




Page Header(页面头部)
为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,这个部分占用固定的56个字节,专门存储各种状态信息。
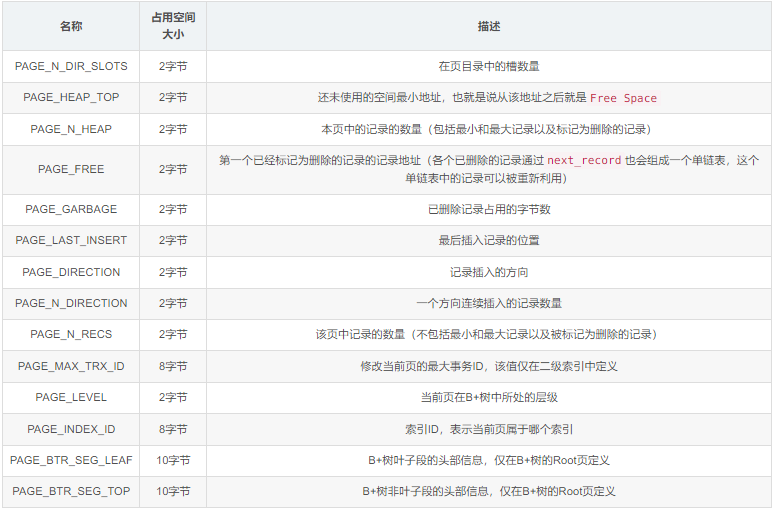
PAGE_DIRECTION:假如新插入的一条记录的主键值比上一条记录的主键值大,我们说这条记录的插入方向是右边,反之则是左边。用来标识最后一条记录插入方向的状态就是PAGE_DIRECTION。
PAGE_DIRECTION:假设连续几次插入新纪录的方向都是一致的,InnoDB会把沿着同一个方向插入记录的条数记下来,这个条数就用PAGE_DIRECTION这个状态标表示。当然,如果最后一条记录的插入方向改变了的话,这个状态的值会被清零重新统计。
从数据页的角度看B+树如何查询
一颗B+树按照节点类型可以分成两部分:
叶子节点,B+树最底层的节点,节点的高度为0,存储行记录。
非叶子节点,节点的高度大于0,存储索引键和页面指针,并不存储行记录本身。
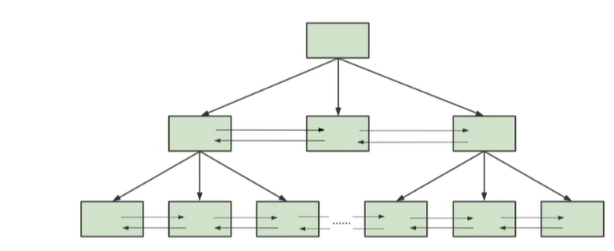
当我们从页结构来理解B+树的结构的时候,可以帮我们理解一些通过索引进行检索的原理:
B+树是如何进行记录检索的?
如果通过B+树的索引查询行记录,首先是从B+树的根开始,逐层检索,直到找到叶子节点,也就是找到对应的数据页为止,将数据页加载到内存中,页目录中的槽(slot)采用 二分查找 的方式先找到一个粗略的记录分组,然后再在分组汇总通过链表遍历的方式查找记录。
普通索引和唯一索引在查询效率上有什不同?
我们创建索引的时候可以是普通索引,也可以是唯一索引,那么这两个索引在查询效率上有什么不同呢?
唯一索引就是在普通索引上增加了约束性,也就是关键字唯一,找到了关键字就停止检索。而普通索引,可能会存在用户记录中的关键字相同的情况,根据页结构的原理,当我们读取一条记录的时候,不是单独将这条记录从磁盘中读出去,而是将这个记录所在的页加载到内存中进行读取。InnoDB存储引擎的页大小为16KB,在一个页中可能存储着上千条记录,因此在普通索引的字段上进行查找也就是在内存中多几次“判断下一条记录”的操作,对于CPU来说,这些操作所消耗的时间是可以忽略不计的。所以对一个索引字段进行检索,采用普通索引还是唯一索引在检索效率上基本上没有差别。
