




前言

前面讲了状态机的各种状态,今天我们来介绍一下多节点架构。
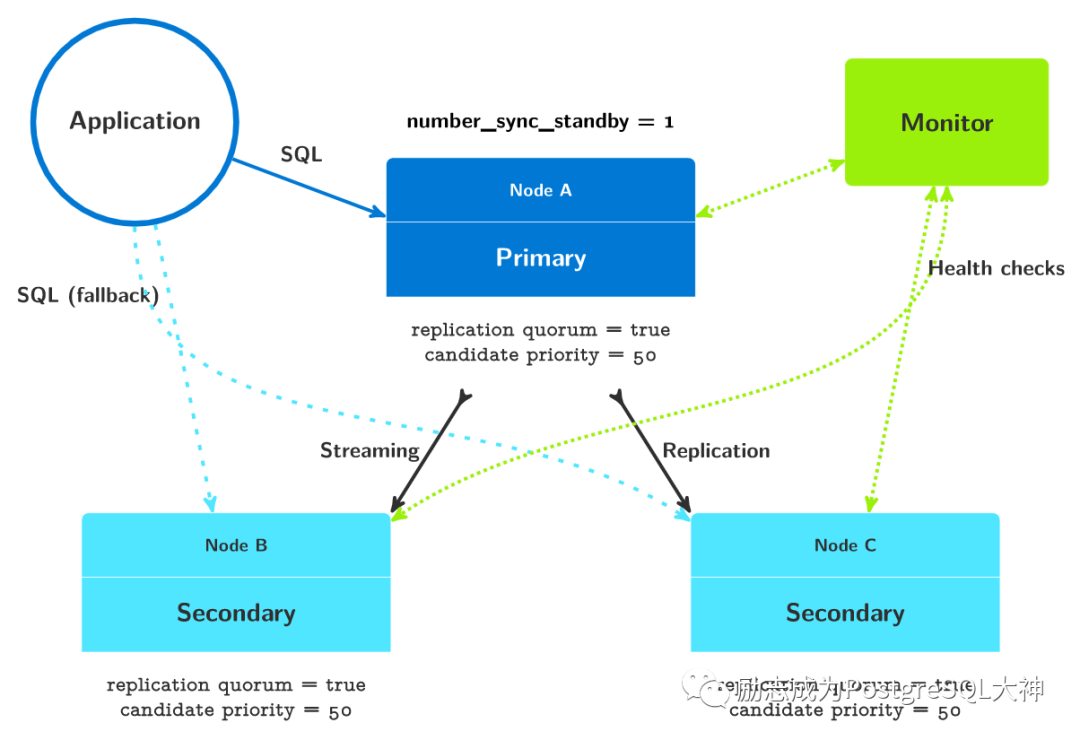
具有两个备库的架构
先看我们一主一从架构,集群主要包括以下参数设置。
[postgres@paf1 ~]$ pg_autoctl get formation settings
Context | Name | Setting | Value
----------+---------+---------------------------+------
formation | default | number_sync_standbys | 0
primary | node_4 | synchronous_standby_names | '*'
node | node_4 | candidate priority | 50
node | node_5 | candidate priority | 50
node | node_4 | replication quorum | true
node | node_5 | replication quorum | true
然后添加一个节点,形成图中的一主二从的架构。
pg_autoctl create postgres \
--hostname paf4 \
--auth trust \
--ssl-self-signed \
--monitor 'postgres://autoctl_node@paf1:5432/pg_auto_failover?sslmode=require' \
--run
增加完节点后
[postgres@paf2 ~]$ pg_autoctl show state
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
--------+-------+------------+------------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/11000148 | yes | primary | primary
node_5 | 7 | paf3:5432 | 0/11000148 | yes | secondary | secondary
node_13 | 13 | paf4:5432 | 0/11000148 | yes | secondary | secondary
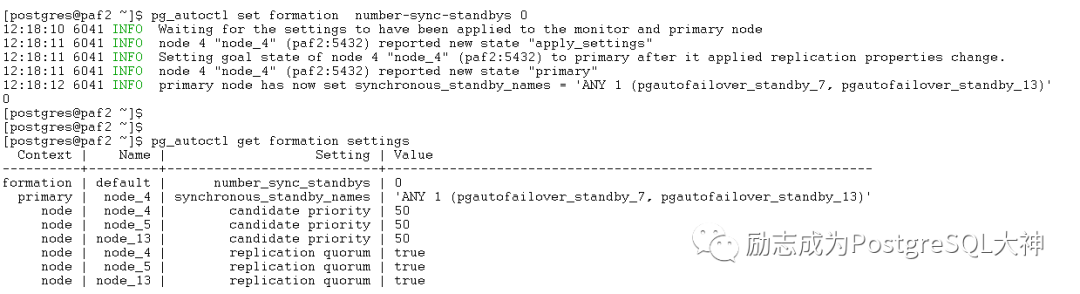
[postgres@paf2 ~]$ pg_autoctl get formation settings
Context | Name | Setting | Value
----------+---------+---------------------------+--------------------------------------------------------------
formation | default | number_sync_standbys | 1
primary | node_4 | synchronous_standby_names | 'ANY 1 (pgautofailover_standby_7, pgautofailover_standby_13)'
node | node_4 | candidate priority | 50
node | node_5 | candidate priority | 50
node | node_13 | candidate priority | 50
node | node_4 | replication quorum | true
node | node_5 | replication quorum | true
node | node_13 | replication quorum | true
添加新节点后,可以看到,number_sync_standbys
从0变成了1,而synchronous_standby_names
也从*变成了Any 1。
number_sync_standbys
该参数意味着当主库提交事务后,需要等待多少备用节点同步成功后才能完成提交。number_sync_standbys被设置为1,这种架构将始终保留两份数据,一个是当前主节点 A,另一个是首先确认交易的备库(图中的任意一个节点 B或节点 C)。在其中一个备用节点不可用的情况下,因为还有一个备库,仍然可以保证数据有2份。而如果两个备用库都不可用,就不能再保证进行复制仲裁了。主节点在此时被阻止写入,主节点将等待至少一个备用节点恢复,确认本地提交的事务才会变成可写状态。
让我们来测试一下,是否可以直接将两个物理从库关闭,看看是否还能写入。首先在监控节点上直接执行快速插入脚本。
postgres=# CREATE TABLE t1 (id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, name text);
CREATE TABLE
##循环插入脚本
while true
do
psql 'postgres://192.168.56.94:5432,192.168.56.95:5432,192.168.56.99:5432/postgres?target_session_attrs=read-write' <<EOF
select inet_server_addr();
select now();
insert into t1(name) values(md5(random()::text));
EOF
sleep 1
done
##直接关闭paf3 paf4两个主机,也就是两个从库
[postgres@paf2 ~]$ pg_autoctl show state
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
--------+-------+------------+------------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/1100A8E8 | yes | primary | primary
node_5 | 7 | paf3:5432 | 0/1100A270 | no | secondary | catchingup
node_13 | 13 | paf4:5432 | 0/1100A7E8 | no | secondary | catchingup
这时,观察循环插入脚本的位置,发现事务已被卡住,登录命令行执行也已被卡住。

看一下pg_stat_activity,它们都在等待 SyncRep。

造成这个原因主要就是PostgreSQL参数被设置成了ANY 1,此时必须要有至少一个备库同步了才能让你可写。它和集群number_sync_standbys参数保持一致,集群这里也是1
因此,我们首先来调整集群参数试一下。
首先将number_sync_standbys调整为0,看得到的还是不行。由于参数synchronous_standby_names没有跟上变化,而且整个集群里找不到修改synchronous_standby_names的位置。因此,我想是不是应该在集群正常时进行修改?因此,我重新启动所有节点,然后将所有节点都转换为0。在停止paf3和paf4之后,发现节点仍然处于无法写入的状态。synchronous_standby_names参数仍然是配置为 any 1。那这就说明,当两个从库挂了之后,还需要手动修改synchronous_standby_names
的配置为*才能让主库可写。集群没有办法更改synchronous_standby_names
的配置。
如果是一主三从的情况,当增加第三个从库的时候,number_sync_standbys将默认修改为2。也就是需要保证2个从库一致同步。而数据库中的参数synchronous_standby_names
也会变成ANY 2。
Replication quorum
可以将该参数设置为 true或 false,默认情况下为 true。仅当replication-quorum被设置为 true时,才会在synchronous_standby_names参数中设置该节点。
如果将其设置为 false,将使用异步复制。在集群中将全部replication-quorum设置为 false,就会强制进行异步复制。
Candidate Priority
该参数表示优先权。它可设为从0 (0)到100 (100)的任意一个值。缺省值是50。如果 Monitor节点决定协调故障转移,则使用每个节点的候选者优先权来选择新的主节点。
在 Monitor节点安排故障转移时,将节点的候选者优先级设置为零时,将不会选择将该节点升级为新的主节点,而 Monitor节点将改为等待,直到注册的其他节点正常工作并且处于要升级的位置。
当节点具有相同的候选优先级时,Monitor节点将选择具有最高的LSN位置的备用节点。当多个节点发布了相同的LSN位置时,将选择一个随机节点。当故障转移候选者尚未在发布最高的LSN位置时,pg_auto_failover会安排故障转移机制的中间步骤。候选对象在升级前从具有最高级 LSN位置的备用数据库中获取丢失的 WAL字节, Postgres允许这样做,因为 Postgres的级联复制:任何备用数据库都可以是另一个备用数据库的上游节点。
在pg_auto_failover集群中,任何时间都必须至少有两个节点具有非零候选优先级。不然就不能进行故障转移。
一主三从架构图
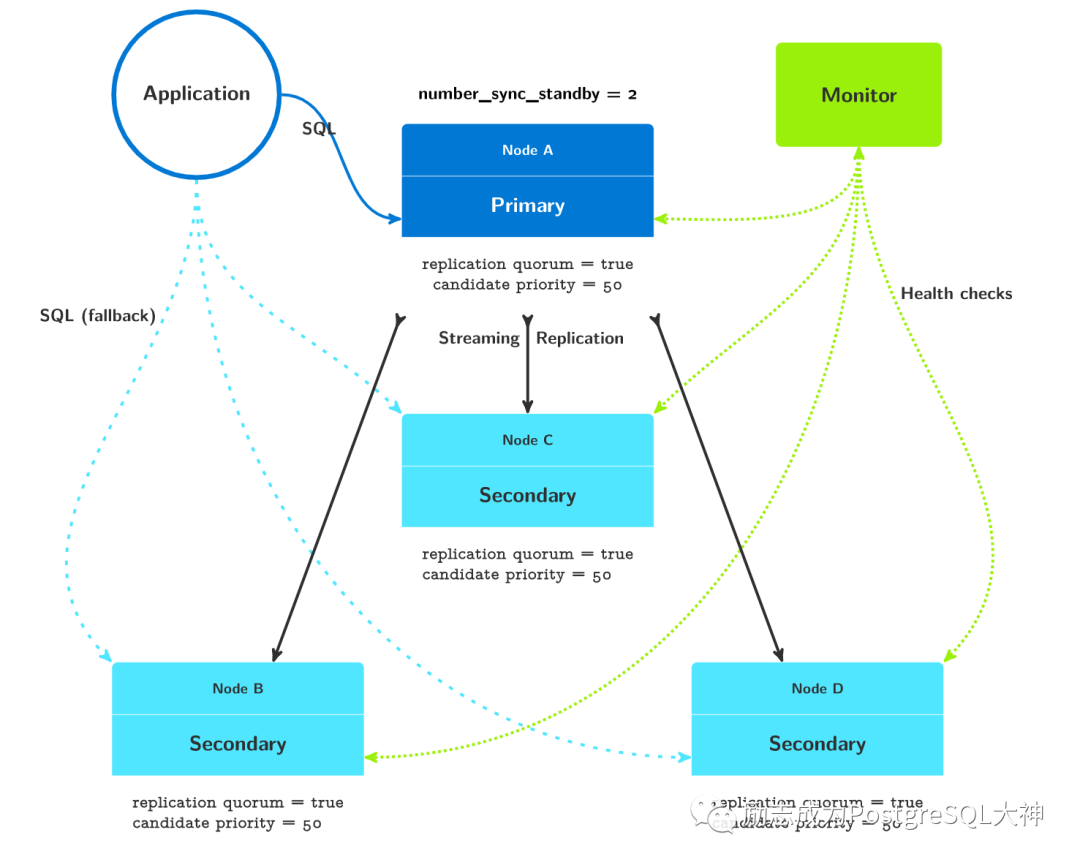
一主三从相对于一主二从,如前所述,参数number_sync_standbys这里是2,这意味着 Postgres总是保留生产数据集的三个副本。当两个备用节点同时失败时,尽管两个数据副本实际上仍在运行,但它们将进入只读模式。
一主三从,一个异步的架构图
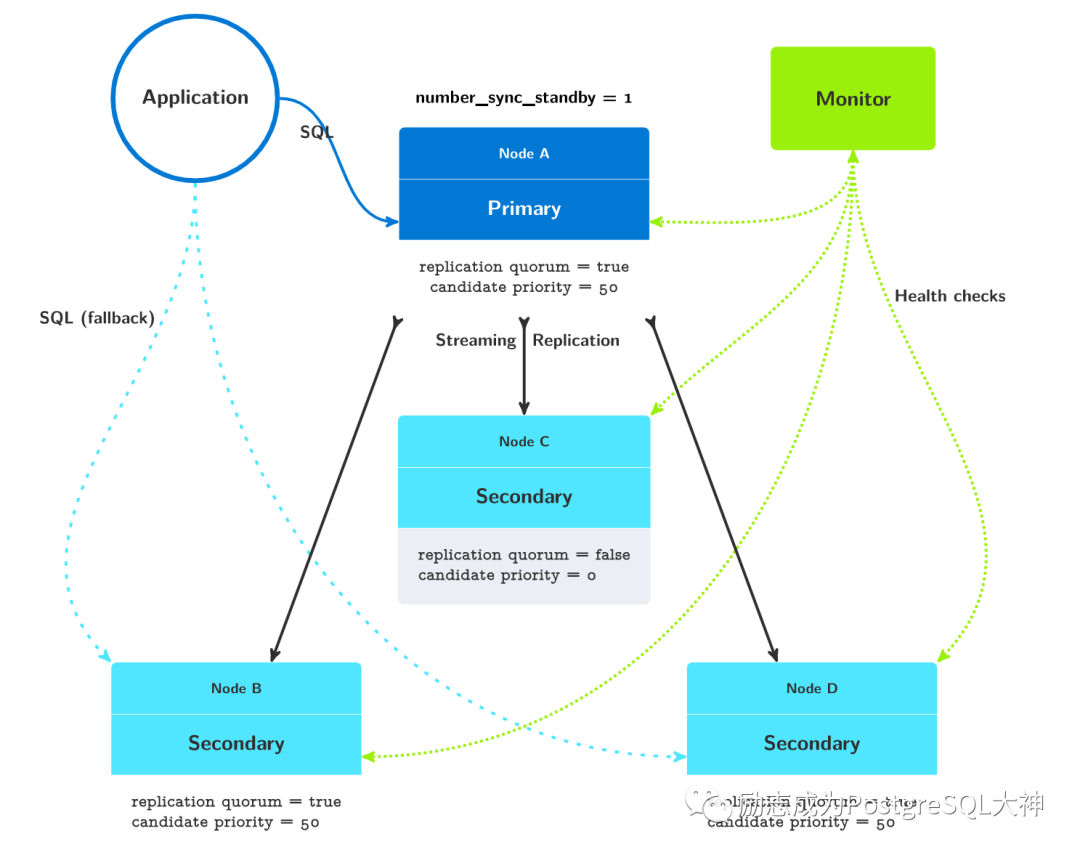
这种架构适合以下情况:节点A,B和D部署在同一数据中心或可用性区域中,而节点C部署在另一个数据中心或可用性区域中。设置这三个节点以支持主要的生产流量并实现Postgres服务和数据集的高可用性。在第一个数据中心断电或者是发生自然灾害的情况下,可以为应用程序切换到另一个数据中心的节点C。
统将设置两个参与复制仲裁的备用节点,系统总是维护至少两个数据集副本,其中一个位于主数据库上,另一个位于节点 B或节点 D上。无论何时这些节点中有一个丢失,我们都保证有两个数据集副本。另外,我们有一个备用服务器 C,它被设置为不参与复制仲裁。无法在节点synchronous_standby_names列表中找到 C节点。节点 C也永远不能进行故障转移(candidate-priority=0)。
总结
总体来说,PAF多节点的架构比较好理解和使用,有点类似于MySQL中的MHA架构。但是有一点我觉得并不是很智能。比如我的一主两从,我设置了集群的number_sync_standby为0。在我关闭两台从库之后,节点A将变成只读状态,而不能切换到可写状态。需要我手工到数据库修改参数,这有点设置不合理。我希望集群进程知道备库全部故障之后,能够自动从同步状态降级为异步状态,保障业务的连续可写性。希望以后的版本能加以改进。
