




Fly.io通过将容器升级到全世界运行在我们自己硬件上的成熟虚拟机,在世界各地接近用户的地方运行应用程序。有时候,这些容器运行SQLite,我们也让它变得简单。给我们一个旋转,站起来快跑。
SQL是一个奇怪的概念。您用一种语言编写应用程序,比如JavaScript,然后用一种完全不同的语言(称为SQL)向数据库发送命令。然后,数据库编译并优化该SQL命令,运行它,并返回数据。这看起来非常低效,但您的应用程序可能每秒执行数百次。太疯狂了!
但它变得更奇怪了。
SQL最初是为非技术用户设计的,用于与数据库交互,但是,它几乎完全由软件开发人员使用,他们在整个应用程序中都使用它。
为什么这种为“业务人员”设计的语言会成为构建应用程序的行业标准?
SQL的一个主要优点是它是声明性的。这意味着你告诉数据库你想要什么,而不是怎么做。您的数据库比您更了解您的数据,因此它应该能够更好地决定如何获取和更新数据。这使您可以通过添加索引甚至重新构造表来改进数据层,而对应用程序代码的影响最小。
SQLite在嵌入式数据库中的独特之处在于,它不仅具有事务性的b树存储层,而且还包括一个健壮的SQL执行引擎。今天,我们将深入探讨SQLite如何解析、优化和执行SQL查询。
三明治制造机
如果您已经阅读了我们之前关于SQLite文件格式、回滚日志和WAL的三明治主题SQLite博客文章,那么您现在可能感到非常饥饿。你可能也厌倦了手工制作三明治的单调乏味,所以我们将在这篇博客文章中使用三明治制作机作为类比。
此机器将执行以下任务:
1.点一份三明治。
2.确定制作三明治的最有效方法。
3.把三明治做好,递给你。
构建和执行SQL查询的过程类似于这个三明治构建过程。
教我们的机器阅读
第一步是给我们的机器下订单。我们给它一张订单,上面写着:
Make 3 BLT sandwiches hold the mayo, 1 grilled cheese
对我们的计算机来说,这个顺序只是一个字符串:M、a、k、e等。如果我们想理解它,我们首先需要将这些字母组合成单词,或者更具体地说,“标记”。这个过程被称为“标记化”或“词法化”。
标记化后,我们看到以下标记列表:
"MAKE", "3", "BLT", "SANDWICHES", "HOLD", "THE", "MAYO", ",", "1", "GRILLED", "CHEESE"
然后,我们开始解析阶段。解析器接收一个令牌流,并尝试以某种对计算机有意义的方式对其进行构造。这种结构称为抽象语法树或AST。
三明治命令的AST可能如下所示:
{
"command": "MAKE",
"sandwiches": [
{
"type":"BLT",
"count": 3,
"remove": ["MAYO"]
},
{
"type": "GRILLED CHEESE",
"count": 1
}
]
}
从这里,我们可以开始了解我们如何使用这个定义,并从中开始制作三明治。我们将结构添加到了一个没有结构的文本块中。
SQL的词法分析
SQLite在读取SQL查询时执行相同的过程。首先,它将字符分组为标记,如SELECT或FROM。然后解析器构建一个结构来表示它。
SQLite文档提供了有用的“铁路图”,以表示解析器在使用令牌流时可以采取的路径。SELECT定义显示了如何从with关键字(用于CTE)开始,然后移动到SELECT、FROM和WHERE子句。
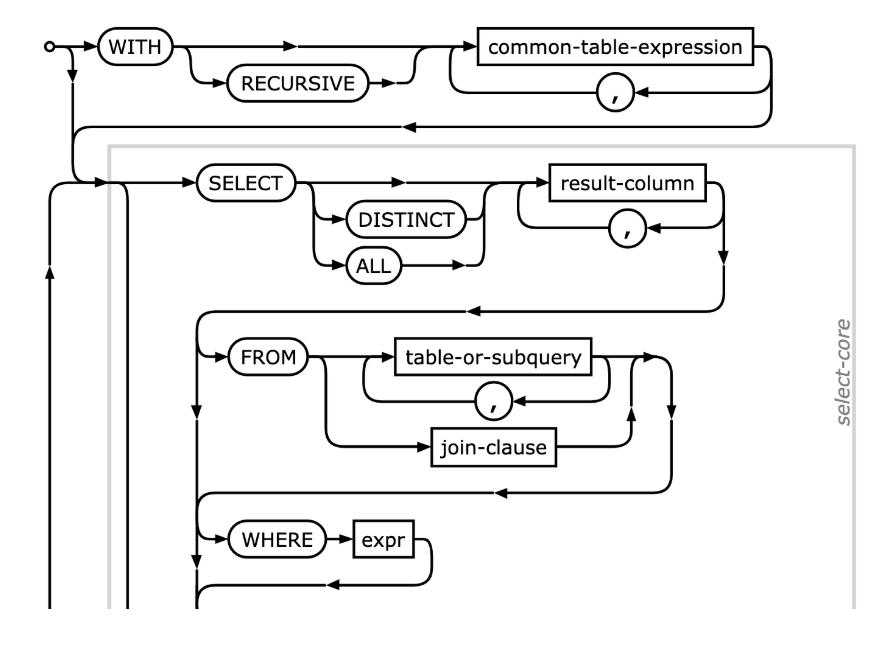
当解析器完成时,它输出适当命名的Select结构。如果您有这样的SQL查询:
SELECT name, age FROM persons WHERE favorite_color = 'lime green'
然后你会得到一个类似这样的AST:
{
"ExprList": ["name", "age"],
"Src": "persons",
"Where": {
"Left": "favorite_color",
"Right: "lime_green",
"Op": "eq"
}
}
确定最佳行动方案
现在我们有了三明治订单,我们有了一个三明治制作计划,对吗?不完全是。
AST代表你想要的东西,就是两个三明治。它没有告诉我们如何做三明治。然而,在我们开始计划之前,我们需要确定制作三明治的最佳方式。
我们的三明治制作机可以组装大量不同的三明治,因此我们储备了各种配料。根据AST的说法,如果我们正在制作一个怪物三明治,里面装着我们大部分可用的配料,那么机器访问每种配料的位置可能是有意义的,不管是否使用。
但对于我们的BLT,我们只需要培根、生菜和西红柿。如果我们能让机器在索引中查找这三个排名的位置,并直接在它们之间跳转,速度会快得多。
在计划如何执行查询时,SQLite也有类似的决策。为此,它使用有关其表内容的统计信息。
使用统计信息进行更快的查询
当SQLite查看AST时,可能有数百种方法访问数据以完成查询。最简单的方法是简单地读取整个表并检查每一行是否匹配。这就是我们在商业界所称的全表扫描,如果您只需要一个大表中的几行,它会非常慢。
另一种选择是使用索引来帮助您快速跳转到所需的行。索引是按一列或多列排序的行标识符列表,因此如果我们有这样的索引:
CREATE INDEX favorite_color_idx ON persons (favorite_color);
然后,爱“紫红色”的人的所有行标识符都在我们的索引中分组在一起。使用索引进行查询意味着我们必须首先读取索引,然后跳转到表中的行。这每行的成本较高,因为它需要两次查找,但是几乎没有人喜欢紫红色,所以我们没有太多匹配行。
但是如果你搜索一种流行的颜色,比如“蓝色”,会发生什么呢?首先搜索索引,然后跳转到我们的表中查找这么多行,实际上比简单搜索整个表要慢。
因此,SQLite对我们的数据进行了一些统计分析,并使用这些信息为每个查询选择(可能)最佳配方。
SQLite的统计数据存储在几个“SQLite_stat”表中。这些表经过多年的发展,有4个不同版本的统计数据,但只有两个版本仍在使用最新版本的SQLite:SQLite_stat1和SQLite_ stat4。
sqlite_stat1表具有简单的格式。它存储每个索引的近似行数,并存储索引列的重复值数。这些粗粒度统计数据相当于跟踪数据集的基本平均值。它们不是超级精确,但计算和更新速度很快。
sqlite_stat4表更高级一些。它将存储分布在索引中的几十个值样本。这些细粒度的示例意味着SQLite可以理解不同值在键空间中的独特性。
执行我们的计划
一旦我们有了一个制作三明治的优化计划,我们就应该让机器把它写下来。这样,如果我们将来再次获得相同的订单,我们可以简单地重用计划,而不必每次都解析和优化订单。
那么这个三明治计划是什么样子的呢?
该计划将记录为机器可以执行的命令列表,以便将来再次构建BLT。我们不希望每种三明治都有一个命令,因为我们可能有很多不同的三明治类型。最好有一套通用的指令,可以重复使用来组成任何三明治计划。
例如,我们可能有以下命令:
FIND_INGREDIENT_BIN(Ingrediment_name)-查找成分的BIN位置。
FETCH_INGREDIENT(bin)-这将使用机器的机械臂从给定的配料箱编号中获取配料。
APPLY_INGREDIENT-将机器人手臂上的配料放到三明治上。
我们还有一个不太明显的要求。我们只有这么多的空间来存放完成的三明治,所以我们需要一次做一个三明治,让顾客在做下一个三明治之前拿下来。这样我们可以一次处理任意数量的三明治。
这种移交过程称为让出,因此我们在等待客户拿三明治的时间和地点会有一个让出命令。
我们还需要一些控制流,以便我们可以制作多个相同类型的三明治,因此我们将添加一个FOREACH命令。
因此,将我们的命令放在一起,我们的计划可能看起来像:
// Make our BLT sandwiches
FOREACH 1...3
bin = FETCH_INGREDIENT_BIN("bacon")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
bin = FETCH_INGREDIENT_BIN("lettuce")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
bin = FETCH_INGREDIENT_BIN("tomato")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
YIELD
END
// Make our grilled cheese
bin = FETCH_INGREDIENT_BIN("cheese")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
GRILL
YIELD
这组特定于域的命令和运行它的执行引擎称为虚拟机。它为我们提供了一个适用于我们试图完成的任务(例如三明治制作)的抽象级别,并允许我们以不同的方式为不同的三明治重新配置命令。
检查SQLite虚拟机
SQLite的虚拟机结构类似。它有一组与数据库相关的命令,可以执行获取查询结果所需的步骤。
例如,让我们从添加了几行的人员表开始:
CREATE TABLE persons (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
favorite_color TEXT
);
INSERT INTO persons
(name, favorite_color)
VALUES
('Vicki', 'black'),
('Luther', 'mauve'),
('Loren', 'blue');
我们可以使用两个不同的SQLite命令检查这一点。第一个命令称为解释查询计划,它提供了一个非常高级别的查询计划。如果我们使用条件为简单的SELECT运行它,那么我们将看到它执行persons表的表扫描:
sqlite> EXPLAIN QUERY PLAN SELECT * FROM persons WHERE favorite_color = 'blue';
QUERY PLAN
`--SCAN persons
在执行更复杂的查询时,此命令可以提供更多信息。现在,让我们看看另一个命令,以进一步检查计划。
令人困惑的是,它被称为解释命令。只需删除第一个命令的“查询计划”部分,它将显示更详细的计划:
sqlite> EXPLAIN SELECT * FROM persons WHERE favorite_color = 'blue';
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- ------------- -- -------------
0 Init 0 11 0 0 Start at 11
1 OpenRead 0 2 0 3 0 root=2 iDb=0; persons
2 Rewind 0 10 0 0
3 Column 0 2 1 0 r[1]=persons.favorite_color
4 Ne 2 9 1 BINARY-8 82 if r[1]!=r[2] goto 9
5 Rowid 0 3 0 0 r[3]=rowid
6 Column 0 1 4 0 r[4]=persons.name
7 Column 0 2 5 0 r[5]=persons.favorite_color
8 ResultRow 3 3 0 0 output=r[3..5]
9 Next 0 3 0 1
10 Halt 0 0 0 0
11 Transaction 0 0 1 0 1 usesStmtJournal=0
12 String8 0 2 0 blue 0 r[2]='blue'
13 Goto 0 1 0 0
这是您的查询被编译到的字节码的“纯英语”表示。这看起来可能令人困惑,但我们可以一步一步地进行分解。
SQLite虚拟机指令集
就像一台计算机如何具有低级CPU操作(如MOV和JMP)一样,SQLite具有类似的指令集,但只是处于更高的级别。在撰写本文时,SQLite VM可以理解186条命令或操作码。您可以在SQLite网站上找到完整的规范,但我们将在这里介绍其中的几个。
第一个操作码是Init,它初始化我们的执行,然后跳转到程序中的另一条指令。操作码的参数列为p1到p5,其定义特定于每个命令。对于Init操作码,它跳转到p2中列出的指令,即11。
在地址11,我们到达开始交易的交易操作码。对于大多数操作码,VM将在执行指令后移动到下一个地址,因此我们移动到地址12。此String8操作码将字符串值“blue”存储到寄存器r[2]。寄存器的作用类似于一组内存地址,用于在执行期间存储值。稍后我们将使用该值进行等式比较。
接下来,我们移动到地址13,这是一条Goto指令,它让我们跳转到p2参数中列出的指令,即地址1。
现在我们进入行处理。OpenRead指令打开persons表上的光标。游标是用于在表中迭代或移动的对象。下一条指令Rewind将光标移到数据库的第一个条目,开始表扫描。
列指令将favorite_color列读入寄存器r[1],Ne指令将其与寄存器r[2]中的“蓝色”值进行比较。如果这些值不匹配,我们将转到地址9处的下一条指令。如果它们匹配,我们会在寄存器r[3]、r[4]、&r[5]中填入该行的列id、名称和favorite_color。
最后,我们可以使用ResultRow指令将结果返回给调用方。这将允许调用应用程序复制寄存器r[3…5]中的值。当调用应用程序调用sqlite3_step()时,程序将通过调用Next并跳回到指令3重新执行行处理,从停止的位置恢复。
当Next不再生成任何行时,它将跳转到Halt指令,程序完成。
包装我们的三明治加工引擎
SQLite的查询执行端对进入数据库的每个查询都遵循这个简单的解析优化执行计划。我们可以利用这些知识来提高应用程序性能。通过在SQL语句中使用绑定参数(也称为占位符),我们可以准备一次语句,并在每次重用时跳过解析和优化阶段。
SQLite使用虚拟机方法执行查询,但这不是唯一可用的方法。例如,Postgres使用基于节点的执行计划,其结构非常不同。
现在您已经了解了执行计划的基本工作原理,请尝试在一个更复杂的查询上运行EXPLAIN,看看您是否能够理解查询如何具体化为应用程序的结果集的逐步执行。
原文标题:How the SQLite Virtual Machine Works
原文作者:Ben Johnson
原文链接:https://fly.io/blog/sqlite-virtual-machine
