




Redis 集群教程
本文是集群的基础介绍(安装、测试、操作),没有介绍复杂难懂的概念。如果你想深入了解集群原理请参考 Redis 集群规范 。
Redis的版本>=3.0
几种常用的集群方案
- 主从集群模式
- 哨兵机制
- 切片集群(分片集群)
主从集群模式
主从集群,主从库之间采用的是读写分离
主从复制原理:
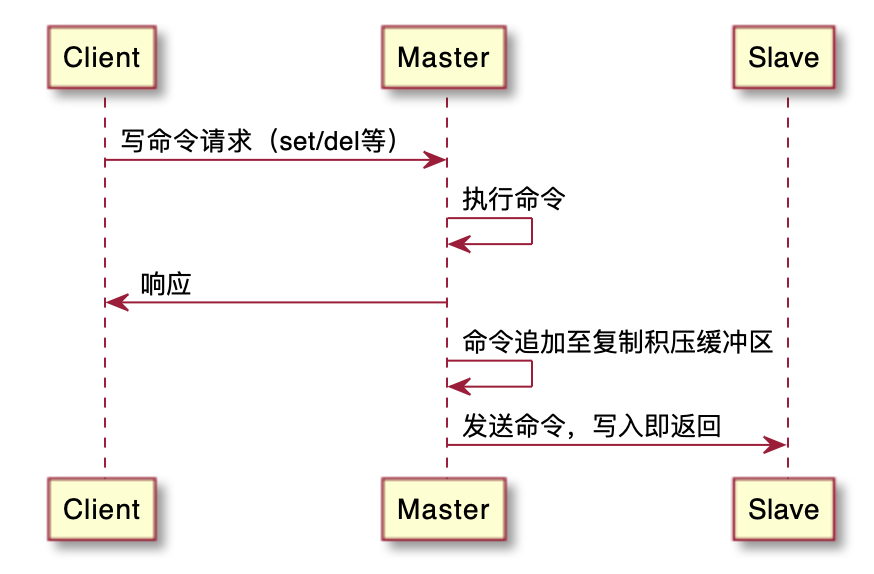
- 主库:所有的写操作都在主库发生,然后主库同步数据到从库,同时也可以进行读操作;
- 从库:只负责读操作;

主库需要复制数据到从库,主从双方的数据库需要保存相同的数据,将这种情况称为”数据库状态一致”
来看下如何同步之前先来了解下几个概念
- 1、服务器的运行ID(run ID):每个 Redis 服务器在运行期间都有自己的
run ID,run ID在服务器启动的时候自动生成。
从服务器会记录主服务器的run ID,这样如果发生断网重连,就能判断新连接上的主服务器是不是上次的那一个,这样来决定是否进行数据部分重传还是完整重新同步。
- 2、复制偏移量 offset:主服务器和从服务器都会维护一个复制偏移量
主服务器每次向从服务器中传递 N 个字节的时候,会将自己的复制偏移量加上 N。
从服务器中收到主服务器的 N 个字节的数据,就会将自己额复制偏移量加上 N。
通过主从服务器的偏移量对比可以很清楚的知道主从服务器的数据是否处于一致。
如果不一致就需要进行增量同步了,具体参加下文的增量同步
全量同步
从服务器首次加入主服务器中发生的是全量同步
如何进行第一次同步?

1、从服务器连接到主服务器,然后发送 psync 到主服务器,因为第一次复制,不知道主库run ID,所以run ID为?;
2、主服务器接收到同步的响应,回复从服务器自己的run ID和复制进行进度 offset;
3、主服务器开始同步所有数据到从库中,同步依赖 RDB 文件,主库会通过 bgsave 命令,生成 RDB 文件,然后将 RDB 文件传送到从库中;
4、从库收到 RDB 文件,清除自己的数据,然后载入 RDB 文件;
5、主库在同步的过程中不会被阻塞,仍然能接收到命令,但是新的命令是不能同步到从库的,所以主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作,然后在 RDB 文件,同步完成之后,再将replication buffer中的命令发送到从库中,这样就保证了从库的数据同步。
增量同步
如果主从服务器之间发生了网络闪断,从从服务将会丢失一部分同步的命令。
在旧版本,Redis 2.8之前,如果发生了网络闪断,就会进行一次全量复制。
在 2.8 版本之后,引入了增量同步的技术,这里主要是用到了 repl_backlog_buffer
Redis 主库接收到写操作的命令,首先会写入replication buffer(主要用于主从数据传输的数据缓冲),同时也会把这些操作命令也写入repl_backlog_buffer这个缓冲区。

这里可能有点疑惑,已经有了replication buffer为什么还多余引入一个repl_backlog_buffer呢?
repl_backlog_buffer一个主库对应一个repl_backlog_buffer,也就是所有从库对应一个repl_backlog_buffer,从库自己记录自己的slave_repl_offset。replication buffer用于主节点与各个从节点间,数据的批量交互。主节点为各个从节点分别创建一个缓冲区,由于各个从节点的处理能力差异,各个缓冲区数据可能不同。
如何主从断开了,当然对应的replication buffer也就没有了。这时候就依赖repl_backlog_buffer进行数据的增量同步了。
repl_backlog_buffer是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
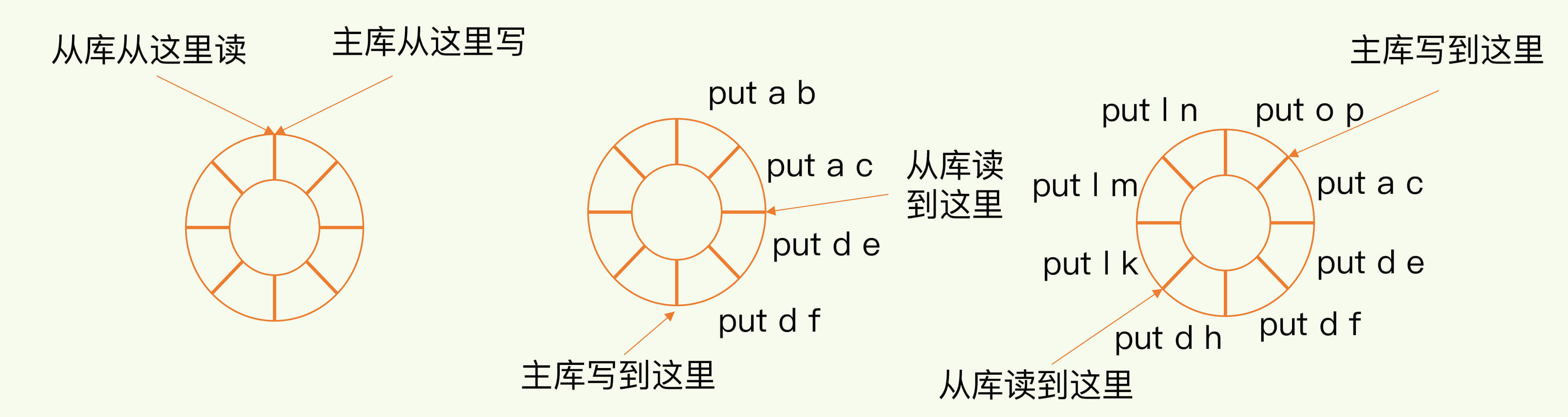
刚开始主服务器的 master_repl_offset 和从服务器 slave_repl_offset 的位置是一样的,在从库因为网络原因断连之后,随着主库写操作的进行,主从偏移量会出现偏移距离。
当从服务器连上主服务器之后,从服务把自己当前的 slave_repl_offset 告诉主服务器,然后主服务器根据自己的 master_repl_offset 计算出和从服务器之间的差距,然后把两者之间相差的命令操作同步给从服务器。
举个栗子
比如这里从服务器1,刚刚由于网络原因断连了一会,然后又恢复了连接,这时候,可能缺失了一段时间的命令同步,repl_backlog_buffer的增量同步机制就登场了。
repl_backlog_buffer会根据主服务器的master_repl_offset和从服务器slave_repl_offset,计算出两者命令之间的差距,之后把差距同步给replication buffer,然后发送到从服务器中。

repl_backlog_buffer中的缓冲空间要设置的大一点,如果从库读的过慢,因为是环形缓冲区,可能出现命令覆盖的情况,如果出现命令被覆盖了,从库的增量同步就无法进行了,这时候会进行一次全量的复制。
缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl_backlog_size = 缓冲空间大小 * 2,这也就是 repl_backlog_size 的最终值。
