




在短暂的“忙于其他事情”(换工作,基因组倍增)之后,我认为是时候再次敲键盘以避免在写作时变得过于“生疏”,同时也避免我的大脑在未来衰老,因为如果你忘记了一些细节,用谷歌搜索你自己过去的文章实际上是很好的,因此,从理论上讲,最终甚至可能是净正“投资”。
我认为做一些“考古学”会很酷,看起来有点超过通常的“verX vs verX+1”比较目标,从v10开始!这肯定很有趣,因为在这段时间里有很多变化——确切地说,大约有2000项“值得发布说明”的东西……令人难以置信!但令人遗憾的是,发布说明和文档总体上对一些性能提升非常粗略(在黑客邮件中,你可以找到一些东西),甚至可能是出于一个很好的原因-肯定有无数不同的用例、配置调整和硬件组合,因此,在很短的时间内,这些笼统的语句可能看起来非常可笑-记住,640KB的RAM应该足够任何人使用。
那么,如何处理性能数据的模糊性呢?没错,正如你可能已经猜到的,是时候卷起袖子,把难以解决的事物放在一起进行一些试验了!因此,请继续阅读我的简单测试设置的一些细节,或者直接跳到底部了解我的一些发现。
请注意,我不想测试任何接近“大数据”的东西,而是“在内存中”,因此,如果您处理大量数据,并主要访问磁盘,那么我猜整个练习可能看起来毫无意义。不过,它应该显示出Postgres如何创建执行计划、索引和完整扫描、解包元组以及进行一些数字处理的可能变化。
测试设置
有些事情在一年内不会改变—我选择的武器是一把瑞士军刀“pgbench”,这把刀可以用来进行一些涉及Postgres的“快速和肮脏/个人使用”风格测试,尽管这一次将一些自定义SQL混合到pot中,作为默认的OLTP风格测试场景有点片面,并且没有说明Postgres也可以成功地用于更多的分析用例(尽管有一定的限制-默认情况下,它不使用列存储或过于激进的压缩)。因此,我添加了一些连接和“海量数据”类型的查询,这在当时对我来说似乎是“常见”的,但并没有给出太多,尽管老实说,因为很难得到一些确定的结果,所以请记住这一点。
测试查询
-- Standard "tcp-b"-like --skip-some-updates
UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2;
SELECT abalance FROM pgbench_accounts WHERE aid = $1;
-- Full scan
SELECT count(*), avg(abalance) FROM pgbench_accounts;
-- Assumes a 4x reduced (aid % 4 = 0) clone of pgbench_accounts
SELECT count(*) FROM pgbench_accounts JOIN pgbench_accounts_reduced USING (aid);
-- Top 5 accounts for each branch - assumes a new index on pgbench_accounts(bid)
SELECT bid, abalance FROM pgbench_branches b JOIN LATERAL (SELECT abalance FROM pgbench_accounts WHERE bid = b.bid ORDER BY abalance DESC LIMIT 5) a ON true;
硬件
5x GCP e2-standard-4虚拟机,配备4个vCPU和16GB RAM,50GB标准永久磁盘(IOPS非常低)
软件
操作系统:Debian 11(Bullseye)
Postgres:v10到v15,最新的次要版本和v15的Beta 2(在编写本文时不再是最新版本)。在给定硬件的情况下,还应用了一些基本的“最佳实践”配置调整(25%RAM shared_buffers,random_page_cost=1.25,max_parallel_workers_per_gather=1)。
工作集大小:每个查询3个大小-适合共享缓冲区,适合RAM,稍微超过RAM,因此对慢速磁盘的一些轻度访问应该会减弱Postgres方面可能的算法磁盘访问改进。
测试运行时间:每个“工作集大小/规模”1小时,查询协议(普通与扩展),查询,PG版本组合
并行级别:我选择了固定的“活动客户端”计数2,以避免CPU最大化并避免一些上下文切换随机性。
测量方法:Postgres内置“pg_stats_statements”扩展统计聚合
此外,这一次,与“旧时代”相比,您可能已经注意到,我决定在云虚拟机上运行测试,而不是真正的硬件……这似乎也在慢慢成为数据库世界的一种常态,或者至少情况正在发生变化。
同样,在选定的数据集大小上-是的,它几乎都是“在内存中”,数据集很小,因此您可能会认为这与现实生活中的用例有点格格不入-但请记住,云存储延迟/随机性要比本地磁盘高得多,因此很难对软件进行实际基准测试。此外,理论上(如果你有足够的资金),你可以很容易地“点击”自己。例如,现在AWS上有多TB的RAM,即使是大数据,也会给你一种非常类似的“大部分在内存中”的感觉。
高级别成果
在按下“回车”键后,我花了8天时间才终于能够兴奋地搓手……但令我恐惧的是,最初的喜悦很快变成了几乎绝望-因为显然有大量数据(900行)需要分析,比我预想的要多得多-组合数学有时肯定会令人惊讶。所以在一个小时的数据挖掘和比较各个行之后,我终于可以制定出我真正想要的,并可以使用窗口函数编写一些分析查询(注:如果你还没有掌握它们,一定要去学习它们——它们是SQL最好的部分之一,说真的)。因此,不用多说,下面是一些比较数字。
请注意,最后,为了简单起见,我实际上决定忽略“中间”的Postgres版本,现在只看v10和v15,因为它似乎太多了,无法很好地总结它……希望在未来解决它,因为这里有完整的数据,所以如果有时间,可以随意查看下面的数字。
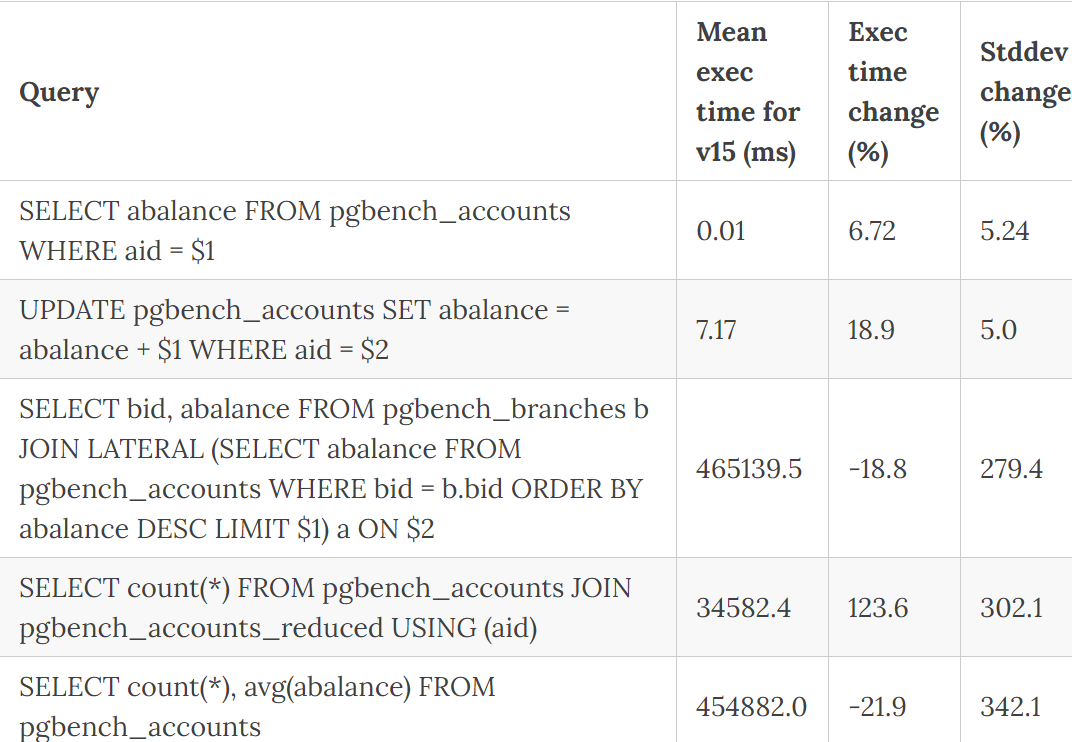
两个异常
pgbench_accounts_reduced上的慢速加入
在查看查询结果时,我注意到的第一件事当然是连接查询的速度下降了123%——我想这一定是我的测试的原因!但在手动重新检查之后-事实上,Postgres v15测试版选择了比v10更糟糕的计划!当然,这些事情时有发生,通常可以解决-但从3个自定义查询中,我选择了已经命中一个…
但不要太担心-基于我10年来每天与Postgres合作的经验,我可以证明这是一件非常罕见的事情,而且它是一个测试版。
顺便说一下,从技术方面-在运行“解释-分析”之后,我看到JIT已经启动,所以我禁用了它,并认为这一定是它…但仍然得到了一个更慢的计划,选择了哈希连接而不是合并连接!虽然它的成本估算比v10合并计划低(顺便说一下,这通常是一种罕见的现象,也是一种“回退”连接类型),但从技术上讲,Postgres做了它必须做的事情。只有在禁用哈希连接之后,我才能看到v15确实快了大约20%,这实际上非常好!
分析查询的标准差恶化
嗯,stddev中有相当大的200%以上的变化……因此,为了以防万一,再次在两个版本上运行查询:
select count(*), avg(abalance) from pgbench_accounts
Hhmm两个版本都有完全相同的“并行序列扫描”计划,因为这是一个非常简单的查询-而且奇怪的是,v15总是更快…但不知何故更加跳跃。我没有想到什么明显的东西-也许是“云”/“噪音邻居”效应?
SELECT count(*) FROM pgbench_accounts JOIN pgbench_accounts_reduced USING (aid)
这里更容易理解,因为在前面的“慢速连接”段落中解释了相同的查询-JIT不必要地启动+选择了稍微慢一点的计划。
SELECT bid, abalance FROM pgbench_branches b JOIN LATERAL (SELECT abalance FROM pgbench_accounts WHERE bid = b.bid ORDER BY abalance DESC LIMIT $1) a ON
同样,JIT似乎启动得太早了……但一旦在v15上禁用,它就正常化了,在运行时实际领先v10 40%!
试图得出结论
好了,好了,现在来看看最难的部分-那么我从这个练习中学到了什么,如果有的话?一些想法:
-
请记住,我测试了一个V15beta2版本(遗憾的是,beta3在我开始测试后不久就发布了)
-
在从测试结果中排除具有上述详细规划异常的查询后,所有查询和规模的加速率仅为4%。不多对令人惊讶的不-事实上,这非常符合逻辑,因为PostgreSQL在我使用它的整个十年中一直坚如磐石,并且(大部分)优化得很好!此外,它是一个非常静态的、主要是只读的、几乎是“内存中”的测试设置,其中许多最近的主要优化(索引重复数据消除、自下而上的索引清理等)无法显现。
-
Postgres planner并不是最复杂的,它仍然可能会误判事物,因此,与以往一样,重要的是了解你的方法,解释计划、计划常数和某些结构(如横向结构),这些结构将Postgres推向你喜欢的计划。
-
查询协议(普通SQL与准备好的语句)对于更小/更快的查询仍然发挥着巨大的作用-仅通过使用准备好的声明,两个非分析性简单索引访问查询就获得了20%和50%的提升!当然,这里没有什么新鲜事,只是重复一下:)
-
对于这种相对较短的运行测试来说,云虚拟机似乎不太值得信赖-不同5台主机上所有查询/规模的统计变异系数(~7%)实际上高于测得的Postgres 4%的加速率(不包括离群查询)…因此,下一次我仍然会再次启动一些真正的硬件。
-
总而言之,一个非常不错的性能从良好的旧v10,这实际上将在几个月内下线!因此,那些仍然在安全网络中运行的人(没有安全更新,记住!)而且不想让停机时间升级,至少不必太担心性能部分。
-
请记住,测试性能很难,而且有很多事情我没有测试-分区、严重并发/多用户访问、由于膨胀导致的长期性能下降。因此,我想象出来的自定义SQL查询现在对我来说似乎相当片面(更多的是在分析方面),所以可能把它当作“某物”。
顺便说一下,如果您想尝试类似的东西,可以在这里找到我使用的脚本。此外,您只需单独创建一个可从测试虚拟机访问的Postgres“结果数据库”,即可将结果推送到单个表中,以便通过SQL进行分析。此外,如果您在我的逻辑中看到一些明显的错误或有其他想法,在评论部分获得ping将是非常好的。
这次就这样!希望在v15最终版发布时,能带着类似的作品回来-同时好好照顾你的数据库和其他宠物。
PS:特别感谢我的雇主Cognite对我的博客很友好,让我可以在一周内烧掉这些CPU!顺便说一句,我们还招聘了一些不同引擎上的数据库工程师职位,所以如果你不介意我作为同事,为什么不去看看呢。
原文标题:5 years in PostgreSQL major versions performance - anything surprising?
原文作者:Kaarel Moppel
原文链接:https://kmoppel.github.io/2022-09-05-5-years-in-postgresql-major-versions-performance-anything-surprising/
