




前言

之前测试 ctid时,在执行 vacuuman alyze回收update产生的旧元组之后,就发现了无法重新使用的问题。如以下测试所示:
create table t(id serial);
insert into t values(generate_series(1,3));
postgres=# SELECT (ctid::text::point)[0]::bigint AS page_number,
(ctid::text::point)[1]::bigint AS tuple_number,
id from t;
page_number | tuple_number | id
-------------+--------------+----
0 | 1 | 1
0 | 2 | 2
0 | 3 | 3
(3 rows)
postgres=# update t set id=4 where id=3;
UPDATE 1
postgres=# SELECT (ctid::text::point)[0]::bigint AS page_number,
(ctid::text::point)[1]::bigint AS tuple_number,
id from t;
page_number | tuple_number | id
-------------+--------------+----
0 | 1 | 1
0 | 2 | 2
0 | 4 | 4
postgres=# vacuum analyze t;
VACUUM
postgres=# insert into t values(3);
INSERT 0 1
postgres=# SELECT (ctid::text::point)[0]::bigint AS page_number,
(ctid::text::point)[1]::bigint AS tuple_number,
id from t;
page_number | tuple_number | id
-------------+--------------+----
0 | 1 | 1
0 | 2 | 2
0 | 4 | 4
0 | 5 | 3
(4 rows)
可以发现新插入的数据,会选择使用(0,5),而不是(0,3)这个vacuum回收的空间。
有索引的情况下
创建索引之后,再次测试 Update操作,然后执行 vacuum analyze。
postgres=# drop table t;
DROP TABLE
postgres=# create table t(id serial);
CREATE TABLE
postgres=# insert into t values(generate_series(1,3));
INSERT 0 3
postgres=# create index idx_t1 on t(id);
CREATE INDEX
postgres=# update t set id=4 where id=3;
UPDATE 1
postgres=# SELECT (ctid::text::point)[0]::bigint AS page_number,
postgres-# (ctid::text::point)[1]::bigint AS tuple_number,
postgres-# id from t;
page_number | tuple_number | id
-------------+--------------+----
0 | 1 | 1
0 | 2 | 2
0 | 4 | 4
(3 rows)
postgres=# vacuum analyze t;
VACUUM
postgres=# insert into t values(3);
INSERT 0 1
postgres=# SELECT (ctid::text::point)[0]::bigint AS page_number,
(ctid::text::point)[1]::bigint AS tuple_number,
id from t;
page_number | tuple_number | id
-------------+--------------+----
0 | 1 | 1
0 | 2 | 2
0 | 3 | 3
0 | 4 | 4
(4 rows)
可以发现这次使用了(0,3)这个回收的空间。与索引有一定的关联。通过使用 pageinspect插件,我们可以更深入地分析
## 一开始,表和索引的ctid都是一致的。
postgres=# SELECT t_ctid,t_xmin, t_xmax,t_data FROM heap_page_items(get_raw_page('t',0));
t_ctid | t_xmin | t_xmax | t_data
--------+--------+--------+------------
(0,1) | 118985 | 0 | \x01000000
(0,2) | 118985 | 0 | \x02000000
(0,3) | 118985 | 0 | \x03000000
postgres=# SELECT * FROM bt_page_items('idx_t1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-------+---------+-------+------+-------------------------+------+-------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
(3 rows)
## 更新之后
postgres=# update t set id=4 where id=3;
UPDATE 1
postgres=# SELECT t_ctid,t_xmin, t_xmax,t_data FROM heap_page_items(get_raw_page('t',0));
t_ctid | t_xmin | t_xmax | t_data
--------+--------+--------+------------
(0,1) | 118985 | 0 | \x01000000
(0,2) | 118985 | 0 | \x02000000
(0,4) | 118985 | 120091 | \x03000000
(0,4) | 120091 | 0 | \x04000000
(4 rows)
postgres=# SELECT * FROM bt_page_items('idx_t1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-------+---------+-------+------+-------------------------+------+-------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
4 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
您可以看到在更新之后,索引的 ctid和表的 ctid是不一致的。ctid索引仍按顺序增长,而表中的 ctid在更新前和更新后, ctid值是相同的,都增加了一位变成(0,4),不同的是,上面的t_xmax事务 id不同。
接下来我们来做vacuum analyze操作。
postgres=# vacuum analyze t;
VACUUM
postgres=# SELECT t_ctid,t_xmin, t_xmax,t_data FROM heap_page_items(get_raw_page('t',0));
t_ctid | t_xmin | t_xmax | t_data
--------+--------+--------+------------
(0,1) | 118985 | 0 | \x01000000
(0,2) | 118985 | 0 | \x02000000
| | |
(0,4) | 120091 | 0 | \x04000000
(4 rows)
postgres=# SELECT * FROM bt_page_items('idx_t1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-------+---------+-------+------+-------------------------+------+-------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
(3 rows)
在操作完成后,表上可以清除(0,4),t_max不为0的那一行,而索引上(0,3)的这一行可以清除,因此无论表或索引都可以清除。
接下来随便插入值。
postgres=# insert into t values(3);
INSERT 0 1
postgres=# SELECT t_ctid,t_xmin, t_xmax,t_data FROM heap_page_items(get_raw_page('t',0));
t_ctid | t_xmin | t_xmax | t_data
--------+--------+--------+------------
(0,1) | 118985 | 0 | \x01000000
(0,2) | 118985 | 0 | \x02000000
(0,3) | 120136 | 0 | \x03000000
(0,4) | 120091 | 0 | \x04000000
(4 rows)
postgres=# SELECT * FROM bt_page_items('idx_t1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-------+---------+-------+------+-------------------------+------+-------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
4 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
(4 rows)
可以发现新插入的值ctid一起变成了(0,3),使用了回收的位置。
删除重复数据
ctid的另一个重要作用是帮助我们删除重复的数据,当然使用前提是在ctid不变的情况下,如果执行过程中发生一定的变化(比如vacuum和vacuum full)这两种情况,建议谨慎处理。
create table t(id serial);
insert into t values(generate_series(1,3));
insert into t values(generate_series(1,2));
postgres=# select * from t;
id
----
1
2
3
1
2
(5 rows)
首先查询出重复数据
postgres=# select ctid,id from t
postgres-# where ctid not in (select min (ctid) as min_ctid from t group by id);
ctid | id
-------+----
(0,4) | 1
(0,5) | 2
(2 rows)
postgres=# delete from t where ctid not in (select min (ctid) as min_ctid from t group by id);
DELETE 2
postgres=# select ctid,id from t;
ctid | id
-------+----
(0,1) | 1
(0,2) | 2
(0,3) | 3
(3 rows)
物理分片
使用 Oracle时, rowid常常被用来进行逻辑分片。而PostgreSQL也一样,使用的是 ctid。
postgres=# create table t(id serial);
CREATE TABLE
postgres=# insert into t values(generate_series(1,20000));
INSERT 0 20000
postgres=# create index idx_t1 on t(id);
CREATE INDEX
postgres=# SELECT max((ctid::text::point)[0]::bigint) from t;
max
-----
88
(1 row)
首先我可以查出总共使用了多少page页面,然后将1-20页分成1组。
SELECT * from t where (ctid::text::point)[0]::bigint in (0,20);
SELECT * from t where (ctid::text::point)[0]::bigint in (21,40);
SELECT * from t where (ctid::text::point)[0]::bigint in (41,60);
SELECT * from t where (ctid::text::point)[0]::bigint in (61,80);
SELECT * from t where (ctid::text::point)[0]::bigint in (81,100);
然后我们可以通过5个客户端将数据分成5片进行处理,大大的提高处理的效率。
关于CTID的性能问题
执行UPDATE
(其实是insert和delete结合)或VACUUM FULL
都将更改行的ctid,对于拥有许多列索引的表来说,这会导致写放大性能问题。Uber工程师提到了这个问题。详细信息请参阅::https://eng.uber.com/postgres-to-mysql-migration/
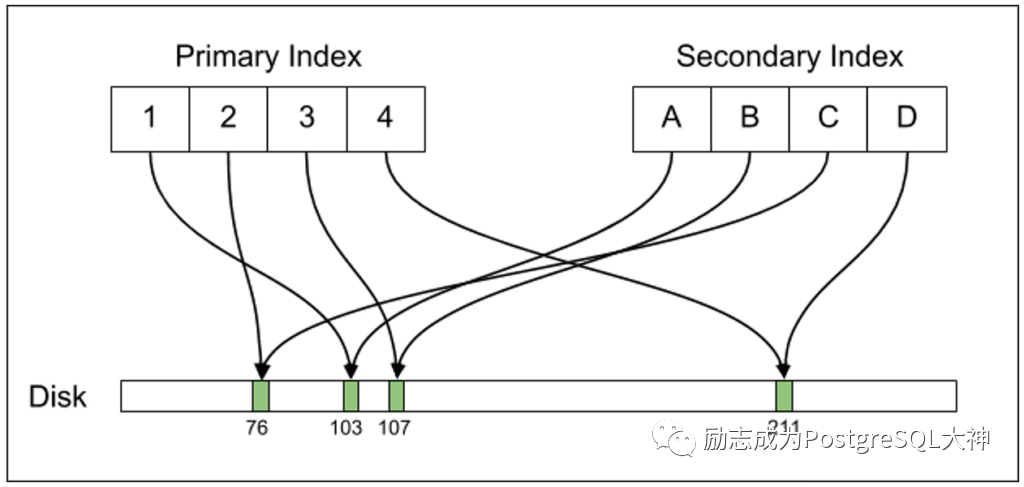
With Postgres, the primary index and secondary indexes all point directly to the on-disk tuple offsets. When a tuple location changes, all indexes must be updated.
因为索引是引用了行的ctid的,而当我们update一个不是索引的列,由于Update=Insert+Delete,它必定会更改行的ctid,因此将导致联动更新,即使该列不在索引中,也将更新索引的 ctid值,并指向新的位置。假定我的表有30个字段,8个索引,而其余22个字段没有索引,如果我一直在这些字段上执行 update,那么 ctid就会随修改而改变,导致索引也随之修改。为解决这一问题, PostgreSQL还推出了 Heap Only Tuple (HOT)技术。如果更新的新行和旧行位于同一数据块中,那么旧行将有一个指针指向新行,这样就不必更新索引,而只需通过索引访问旧行数据,然后指向新行数据即可。但这种技术仍无法解决的问题是,当我更新一个索引字段时,剩下的7个索引也将被更改,这样的问题也可以通过使用过间接索引来解决。
后记
CTID的问题先到这里,我们明天来看看Heap Only Tuple(HOT)技术。
