




今日浏览PG社区优化版块,发现有不少人使用explain.depesz.com上传自己的执行计划,以供大家分析。出于好奇自己玩了一下。
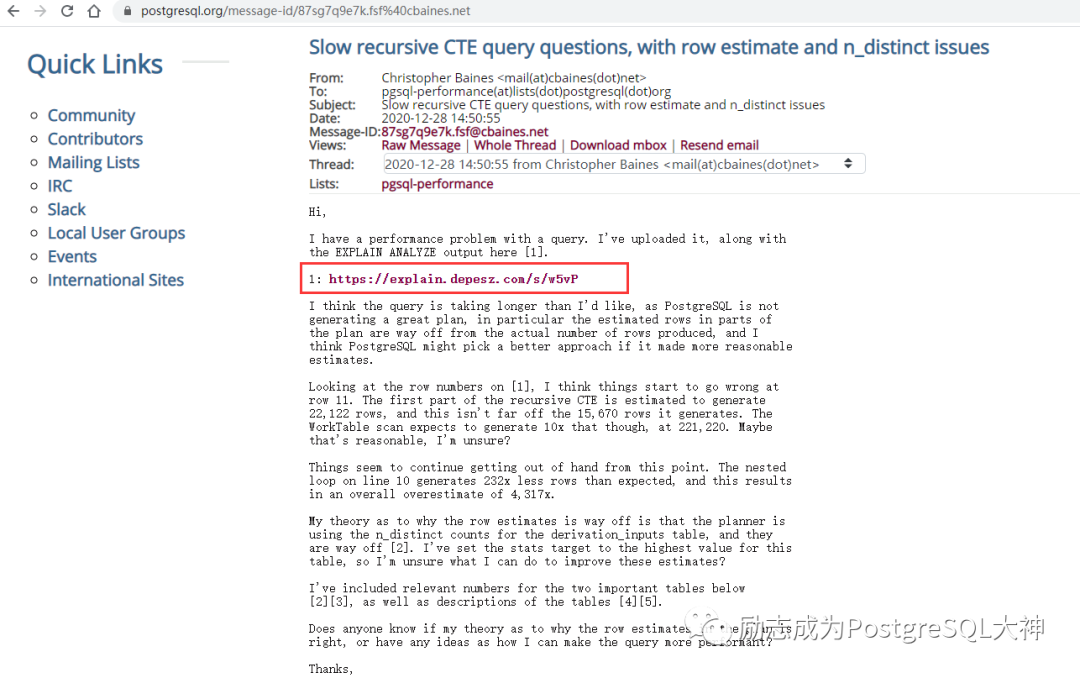
可以看到求助者把执行计划发布到explain.depesz.com
网站上会生成一个地址,通过这个地址我们可以看到它格式化后的执行计划。
example
为了测试一下,我需要在监控上运行最长的 sql。
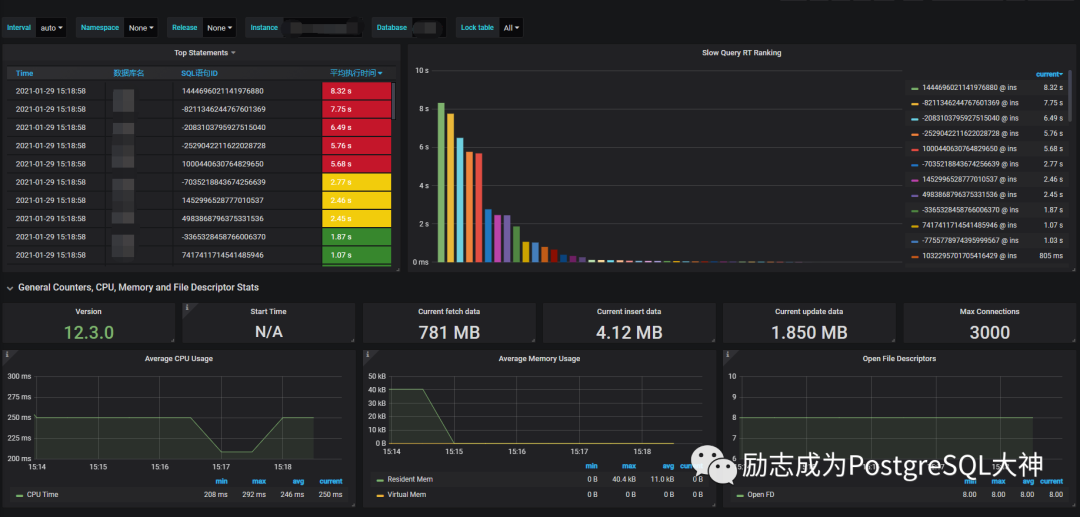
通过pg_stat_statements视图查询 sql语句,发现这条垃圾sql很长。
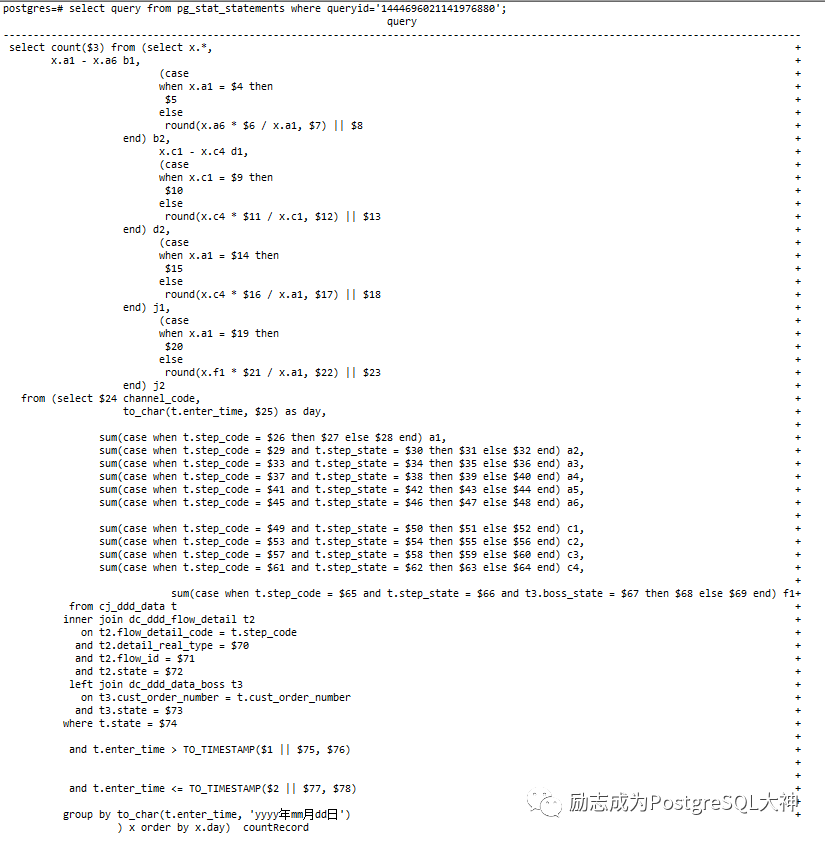
其中许多都会变成绑定变量。在 log中找到相关执行 sql和绑定变量的值。接着用explain analyze运行执行计划。完成运行后,将执行计划张贴在explain.depesz.com
网站上。
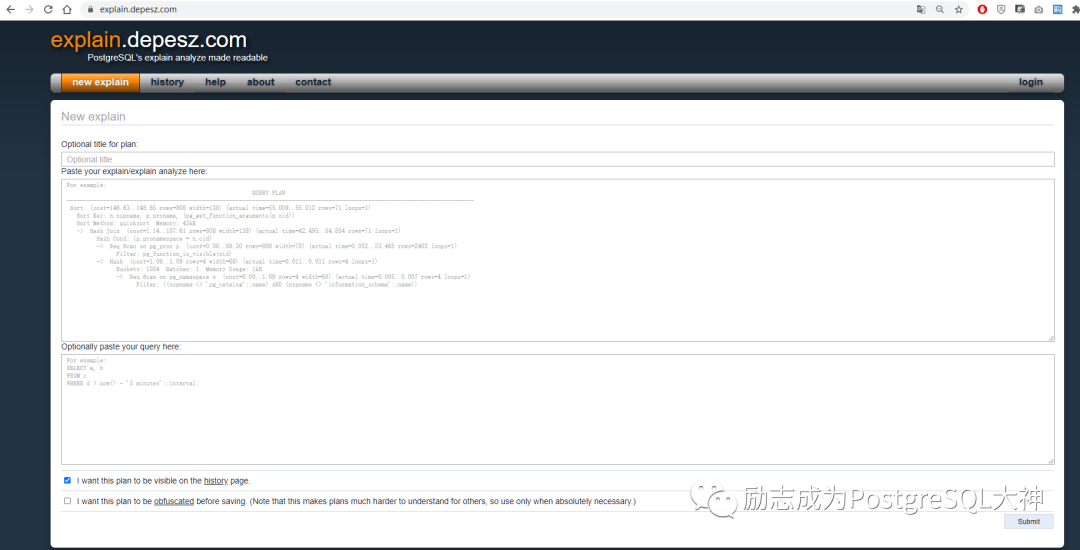
标题随便输入,第二个空栏贴上您的执行计划。接着点提交。

这里展示了SQL的执行计划,那么问题出在哪里呢?注意看exclusive和inclusive。一个是不包含,一个是包含。第八列 exclusive已经被标记为“暗红色”,在此步骤中执行时间特别长,达到4228 ms。
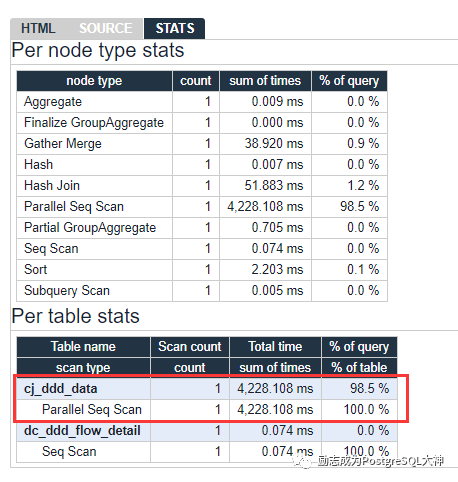
从stats也可以看出,执行时间最长的操作是对cj_ddd_data执行全表并行扫描。耗时4228毫秒。
如何优化,看第8步的谓词条件。
Filter: ((state = 'E'::bpchar) AND (enter_time > to_timestamp('2021-01-25 00:00:00'::text, 'YYYY-MM-DD HH24:MI:SS'::text)) AND (enter_time <= to_timestamp('2021-01-29 23:59:59'::text, 'YYYY-MM-DD HH24:MI:SS'::text)))
Rows Removed by Filter: 3,358,933
此处将enter_time作为时间查询条件,条件是要一个5天的时间(当然可能是1天,也可能是3天),我们check一下是否适合在上面创建索引。
esmp=> select count(1) from cj_ddd_data;
-[ RECORD 1 ]---
count | 11391600
esmp=> select count(1) from cj_ddd_data where enter_time > to_timestamp('2021-01-25 00:00:00'::text, 'YYYY-MM-DD HH24:MI:SS'::text) AND enter_time <= to_timestamp('2021-01-29 23:59:59'::text, 'YYYY-MM-DD HH24:MI:SS'::text);
-[ RECORD 1 ]--
count | 1314753
大概是10%左右数据,可以建一个。建完可以顺便把统计信息收集一下。
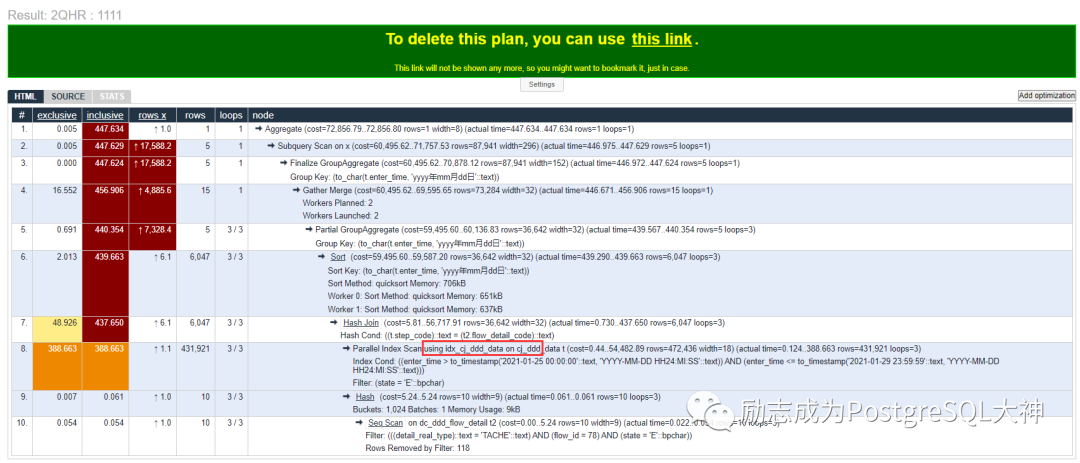
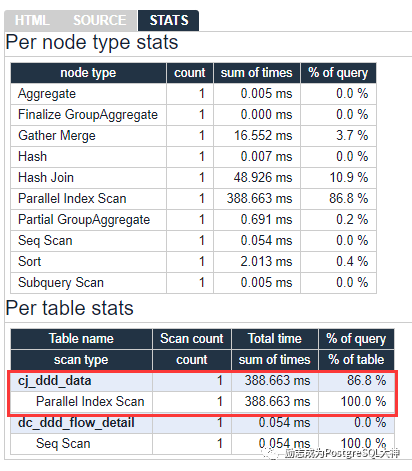
创建完成后再次上传执行计划,此时执行时长447 ms。执行效率提升10倍。
结尾
使用explain.depesz.com格式化执行计划。让优化变得更加简单。有问题还可以在社区上发帖。
文章转载自励志成为PostgreSQL大神,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
