




Oracle、PostgreSQL中char、varchar的区别。
在 Oracle中,char和 varchar2表示字节的数量,而 PostgreSQL会转换成character和character varying,表示字符的数量。对于UTF-8字符集来说,往往一个中文代表一个字符,而一个中文占用3个字节。因此在Oracle中用char (10)只能保存3个汉字,即3个字符,而使用PostgreSQL可以保存10个字符。
下面的图展示了使用AWS Schema Conversion Tool转换的表结构:
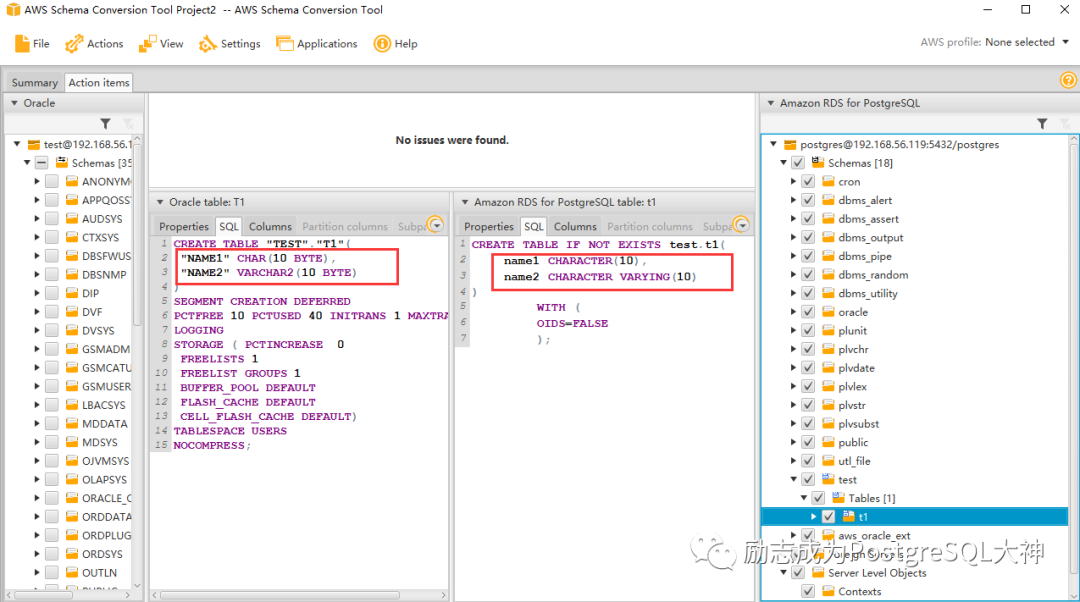
PostgreSQL中character和character varying
在PostgreSQL的t1表中插入测试数据,使用length函数查看字符串中的字符数,同时使用OCTET_LENGTH查询字符串中的字节数。
postgres=# \d test.t1
Table "test.t1"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
name1 | character(10) | | |
name2 | character varying(10) | | |
postgres=# select * from test.t1;
name1 | name2
----------------------+----------------------
我 | 我
我是 | 我是
我是一 | 我是一
我是一个 | 我是一个
我是一个小 | 我是一个小
我是一个小萝 | 我是一个小萝
我是一个小萝莉 | 我是一个小萝莉
我是一个小萝莉是 | 我是一个小萝莉是
我是一个小萝莉是不 | 我是一个小萝莉是不
我是一个小萝莉是不是 | 我是一个小萝莉是不是
(10 rows)
postgres=# SELECT LENGTH(name1),LENGTH(name2) from test.t1;
length | length
--------+--------
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
6 | 6
7 | 7
8 | 8
9 | 9
10 | 10
(10 rows)
postgres=# SELECT OCTET_LENGTH(name1),OCTET_LENGTH(name2) from test.t1;
octet_length | octet_length
--------------+--------------
12 | 3
14 | 6
16 | 9
18 | 12
20 | 15
22 | 18
24 | 21
26 | 24
28 | 27
30 | 30
(10 rows)
显然,在这里可以插入10个汉字,UTF-8默认的一个汉字是3字节,因此在这里插入10个汉字就是30字节。
让我们用orafce的varchar2来试试兼容型。
postgres=# \d test.t2
Table "test.t2"
Column | Type | Collation | Nullable | Default
--------+--------------+-----------+----------+---------
name1 | varchar2(10) | | |
postgres=# insert into test.t2 values('我是一');
INSERT 0 1
postgres=# insert into test.t2 values('我是一个');
2021-02-08 03:19:27.764 UTC [2561] ERROR: input value length is 12; too long for type varchar2(10)
2021-02-08 03:19:27.764 UTC [2561] STATEMENT: insert into test.t2 values('我是一个');
ERROR: input value length is 12; too long for type varchar2(10)
这次和 Oracle一样,在输入第四个汉字时,直接显示出长度不足。
因此,默认使用 AW Schema Conversion Tool或ora2pg工具进行表结构转换,不会有长度方面的问题,只有一个问题,那就char会产生性能影响。把列的宽度设置的小一点,能让底层page里面更好的填充数据,占用的空间更小。
如下面这个案例所示:
postgres=# create table t3 (a INT,b character(10));
CREATE TABLE
postgres=# INSERT INTO t3 SELECT i/10000,'你好吗' FROM generate_series (1,100000) s(i);
INSERT 0 100000
postgres=# create table t4 (a INT,b character(3));
CREATE TABLE
postgres=# INSERT INTO t4 SELECT i/10000,'你好吗' FROM generate_series (1,100000) s(i);
INSERT 0 100000
postgres=# select pg_size_pretty(pg_relation_size('t3'));
pg_size_pretty
----------------
5096 kB
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('t4'));
pg_size_pretty
----------------
4328 kB
(1 row)
设置小一点能节省15%的存储空间,全表扫描也就能更快一些。而varchar是不受影响的。
文章转载自励志成为PostgreSQL大神,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
