本文将分享两则PostgreSQL故障案例。
案例一:数据目录重组
这一则案例在2021年12月PGConf亚洲大会做过远程直播分享,现在重新整理一下。
案例介绍
发生故障的原因是人为误操作删除了整个数据目录
rm -rf $PGDATA
据客户反馈,因为当时PGDATA目录下有一些异常文件,觉得可能是病毒文件,因此把整个目录直接删除了,并且过了一段时间之后才发现这个问题。
故障处理
没有备份,经过磁盘扫描工具恢复出部分碎片文件如下:
1.恢复环境准备
运行的操作系统是centos7.6,数据库版本是11,我们首先初始化一个干净的实例,用于后面系统文件的恢复。

2.重组数据目录结构
PostgreSQL数据目录的物理结构如下:
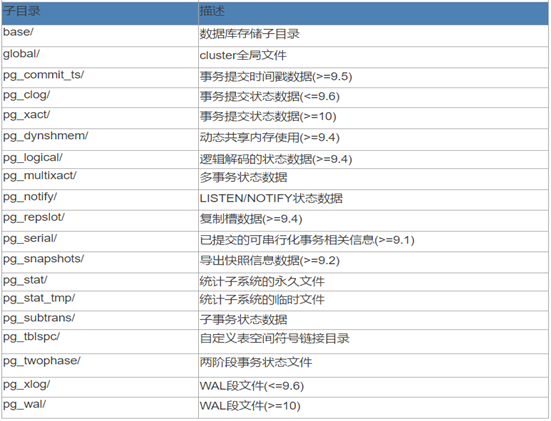
当前恢复的版本是11,我们根据已知的物理结构信息对相应的数据文件碎片重组到对应的子目录中,并且对缺失的目录进行初始化创建。
mkdir pg_notify
mkdir pg_tblspc
mkdir pg_replslot
mkdir pg_stat
mkdir pg_twophase
mkdir pg_snapshots
然后参考上面初始化干净的实例进行权限修复。
接下来我们打开数据库日志后,进行服务启动,观察错误再进行修复。
3.修复事务状态文件
首先第一个数据库启动错误是pg_xact目录下3号文件发生丢失,日志信息如下:

- pg_xact下的文件名为0000,0001等,文件的最大尺寸为256KB。
- 当PostgreSQL关机或执行存档过程时,数据会写入至pg_xact目录下的文件中。
- 当PostgreSQL启动时会加载存储在pg_xact中的文件,用于事务提交日志状态的初始化。
发生故障时,业务数据提交的事务状态文件发生了丢失,我们只能模拟填充内容为0,也就是事务的初始状态。
dd if=/dev/zero of=pg_xact/0003 bs=256k count=1
通过上面的模拟填充之后,数据库正常启动如下:

4.修复系统元数据映射文件
当使用psql连接业务库时,发现如下错误:

pg_filenode.map文件是每个数据库很重要的一个文件,普通数据库对象及它们的分支数据文件是通过oid与filenode来进行关联,我们可以从pg_class的oid与relfilenode字段看到关联信息。系统元数据对象信息是通过pg_filenode.map文件进行管理。它的大小为512字节,最多可以存放62条系统对象记录。当这个文件发生缺失时,我们可以拷贝相同版本的其它数据库下的文件进行替换。当然如果对系统表做过清理之类的操作,这么做可能会失败,那就需要使用pg_filedump来进行处理了。
本文直接拷贝管理库postgres下的pg_filenode.map文件即可。
5.跳过系统索引
接下来连接业务库时又遇到下面这个错误:

查看是哪个对象的数据块发生损坏:

可以看到是一个系统表的索引发生损坏,那我们可以使用开发选项参数ignore_system_indexes on/off进行切换。
6.修复库级/角色级配置文件
在PostgreSQL里参数配置有如下几种方式:
- postgresql.conf(global)
- postgresql.auto.conf(alter system)
- command line options(-o options)
- all role(all role APPLICABLE)
- database(per-database APPLICABLE)
- role(per-role APPLICABLE)
- session(per session with set APPLICABLE)
- transaction(per function with set local)
本文存在库级/角色级的参数配置,保存在pg_db_role_setting元数据中,所以遇到了下面的错误:
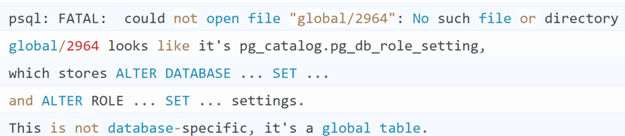
我们可以使用干净实例下的pg_db_role_setting文件进行拷贝,虽然丢失了参数配置信息,但不会影响数据恢复。
7.数据恢复
由于系统索引也存在缺失,通过系统的关联查询会报错:

不过好消息是可以直接对pg_stat_user_tables查询获取的表进行copy备份,所以我们可以利用如下语句拼凑copy语句:
select '\copy' ||relname||' to 'relname||'.dat' from pg_stat_user_tables;
然后通过copy恢复出来数据。
案例二:大字段损坏恢复
案例介绍
通过查看组件运行状态发现postgresql服务状态为down
...
run: nginx: (pid 710) 533s; run: log: (pid 8130) 533s;
down: postgresql: 0s; normally up,want up; run: log: (pid 497) 554s;
...
故障处理
数据库部署再容器环境下,拷贝容器里的数据目录到本地,进行问题分析及处理。
1.恢复环境准备
运行的操作系统是centos7.6,数据库版本是9.6,我们先准备好9.6的bin环境。
2.数据库启动错误一处理
使用pg_ctl工具启动数据目录,提示如下错误
LOG: SSL is not supported by this build
FATAL: configuration file "/home/postgres/pg96/data/postgresql.conf" contains errors
数据目录配置参数启用了SSL,而本地的服务器环境编译时没有打开SSL,因此引起上面的报错,可以先关闭SSL,编辑配置文件postgresql.conf文件,设置ssl=off之后,这个问题消失。
3.数据库启动错误二处理
启动过程,提示第二个错误如下
FATAL: could not create lock file "/xxx/xxx/.s.PGSQL.5432.lock": No such file or directory
数据库监听创建socket的目录不存在,因为容器里修改了默认的unix_socket_directories目录,我们修改unix_socket_directories=’/tmp’之后, 这个问题也消失。
4.数据库启动错误三处理
启动过程,提示第三个错误如下
FATAL: could not access status of transaction 1225386
DETAIL: Could not read from file "pg_clog/0001" at offset 40960: Success.
这个问题与第一个案例里修复事务状态文件类似,在版本10之后pg_clog目录重命名为pg_xact。
使用dd模拟填充0,也就是事务的初始状态。
dd if=/dev/zero of=pg_clog/0001 bs=256k count=1
通过上面的模拟填充之后,还有多事务状态文件夹pg_multixact下的两个文件也需要做类似处理,这里不再赘述。
到此为止,数据库可以正常启动如下:

5.数据库连接错误处理
使用psq连接时提示错误如下
psql: FATAL: Peer authentication failed for user "xxx"
查看pg_hba.conf,发现数据库使用如下配置条目
local all all peer map=xxx
由于是在容器里,只进行内部访问,所以仅允许使用基于操作系统的peer方式进行免密认证。
那我们先修改为trust
local all all trust
然后reload之后重新进行连接
pg_ctl reload -D $PGDATA
6.排除错误表备份
数据库连接成功之后,发现主要的数据都在一个业务数据库上。
我们尝试用pg_dump对该库进行逻辑备份,使用命令如下
pg_dump -U user database -Fp -f data.sql
备份过程中有两个数据表对象提示如下的错误:
ERROR: missing chunk number 0 for toast value xxxxxx in pg_toast_xxxxxx
那我们先排除这两个有问题的表,对其它的数据表先备份导出,使用如下命令
pg_dump -U user database -Fp \
-T "tab1" \
-T "tab2" \
-f data.sql
7.问题表处理
两个问题表都是有部分行的toast字段数据损坏,所以我们需要先定位错误的行号,然后排除错误行进行数据恢复。
首先查询问题表的记录总数
select count(*) from tab1;
select count(*) from tab2;
问题表的记录总数可以正常查询,只要查询不涉及toast字段发生损坏的数据行,都不会出现错误。
可以使用shell脚本进行处理:
#!/bin/bash
j=表的记录总数
for ((i=1; i<=j;i++))
do
psql -U user database -c "select * from tab1 order by xxx LIMIT 1 offset $i" >/dev/null || echo $i
done
shell脚本每次使用psql建立连接的方式进行处理效率较低,更推荐的方式是使用数据库存储过程进行处理。
如此定位出所有的错误行之后,再使用copy + 子查询的方式可备份出数据,这里不再详述。
结论
这两则案例发生故障都是单机没有备份,所以备份还是很重要,这是第一点。
第二点相同之处是故障发生时,事务状态文件都会损坏,修复事务状态文件是启动数据库的关键。
保持联系
从2019年12月开始写第一篇文章,分享的初心一直在坚持,本人现在组建了一个PG乐知乐享交流群,欢迎关注我文章的小伙伴进群吹牛唠嗑,交流技术,互赞文章。

如果群二维码失效可以加我微信。