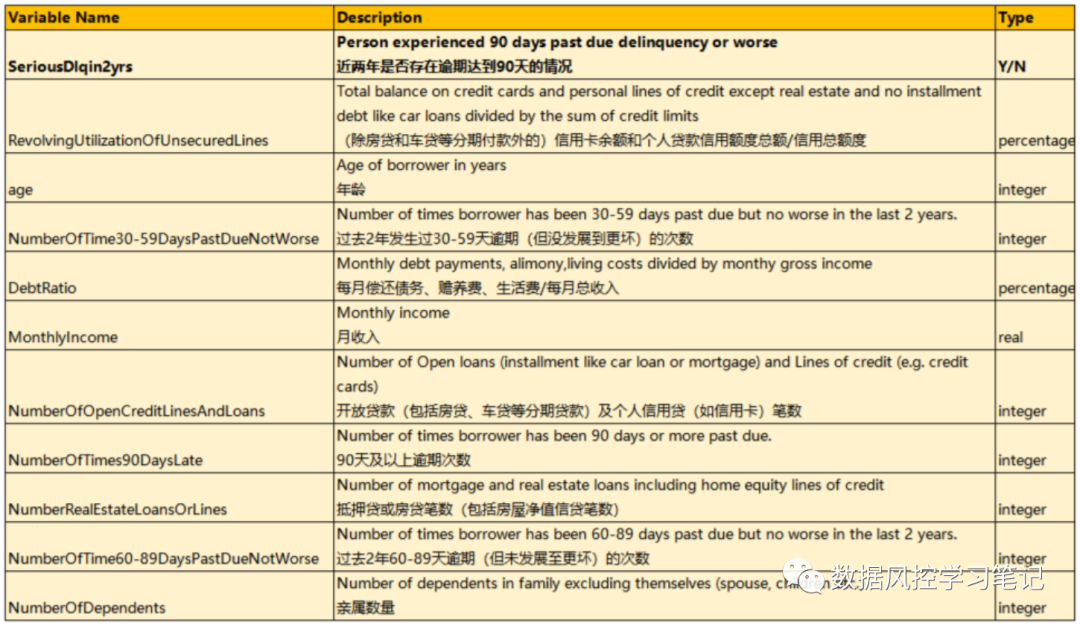
# 查看尾部两行data.tail(2)# 查看&重命名列data.columnsdata.drop(columns='Unnamed: 0',inplace=True)column = ['target', 'RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']data.columns = columndata.head()

# 区分特征与标签fea = ['RevUtilOfUnsecLines', 'age','30-59DPD', 'DebtRatio', 'MonthlyIncome','NumOfOpCreAndLoans', 'NumOf90DPD','NumReaEstLoansOrLines', '60-89DPD','NumberOfDependents']label = 'target'ex_lis = []
数据概览
# 查看标签分布data.target.value_counts()print('坏样本浓度为{:.4f}%'.format(100*data.target.mean()))
0 139974
1 10026
Name: target, dtype: int64
坏样本浓度为6.6840%
# 查看数据重复情况data.duplicated().sum()# 查询重复数据明细data[data.duplicated()]
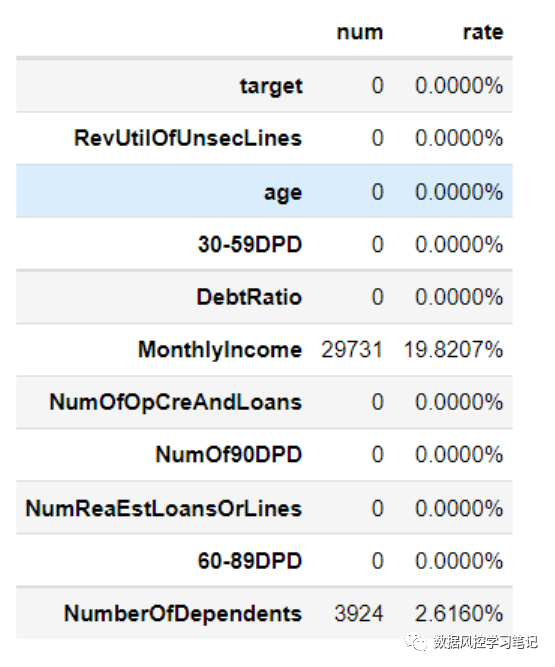
# 查看数据缺失情况missing_num = data.isna().sum()missing_rate = data.isnull().sum()/(data.isna().count())df_missing = pd.DataFrame({'num':missing_num,'rate':missing_rate})df_missing.rate = df_missing.rate.apply(lambda x :'{:.4f}%'.format(100*x))df_missing
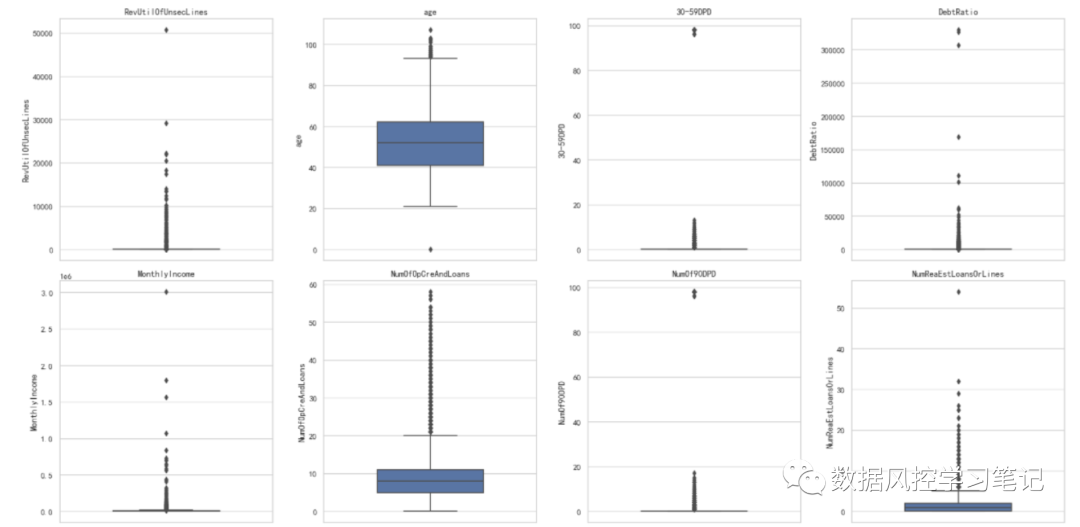
# 查看异常数据情况plt.figure(figsize=(20,15),dpi=100)for i in range(len(fea)):plt.subplot(3,4,i+1)sns.boxplot(y=data[fea[i]],orient='v',width=0.5)plt.title(fea[i])plt.tight_layout()plt.show()
数据划分
# 抽取30%的验证集X_train,X_test,y_train,y_test = train_test_split(data[fea],data[label],test_size=0.3,random_state=42)data_training = pd.concat([X_train,y_train],axis=1)data_test = pd.concat([X_test,y_test],axis=1
模型训练
# 参数设定model_xgb = xgb.XGBClassifier(objective='binary:logistic',n_estimators= 200,max_depth= 12,min_child_weight= 1,seed= 42,subsample= 0.8,reg_alpha= 0, #L1正则化项的系数,用于减轻过拟合reg_lambda= 1,#L2正则化项的系数,用于减轻过拟合verbosity=2,#训练日志打印等级silent=0,nthread= -1,#并行线程数n_jobs=-1,eta=0.01,#学习率,控制每次学习的权重缩减gamma=10,#叶子节点分裂时的损失减少量下线scale_pos_weight=1,#样本权重,通常用于处理样本不均衡的情况early_stopping_rounds = 200,eval_metric= 'auc')
# 交叉验证cv = KFold(n_splits=5,shuffle=True,random_state=1412)model_xgb_cv = cross_val_score(model_xgb,X_train,y_train,cv=cv,scoring='roc_auc')model_xgb_cv.mean()model_xgb_cv.var()
0.8589933800296461
3.090204263415678e-05
# 模型训练model_xgb.fit(X_train,y_train)# 模型预测y_pre_train_xgb = model_xgb.predict_proba(X_train)[:,1]y_pre_test_xgb = model_xgb.predict_proba(X_test)[:,1]
模型预测
# 评估函数def model_evaluate(y_true,y_pre):'''input:y_true,series,样本标签,0或1y_pre,series,样本预测值,范围不限output:ks,auc,float,模型ks,auc指标值ROC图'''fpr,tpr,thresholds=roc_curve(y_true,y_pre,pos_label=None,sample_weight=None,drop_intermediate=True)ks_cal = abs(fpr-tpr)ks = max(ks_cal)print('ks:',ks)auc = roc_auc_score(y_true,y_pre)print('auc:',auc)# plotplt.figure()plt.plot([0,1],[0,1],lw=2,linestyle='--')plt.plot(fpr,tpr,label='ROC Curve')plt.title('ROC Curve')plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.legend()plt.show()return ks,auc
# 模型评估model_evaluate(y_train,y_pre_train_xgb)model_evaluate(y_test,y_pre_test_xgb)
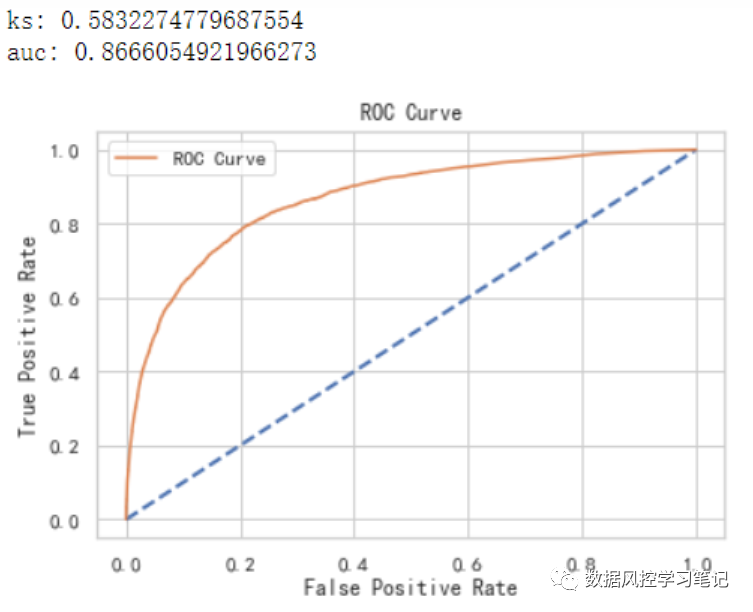
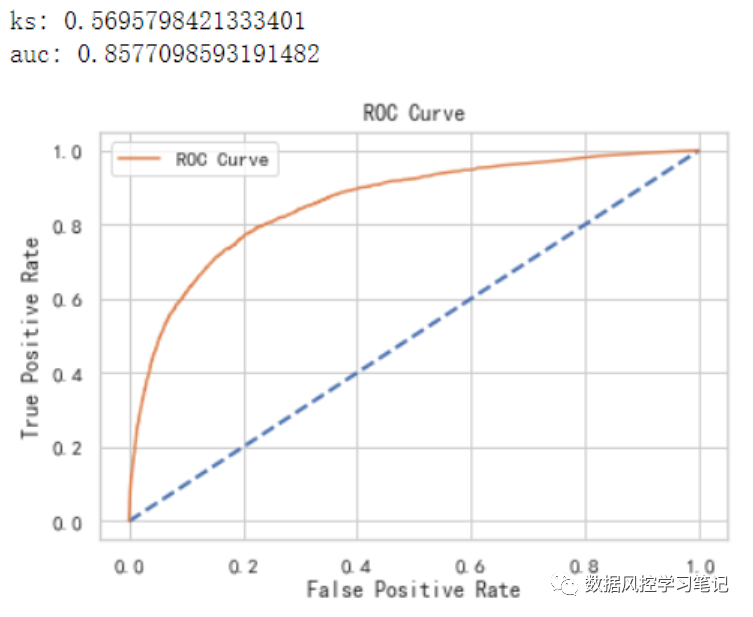
可以看到,经过训练后的Xgboost模型表现如下:
训练集:ks约为0.583,auc约为0.867
测试集:ks约为0.570,auc约为0.858
以上,我们建立了简单的Xgboost模型,并且取得了一个还不错的auc结果,但其实,其实这个过程中还有许多可以调整和提升的地方,例如缺失值的处理、模型参数的调整等,小记也会持续和大家分享~


