




Rust China Conf 为中国本土范围的Rust技术大会,致力于成为中国 Rustaceans 交流的盛宴,为国内的 Rust 开发者和企业提供一次充分的成果展示、技术分享、能力提升、行业资讯交流、企业人才储备建设的机会。
蚂蚁集团开发工程师夏锐航作为分享嘉宾出席大会,为大家分享CrersDB中的一种并发模型实践,以下是发言实录:

“
大家好!接下来为大家带来这次的分享,Rust在CeresDB中的一种并发模型实践。
首先介绍一下我自己,我叫锐航,是蚂蚁集团的开发工程师,这是我的GitHub ID @waynexia。
今天的分享会分为三个部分,首先介绍我们的产品CeresDB,然后是我们在实践中的并发模型实践,最后是我们的社区和团队的介绍。

先通过两个例子来了解一下我们所处理的面对的场景,这边找了两个图,一张是Wiki上找的股票K线图,另外一个是Grafana的大盘截图,大家可能对这两个图都比较熟悉,它们有一个很明显的共同点就是这两张图都带有很强的时间戳属性,就是这两张图的横轴。
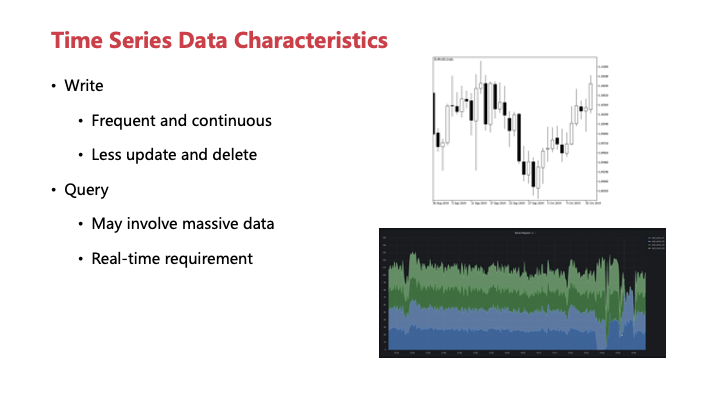
其实不只是这里列出来的两张,我们接触到的大部分数据其实都显示或者隐示了包含的时间戳这一列,这些数据的产生通常是随时间进行,但它就是非常频繁而且持续的。并且很少有更新或者删除,所以有的时候时间戳这一列被隐去,所以我们的追加被表现成了更新。
这些数据在查询的时候,通常可以分为两种情况,一个是涉及到大量数据计算聚合的,可能是由于长时间分析,一个长时间跨度,或者是大量组件,涉及到数据所产生的请求。另外一个是对最新数据的频繁读取,比如获取最新的大盘走势,或者是机器所谓告警等等。
这两个场景,一个是对数据计算性能有非常重的依赖,另外一个是对数据实时性有很高的要求,我们传统的分析型数据库可能对高频写入或者是数据实时性支持得不是很好,而专注于时序领域的产品,可能又无法去很高效地处理大量数据的计算。

那我们构建了CeresDB希望能解决这个问题,左边这个是我们项目的介绍,我们希望将CeresDB打造成一个能同时处理两种负载的数据库。除去这个最主要的特征,我们还希望CeresDB能够有更丰富的特性,比如能够根据数据特征自动地调整一些性能参数,减少使用的负担。另外,支持完整的SQL查询,同时也能够在此基础之上积极拥抱社区生态,去很好地支持不同领域一个细分的查询语言,比如说Metric控领域流行的Prometheus PromQL等等。未来也希望能够和更多的产品产生紧密的联系。最后,作为我们在内部生产上使用的系统,可靠性和水平拓展能力也是非常重要的一环。
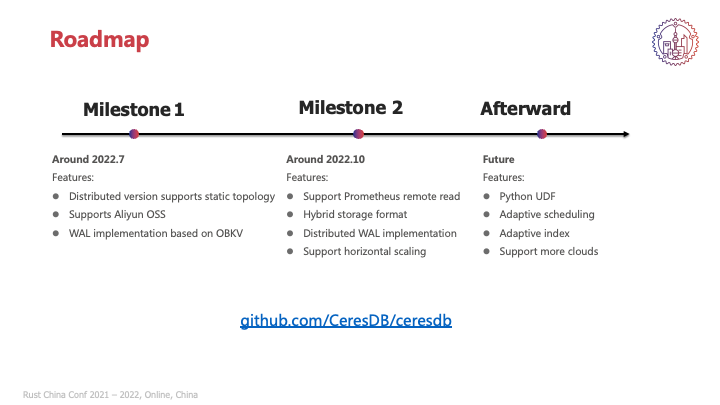
下面介绍一下我们的Roadmap,目前有两个里程碑,第一个里程碑是最近的release,这是我们第一次的release,提供了基础的集群部署能力。我们计划在今年10月达到第二个里程碑,支持比如刚才所说的PromQL的查询能力,目前正在进行POC的混合存储格式,也希望能够完成开发,同时提供更多的WAL生态选项,目前我们在第一个release中提供的是基于OceanBase的OBKV所实行的WAL。并且希望能在目前静态路由的集群模式下提供更进一步的水平拓展能力,支持完备的集群模式。
除此之外,在未来我们还希望能够提供基于Python的复杂UDF能力,支持大数据生态。同时能够有更灵活的自适应调度和索引能力,来适应更复杂的查询场景。并且能够对接更多的云厂商,在更多的云上进行部署。
我们CeresDB希望参与一个开放的社区,所以大家如果有想要的feature也欢迎一起来讨论,有任何问题也可以在仓库提,这是我们仓库的地址:github.com/CeresDB/ceresdb。
介绍一下我们在生产中的实践。这个一种并发模型,其实就是从Thread Per Core模型中衍生出来的一种方法,去掉了Thread Per Core中与物理核心绑定的属性,这叫在单个工作线程下的编码模式。
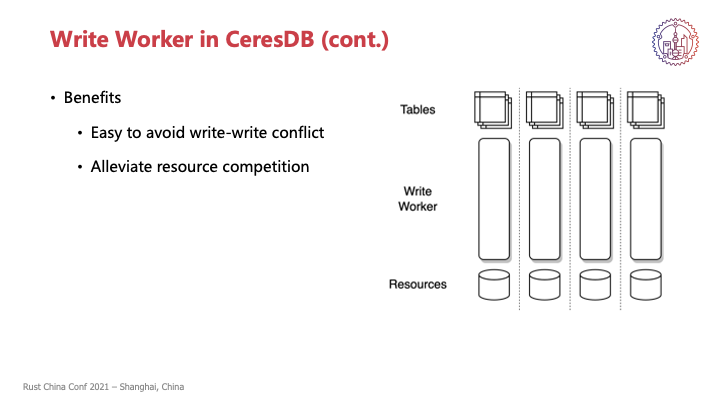
首先看一下CeresDB中的一个例子,我们有一个Write Worker是CeresDB中一个负责处理写请求的组件,上层的请求转化为写请求之后交给Worker执行,比如说插入数据或者更改表结构等等。同时也有一些后台处罚的工作,比如说压实或者刷写,就是后台的数据归档。
我们以表为单位,将每张表分配到一个Write Worker,一个Write Worker上可能会负责多个表,是一个一对多的关系。这张表的所有写操作都由这个Worker来完成,默认是按照核数来初始化我们的Worker的,每个Worker之间的负载和资源都是独立的,包括Worker本身也会独占一个线程。以及Worker所负责到的那些表所涉及到的资源,在逻辑上也是不共享的。
具体来说,具体到我们的场景来说就是每张表可能下面会有文件、WAL,这些在资源在逻辑上是独立的。
通过这样的操作,我们能够得到两个明显的好处,首先是对于每张表来说,前后台的写入操作它是串行化的,所以做一些简单的逻辑就能够避免写写冲突的问题,能够简化我们逻辑状态管理的代码。同时Worker将表,就是工作负载,以及表后所隐藏的资源都是独占的,可以去减少资源竞争的情况。
当然这个完全串行化是一个比较简单的场景,实际上还会有一些复杂的逻辑,比如说一些不关心写入顺序的操作,我们就会把它Detach到后台来执行,忽略它与其他操作之间的写入顺序等等。
刚刚所说在目前我们大多数情况底下,虽然在逻辑上做了区分,我们底下还是同一个物理资源,比如说同一块磁盘、同一块网卡之类的。我们在逻辑上独占,独占的可能是一个文件集比或者是一个SQL的链接,通过这个抽象能够减少上层资源互斥的逻辑,并且在物理资源拓展的时候能够很方便的Scale out,比如说简单的加磁盘、加网卡,因为已经做了逻辑资源的隔离,所以能够比较方便地去进行拓展。

这是在CeresDB中的一个场景,作为一个通用的手段来说,我简单总结了几点能够带来的好处。首先在这种模式下,所有的状态管理只会在一个线程内被访问,在编码的时候可以简化这个状态管理的逻辑。我们资源也是一样,各个资源在逻辑层面独立,能够减少资源竞争的情况。
然后也充分利用了Rust的协程特性,其实就是async-await的异步编程,减少线程的上下文切换,就可能之前是我们有若干个线程,这个线程数量是大于核数的,那么操作系统就会把我们的线程去进行一个调度,调度到不同的核上来执行。我们现在如果把所有的任务都已经预先分配到线程里面,就可以将线程的切换简化为一个协程的切换。
同时如果我们能够再进一步将这些工作线程与核心绑定起来,形成一个Thread Per Core的模式,还可以进一步提高CPU的亲和性等等,以及Cache的有效性。在后面还会提到一些小的地方。
需要注意,这里所提到的各种东西都是有适用场景,关于这种方式所具体的优势和局限性,最后在后面进行详细讨论。
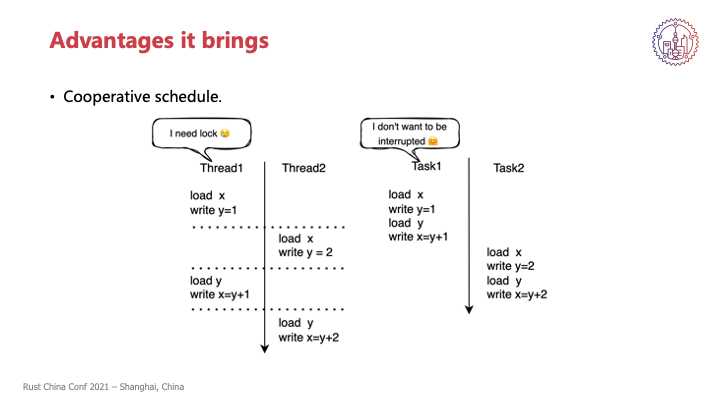
我们接下来先介绍一下它能带来的几点优势,首先是我们的一个调度模型,从之前刚刚说的由操作系统完成的抢占式调度,变为了各个协程之间进行的一个协作式调度。
我们可以来对比一下,左边是一个抢占式调度的一种常见的情况,那写出这种代码,其实就是我们把若干个任务同时放进一个线程持续执行,可能这些任务之间是会涉及到同一个状态、同一个逻辑资源,那其实这些任务是互斥的。
比如说这里有两个线程同时在执行两个任务,而这两个任务都是涉及到同一个资源,就是这里x和y一个抽象。它们可能会被调度到一个核上来执行,在这里可能先执行第一个线程,执行了两句,然后操作系统把第二个线程调度到这个核上,把第一个线程调度走,第二个线程就执行了两句,这样交替执行。从一个线程来说,它感知到自己是一直在执行的,那么它写完y=1然后去读y的时候,它可能会发现自己y怎么变了。所以在这种模式下其实是需要一个数据同步的,可能是锁或者原始变量之类的手段,来保护好自己的状态和变更。
如果在右边,这两个任务,我们会把它分配到同一个线程内,就是说涉及到同一个资源的,我们会按一个线程去分配它。那它如果运行在同一个线程,就算这个线程本身被操作系统调度走,对任务来看,它其实是一直运行的,因为整个线程被调度走,那也没有别的任务能够同时来执行。这时候我们调度权实际上虽然操作系统还是能够对我们线程进行调度,那我们逻辑上的调度权实际上就是由任务本身或者任务之间来进行一个协作式调度。
比如说这里如果我的Task1它不想被调度走,那它可以选择不交出自己的执行权,它把自己四句话全部执行完,然后再由Task2来执行,这样就能够有一个定式的执行模式,Task1就能够确定自己在写y和读y之间,这个y是不会发生变化的。这样就能够减少简化我们的状态管理,就不需要去锁上一个临界区来确认这个时候某个变量只会由我来独占访问之类的,因为它已经在我们模型层面已经保障。

在这个模型下,更进一步可以想到我们其实不再需要原子操作了,或者换句话说来说,我们所有操作都是原子的,可以不受限于硬件的限制,对任意多的数据进行原子操作,因为只要我们不交出执行权,那我们这个操作就可以一直在进行。
这一点带来最直观的变化就是我们工具结构的变化,比如说常用的Arc可能就变成Rc,一个原子类Atomic Reference Count 变成一个 primitive reference count(RC) 就是我们可以不需要原子操作。同时我们有一个大量运用了原子操作的,就是lock free的这种结构,我们也不需要掉头发去写这种东西了,我们可能就用普通的单线程结构就能够完成,还使我们能够保证这个结构、这个状态能够在同一时刻不会有其他人来访问。
不过也不是说完全能够去掉lock free的结构或者是lock,毕竟我们状态之间、任务之间还是需要进行状态同步的,完全抹掉所有的共享状态是非常困难的,我们通常是在CeresDB中选择系统的一部分来实现这个模型,是一个工程上的取舍。

除去不需要原子操作,上面提到的Arc到Rc的变化就是Rc,或者是没有Atomic的东西,它就有一个特征,就是没有Send这个auto trait,可以看到在标准库里面是显示的给Rc实现了一个Send,Send就是一个Negative的implement。
在接下来讲之前,我们先回忆一下Send是什么,Rust中关于Send的定义,简单来说就是用来表示一个结构,用来描述一个结构能否安全地被多个线程所持有。这个trait非常常见,肯定大部分都见到,或者我们自己定义自己的trail的时候,也给它加上了Send,加上async,或者加上static这种,先加上再说的这些Out-trail,以及我们又遇事不决,用Arc Mutexß来堵住编译器关于生命周期、Send之类的报错的做法。
而且目前很多的基础设施都是在Send这一条件被满足的情况下来实现的,比如可能我们看看自己的代码,可能大部分都要求了Send,或者是像pub fn spawn这个方法也是对spawn进行了future以及future的结果,也要求了一个Send。
但是在我们现在所讨论的这个模型中,可能Send就不是那么常见了,因为我们大部分的工作都是在一个线程中完成,没有这样一个结构或者是一个任务发送到多个线程的需求,自然就不需要Send这个约束,因为我们在一开始就不会在多个线程中共享它们。
那么少了这个约束之后,不仅是常用的工具类可能会发生变化,还有他们背后所隐含的编程习惯可能也会不同。

最后一点就是我们可见性的获取,我们的overhead会减少。比如之前可能常见的是用Mutex 或者 RwLock,这个时候可能是要去处理多个资源在同时访问的情况。在这里我们已经从结构上能够保证我们只需要去获得语义上的一个内部可变性就行了,我们理论上是可以把所有额外的运行时检查都去掉,同时还能够保证代码的安全。
另外就是我们所有的工作负载都在一个Work thread中完成,那这个Work thread就包含工作负载所有的上下文,能够很方便地去基于这一点来实现资源调度和资源控制等等。
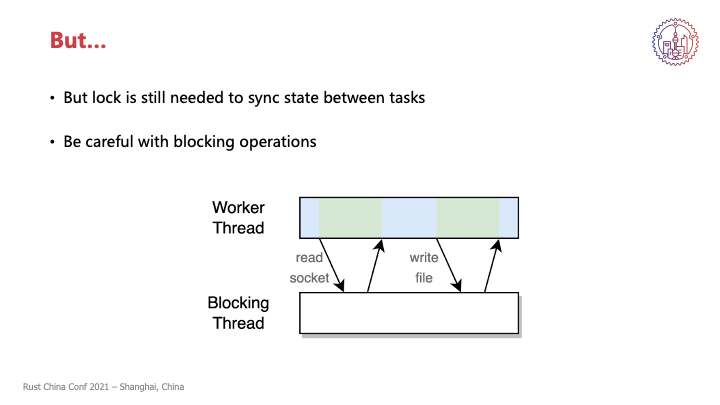
好处讲了这么多,最后还有一个but,就是虽然同时只会有一个任务在进行,不存在并发状态的修改,但是我们还是不能够完全丢掉锁,因为在不同的任务之间同步状态还是需要。即便任务之间是协作式调度,为了性能我们可能还是会选择将任务进行穿插进行,比如说可能这个任务它在等IO,那这时候可以先交出所有权,它去后台等IO,让别的任务的计算先开始。这个时候我们可能有些操作执行到了一半,为了性能方便就要交出所有权,是要通过类似锁,还是要锁的机制来告诉别的任务,这个资源现在不能够被进行修改。
不过同样是锁,单线程下的锁会稍微简单一些,不需要条件变量这种手段就可以实现,比如说最朴素的就是自旋锁,或者是更高性能的话,就可以和Runtime相结合来干涉Runtime调度来实现。
另外一点就是这个工作线程中不能够有任何的Blocking行为,这个虽然在平常的异步中也是需要注意的一点,但是同样是发生Blocking操作,我们这里只有一个线程,如果把这个线程Block住了,带来的后果是会比平常更麻烦一些,其他线程锁只有一个任务,其他的任务会被调度到别的线程上去执行。但是在这里,我们把这个线程锁住之后,这个线程关联的所有任务可能都无法进行。所以同样是一个注意事项,但是在我们这个场景下可能会造成更严重的后果。
那是不是这种情况下就完全不能进行阻塞式的IO了呢?
我们如果是纯异步的IO理论上是没有问题的,是可以任意执行的。那如果不是,一个常见的办法就是开一个或者多个线程来专门执行这些Blocking的操作,主线程把这些操作移交出去,来保证自己本身仍然是异步的,因为我们可能有些系统还是因为特殊的原因无法使用异步的IO,只能使用阻塞式的IO,那这种时候这个手段可能就会是必要的。

好处讲了这么多,代价是什么呢?
这里列了两点我认为比较重要的代价,一个是传染性,另外一个是做强制分片的需求。首先说传染性,这里指的是Send这个trait的传染性,我刚刚所说整个系统变为单线程的模型改动会比较大,但是如果只改一部分的话也会有问题。
我们先来回忆一下Rust中是怎么处理auto trait的,这里就以Send为例,如果一个结构所有的field都是Send的,编译器就会自动给这个结构也推导成Send。反过来如果这个结构中有一个或者是多个field,它是Unsend的,就它没有实现Send,那编译器就会把这个Unsend推导到这个结构上。如果一个结构中任何一个地方是Unsend,那这个结构就会被推导为Unsend,这个结构也可以是Rust自动生成的future,通过async语法来生成的future,它本身也是一个匿名的结构体。
如果是这样,Unsend可能就会随着这种函数调用扩散到整个系统。但这显然是不可接受的,因为这就强制要求我们把整个系统改造成够接纳Unsend。这种时候为了防止把Unsend扩散得到处都是,我们可以让两部分通过channel来交流,把之前的显示函数调用包装成一个个task或者是request,就类似于模拟Rpc的感觉,通过这种方法来构建一个Unsend Boundary,把两部分分离开,从而避免这个问题。
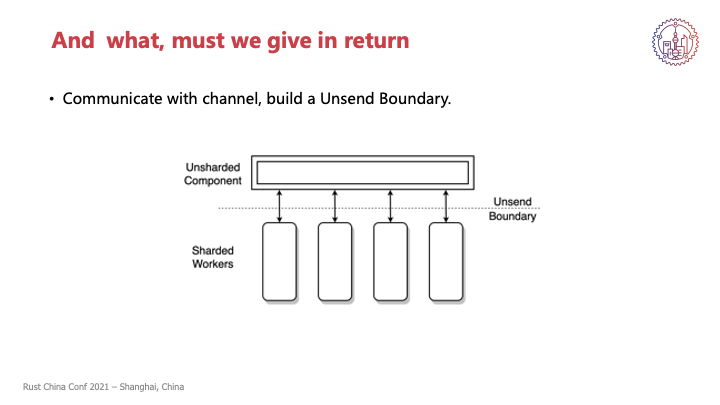
我们CeresDB中的Write,就刚才说的Write,也是通过上层所封装好的Write request来执行操作,上层是把自己所收到的写请求包装成一个request,然后通过channel发送给底下对应的Worker,然后这个Worker执行完再把结果发送回去,这样就避免了一个显示函数的调用,也就避免了这个类型扩散到其他的部分,而是只把它局限在我们的Worker中。
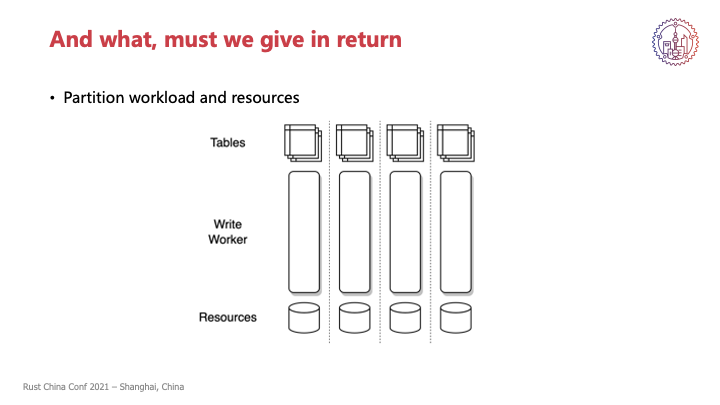
另外一个问题就是强制分区,因为我们希望各个线程之间尽量减少交流来减少我们的额外开销,所以能够最好就是预先将工作负载和资源都进行划分,比如CeresDB是按照表来进行partition,可能别的系统还按照ID或 Key range之类的。对一些系统来说可能分区是比较简单的,但是对于另外一部分系统,它可能就比较难以找到一个合适的分区方式,那我们这种单线程的编程模型或者是Threadpoolctl不太适合。
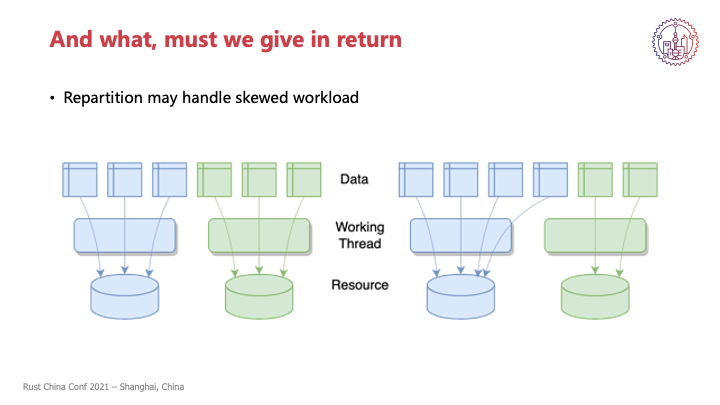
我们分区也要注意粒度的问题,最好能够保证每个分区之间不会相差太多,或者是每个分区元素的力度也不会相差太大,因为我们涉及到分区的系统,通常都会遇到分区负载不均的情况,所以我们为了能够灵活地调度,根据负荷来动态地调整partition,所以就要求每个分区的单元不会太大。
另外,还要求本身能够执行这个Repartition,这个其实大部分是工程上的问题,对于线程本身来说,它所代表的是一个计算资源,它是无状态的,所以可以很方便地进行划分,很方便地把比如说这条指令,在这个线程或者这个核上执行,把它调度到另外一个线程或者另外一个核上执行,这个是比较方便的。
但是我们任务通常背后还对应了我们的状态和资源,我们状态和资源其实相对于我们的工作负载,其实是更难以调度的,特别是如果我们的状态是涉及到持久化的,比如说我们会把什么东西写到磁盘上,那我们这个下在这个磁盘,另外一个partition在另外一个磁盘,这个时候可能会要有一个比较复杂的逻辑。同时上层的分组路由也要保证路由的正确性。
那么假如我们的场景也很适合,想体验一下这种编码模型,或者是享受一下它带来的性能提升,那要怎么样开始开发呢?因为我们这个是要求一个纯异步的编程,那就离不开async-await。
先来看一下最重要的Runtime,目前一些常用的Runtime都有提供不要求Send的接口,比如说tokio和futures,都有spawn local的方法,可以看到和刚刚的spawn的区别就是我们这里函数签名上不再要求Send这个bound了。
另外也有一些专门为Threadpoolctl设计的运行时,比如说glommio和monoio,不过这两个除了Threadpoolctl之外还绑定了io_uring作为IO接口,虽然非常合理,因为我们本身就是最好是能够和异步IO相结合使用,但是也让它没有那么灵活,因为作为一个还比较新的系统特性,可能很多存量的服务器系统版本还没有升级,可能就会需要用到我们刚刚提到的那些手段去做一个适配。
在我们的实践中,也有遇到这个问题,为了能够兼容非阻塞的IO接口,需要用到前面提到Blocking的线程方式,可能还要再做一些hike来适配,把它迁移到常用的Runtime上。
还有标准库中的一些工具类也能够派上用场,比如说线程局部存储TLS它能够来代替一些全局变量,因为我们大部分的工作或者计算的整个生命周期内,都会只在一个线程中出现,所以如果能够把这些状态进行划分,也能够更进一步减少状态共享的开销。
另外,在刚刚提到我们使用tokio来模拟Threadpoolctl Runtime的时候,也有使用到tos,就是把每个线程拥有一个正常的tokio Runtime,然后把它放在tos里面来模拟一个Threadpoolctl Runtime。
此外还有Cell类,主要就是用来获取内部可变性的,用来代替锁,在无序竞争的场景下一个比较开销更小的内部可变性的获取。
不过这里RefCell其实还涉及到一个动态运行时的检查,就是它会检查我这个是否有其他的也同时持有这个可变性,有的话它就会导致panic。事实上在我们这个模型中,就像刚才提到的一样,是能够在设计的时候就完全规避掉这个运行时的检查的,所以我们理论上RefCell还可以更进一步提供一个保证。
除了这些,还有一些平时的异步编码的注意事项也会变得很重要,比如前面提到的Blocking操作,或者Clippy中的一些Lint。比如Clippy中这个Lint,我们可能会用RefCell来大量代替锁,所以需要注意await的时机,以这个fn函数为例,比如我们在第一行获取了x的可变引用,但是在第二行把它await走,这个await相当于交出了我们这个函数的执行权,这个时候是能够把其他的任务调度过来的。如果有第二个fn函数在这里进入了,它在尝试去获取x的可变引用,这个时候就相当于一个可变引用被两个函数所持有,这里就会导致一个panic。所以我们需要注意await的时机,await其实就是隐式地会交出执行权。
除了这些,还有很多平常异步编码的时候那些注意事项,在这里可能就是会变得更加重要,因为违背这些事项,可能会带来一些更加严重的后果。就比如说刚刚的Blocking,或者是这里的await holding refcell。
虽然目前已经有很多基础的方式能够让我们相对完整地实现这一个特性,或者说这一个模型,但是我们还是可以从生态或者是基础库的角度做得更好。比如说在设计的时候就考虑能够保证独占访问这一条件的基础类,比如说从channel到Runtime等等,还能够更进一步地压榨性能,以及现在可能到处都要求的Send,那是否在设计的时候我们再加上Send这个trait bound的时候,想一想这里是否真的需要。
总结来说我们目前能够很基础的实现,或者说实现一个相对完整的模型,但是在我看来可能还是有很大的提升空间。
大家如果有任何的提问或者是建议或者是想要的功能,都可以在后台留言联系我们,我们会及时回复大家。
”
