




最近在Oracle到PostgreSQL的迁移过程中,遇到了一个bitmap索引。在PostgreSQL中是没有位图索引的,因为PostgreSQL的bitmap是在执行SQL的过程中,由优化器选择执行bitmapscan时候动态创建的。
而aws的文档给出的转换指导方案就是把Bitmap索引转换成Brin索引,并不能完全等价,但是会有一些效果。以下是原文:
PostgreSQL does not provide native support for BITMAP indexes. However, a BRIN index, which splits table records into block ranges with MIN/MAX summaries, can be used as a partial alternative for certain analytic workloads. For example, BRIN indexes are suited for queries that rely heavily on aggregations to analyze large numbers of records.
However, Oracle BITMAP indexes and PostgreSQL BRIN indexes are not implemented in the same way and cannot be used as direct equivalents.
什么是Brin索引?
从PostgreSQL 9.5开始,实现了一个称为块范围索引(BRIN)的新索引。BRIN索引是一组物理上相邻的块(页面),并保存每组的值的范围(最小值和最大值)。当在数据仓库系统执行聚合分析查询巨大表时,此方法非常有效。这样可以缩小搜索时的扫描范围。
Brin的想法就是避免扫描绝对不合适的行,这是一个很天才的想法。根据Wiki的描述,这项技术其他厂商也有类似的功能,如Oracle Exadata的存储索引,Netezza的Zone Maps,还有infobright的data packs、MonetDB和Apache Hive with ORC/Parquet。
下面我们来具体了解一下他的结构,如下图所示(图片来源于Satoshi Nagayasu先生的分享的PPT),左边的Table是有很多个Page页面组成的。而第一个Block范围,是1-128个Page。我们得到日期的最小值是1992-01-02,而最大值是1992-01-28。而第二个范围Range 2的最小值和最大值是1992-01-27和1992-02-08。而第三个范围 Range 3的最小值和最大值是1992-02-08和1992-02-16。表上总共这些page页面对应右边只需要有三行信息,这三行存储在Brin索引当中。因此Brin索引要比传统的B-Tree索引小很多。

Brin的优点
顺序扫描会很快,它是索引顺序扫描的一种改进,如果键值的顺序和存储中块的组织顺序相同,则针对大表的统计型SQL性能会大幅提升。 创建索引的速度非常快。 索引占用的空间很小。
Brin索引使用和B-Tree对比
首先我们创建一张表,并往里面插入数据,我这里列一个时间范围2017年-2023年,每2秒就插入一条记录。
postgres=# CREATE UNLOGGED TABLE t1 (id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, num1 float NOT NULL,created TIMESTAMP NOT NULL);
CREATE TABLE
postgres=# INSERT INTO t1 (num1, created) SELECT random(), x FROM generate_series('2017-01-01 0:00'::timestamp,'2023-01-01 00:00:00'::timestamp, '2 seconds'::interval) x;
INSERT 0 94651201
无索引查询
执行一个查询,where条件指定一个时间的范围,然后分组求第二列随机数的和。
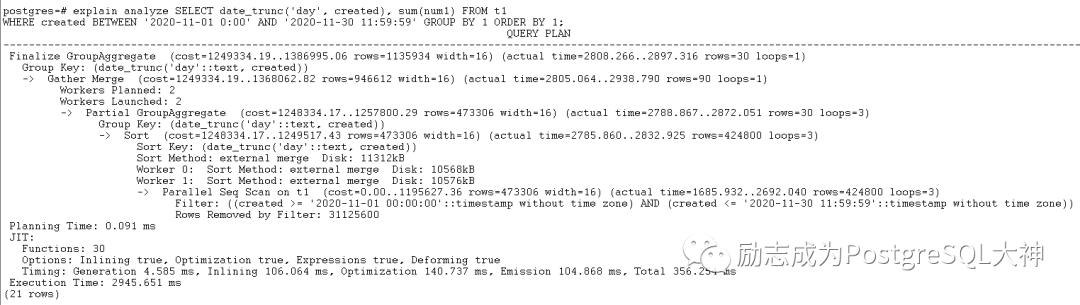
全表扫描自动开启了2个并行查询进程,执行时间要2.9秒。
B-Tree索引查询
接下来我们在时间列上创建一个b-tree索引,创建索引时间大概38秒。
postgres=# create index idx_t1_date on t1(created);
CREATE INDEX
Time: 38634.998 ms (00:38.635)

再次执行可以看到走了b-tree索引。极大的提高了select查询的效率,多次执行下来需要986ms。
Brin索引查询
接下来我们删除b-tree索引再创建brin索引,Brin索引创建时间大概是23秒左右,创建速度比B-tree索引快了大概39%。
postgres=# drop index idx_t1_date;
postgres=# CREATE INDEX idx_created__brin_idx ON t1 USING brin(created);
CREATE INDEX
Time: 23826.853 ms (00:23.827)

再次执行查询使用了brin索引,发现只需要453ms。比B-tree索引快一些。经过多次测试执行查询速度快了大概50%左右。
对比B-tree和Brin索引的大小
然后我们来观察下索引的大小。
postgres=# SELECT pg_size_pretty( pg_total_relation_size('t1'));
pg_size_pretty
----------------
7557 MB
(1 row)
postgres=# SELECT pg_size_pretty( pg_total_relation_size('idx_t1_date'));
pg_size_pretty
----------------
2028 MB
postgres=# SELECT pg_size_pretty( pg_total_relation_size('idx_created__brin_idx'));
pg_size_pretty
----------------
208 kB
(1 row)
我们的表7.5GB,B-tree索引是2GB,而我们的Brin索引居然只有208KB,太不可思议了,仅仅是传统B-tree索引的1/100。
针对这个SQL不管是在的查询性能,还是在大小、创建时间上,Brin索引都完胜B-tree索引。
Brin索引的缺点
上面介绍了Brin的优点,现在我们来说说它的缺点?
我们首先安装pageinspect插件,先通过插件来更进一步观察Brin索引的内容。
postgres=# create extension pageinspect;
CREATE EXTENSION
通过下面的查询,我们可以清楚的看到每个块区域的最大值和最小值。
select blknum, value from brin_page_items(get_raw_page('idx_created__brin_idx',6),'idx_created__brin_idx')
order by blknum;

从上面可以发现,Brin在很大程度上依赖于数据相邻性(在磁盘上附近发现相似的数据)。如果我们的数据非常的混乱,则Brin索引查询重叠的条目可能性就非常高。一旦我们的Brin索引开始重叠,就将匹配更多的记录,并且导致需要从源表中读取多个块范围,以找到我们要查找的记录。
接下来我们就来演示一下这个过程。我创建一个表,时间是乱序插入的。
CREATE UNLOGGED TABLE t2 (id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, num1 float NOT NULL,created TIMESTAMP NOT NULL);
INSERT INTO t2 (num1, created)
select random(),
date (timestamp '2016-01-01' +
random() * (timestamp '2023-12-31' - timestamp '2017-01-01'))
+ random() * INTERVAL '24 hours'
+ random() * INTERVAL '60 seconds'
FROM generate_series(1,100000000);
插入1个亿数据,然后再次创建索引。
postgres=# CREATE INDEX idx2_created__brin_idx ON t2 USING brin(created);
select blknum, value from brin_page_items(get_raw_page('idx2_created__brin_idx',6),'idx2_created__brin_idx')
order by blknum;
接下来我们使用pageinspect插件观察,可以看到大部分块的范围都是2016-01-01到2022-12-29这个范围。
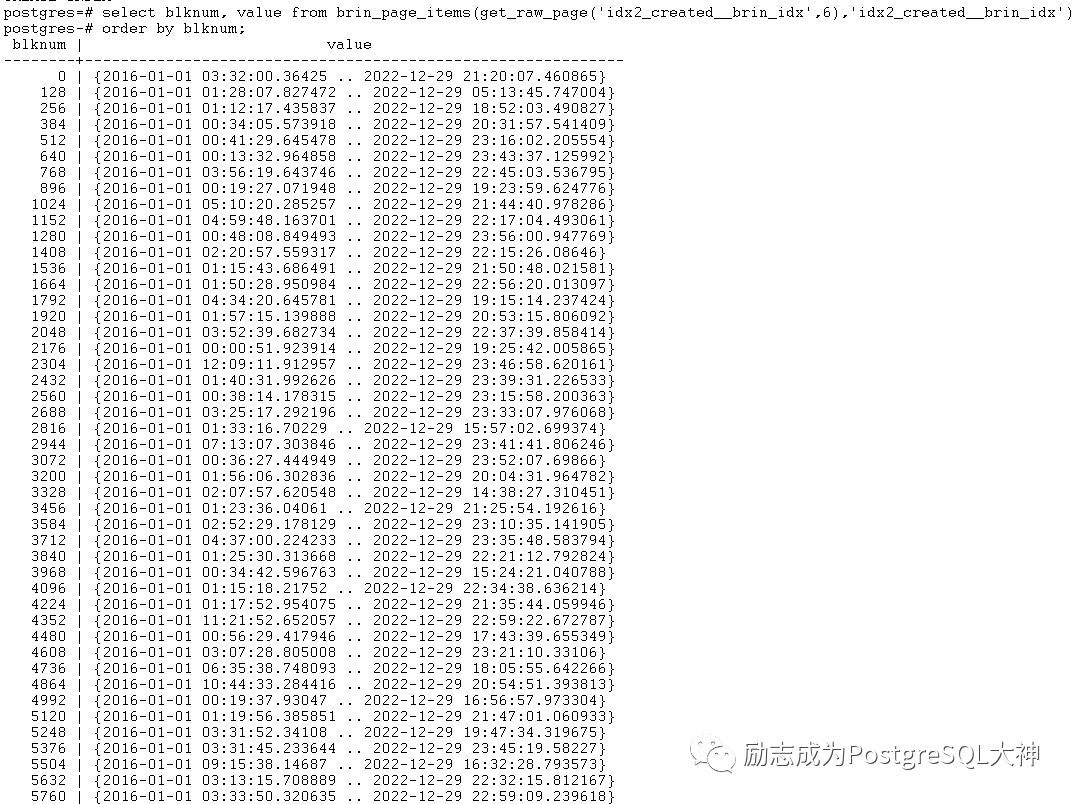
这样就会导致大量扫描,能过滤的数据非常少。这种效果和全表扫描几乎一样。执行同样的查询,优化器默认直接选择了全表扫描Seq_Scan。

我们使用hint强制走Brin索引。

可以看到使用Brin索引比全表扫描还要慢。
所以当表中的记录是无序插入的时候,创建Brin索引并不能提升查询效率,反而会降低查询速度。而在我们日常的数据库工作负载中,基本上对于OLTP的表,都有update、delete,会容易造成乱序。而对于OLAP那种历史表,迁移到历史数据库中我们可以顺序的加载,就会导致数据有序的插入,而且历史表我们很少去改动。当数据量大了之后,我们就可以创建Brin索引来提高查询扫描的速度。
参数pages_per_range
最后我们来看一下参数pages_per_range,该参数代表页面的范围,默认是128个页面。页面范围越大,索引越小,查询的时候扫描索引块就会很少,但是在内存中需要在去过滤页面就很多。而页面的范围越小,索引就越大,查询索引的时候就更加精细,由于每筛选一次字段 PostgreSQL 都要扫描全部的 BRIN 索引,所花费的时间也会变长。所以这个值的大或者小,需要实际根据SQL语句where表达式和表的大小来调整。
一般我的经验是较少的选择性查询通常可以提供更大的pages_per_range。
我们来测试一下。
pages_per_range=32
CREATE INDEX idx_created__brin_idx ON t1 USING brin(created) with (pages_per_range=32);
通过pageinspect插件观察,可以看到每32个页面,就有一个索引条目,包含min..max的value。

总结
Brin索引的使用是有一定的局限性
,最好需要自己根据业务使用场景进行创建,它并不是万能的解药。

最终还是需要我们DBA来进行判断。在正确的使用场景下,它可以Diao打B-tree索引。
