




这是 Databricks 和 Hightouch 的合作帖子。我们感谢 Hightouch 的产品宣传员 Luke Kline 的贡献。
您已完成在 Databricks 上设置数据湖库。您有一个集中的位置,您可以在其中执行各种形式的分析、机器学习、人工智能和商业智能。
您的数据工程师很兴奋,因为他们终于可以开始处理您的所有流式用例,而您的数据科学家可以开始专注于您的数据科学和机器学习用例。您的数据工程师能够利用这些信息来构建相关的数据模型来为您的业务给与支持,您的数据分析师也很兴奋,因为他们现在能够在接到通知后立即运行快速的临时查询。
由于数据驻留在 Databricks 中,Hightouch 支持反向 ETL,其中数据可以移动到广告、营销、成功和其他业务平台等运营系统中,以扩展湖库分析的价值。Hightouch 可以帮助您的业务团队了解所有这些分析的价值,这些团队需要访问 Lakehouse 中存在的独特客户数据:
- 数据模型:(订阅类型、LTV、ARR、产品合格线索、观看内容等)
- 产品使用数据:(发送的消息、上次登录、创建的工作区、新用户等)
- 事件数据:(浏览的页面、会话时长、购物车放弃、购物车中的物品等)
将这些数据移出 Databricks 现在非常容易。您不必为潜在的数十个目的地(广告、营销、CRM、客户成功、ERP 等)构建自定义数据管道。Hightouch 给与了一个平台和编程方法,以确保您的数据采用正确的格式以被摄取。
这些管道的维护现在同样高效,因为 Hightouch 负责管理不断变化的上游或下游系统的 API。最重要的是,Hightouch 给与了通过实时调试和版本控制来管理数据质量的简单方法。
您不再需要在内部维护劳动密集型管道。Databricks 上的 Hightouch是 Reverse ETL 的绝佳解决方案,可将数据交到业务用户手中,在那里可以对其采取行动并立即对您的业务产生影响。
解决方案:反向 ETL
反向 ETL是将转换后的数据移回运行业务流程的工具的过程。通常,目的地由用于增长、营销、销售和支持的 SaaS 工具组成。反向 ETL 不再使用仪表板做出决策,而是将重点转移到通过运营分析使您的数据集发挥作用——将洞察力自动转化为行动。
如果您的最佳数据仅存在于 Databricks 中,那么您的业务团队将依赖通用信息来支持他们的日常活动。这可能很简单,例如为您的销售团队给与新线索的更新产品使用情况、与您的营销团队共享新受众以进行广告重定向、帮助您的客户成功团队确定应优先考虑哪些支持票或通知您的团队成员当您的应用中发生特定事件时。
您可能会想到几个数据示例,这些示例将在您的业务中的其他地方得到更好的服务。Hightouch 可以使用反向 ETL 解决许多用例,您很快就会明白为什么像 Nauto 这样的技术优先公司正在使用 Hightouch 来增强 Databricks。
如何开始使用 Hightouch 同步数据
注意:Hightouch 从不存储您的数据,因此您不必担心合规性。
第 1 步:将 Hightouch 连接到 Databricks。
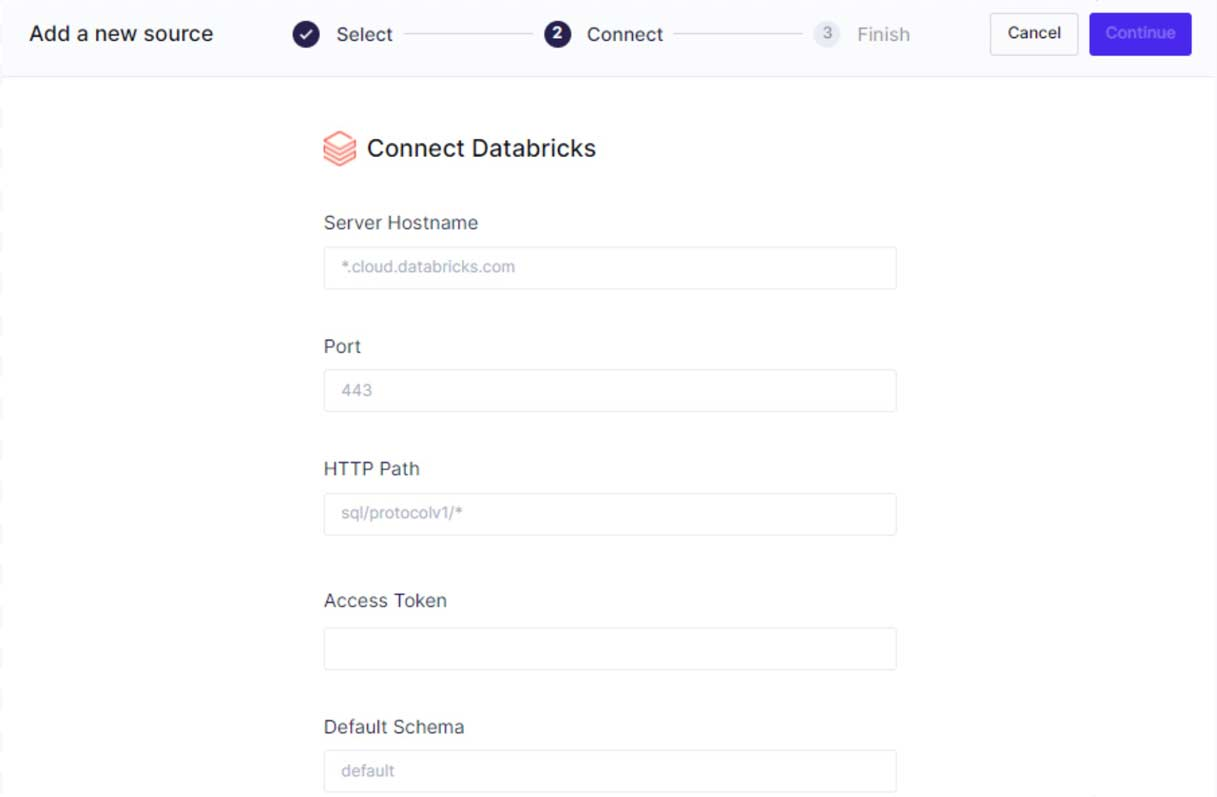
第 2 步:将 Hightouch 连接到您的目的地。
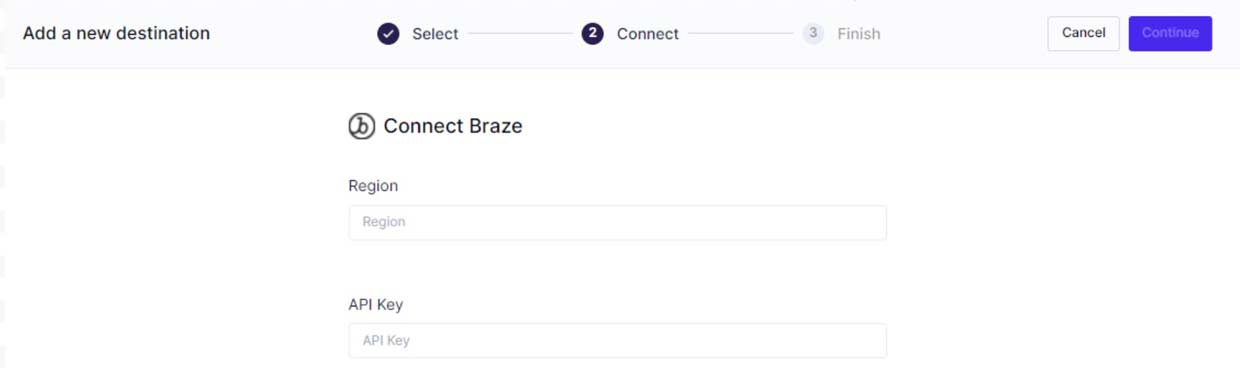
第 3 步:创建数据模型或利用现有模型。
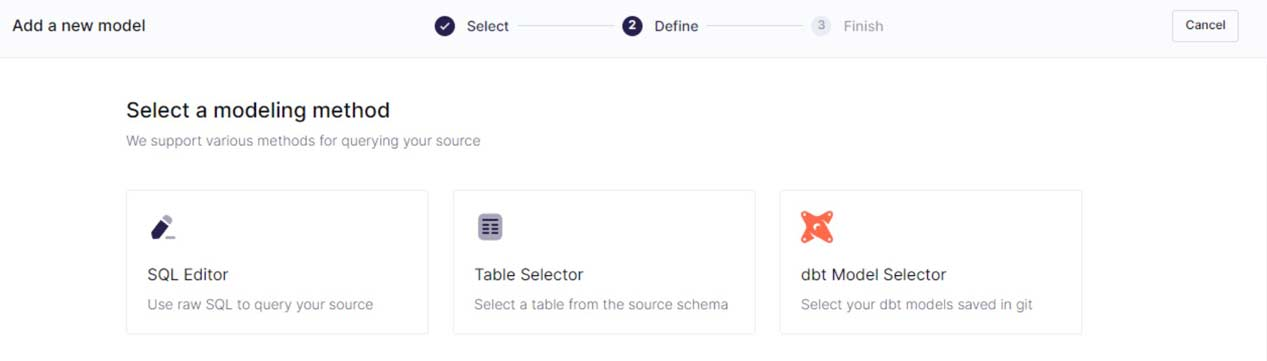
第 4 步:选择您的主键。
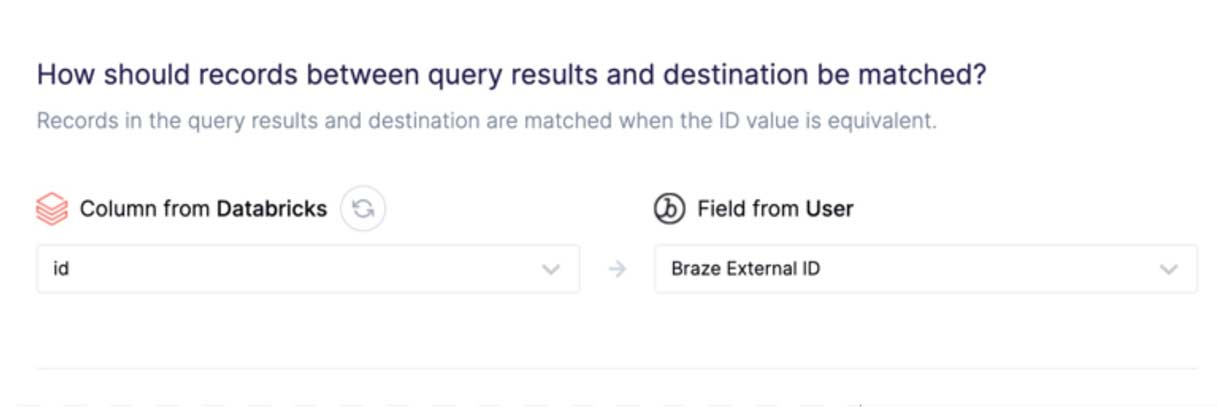
第 5 步:创建同步并将 Databricks 列映射到最终目标字段。
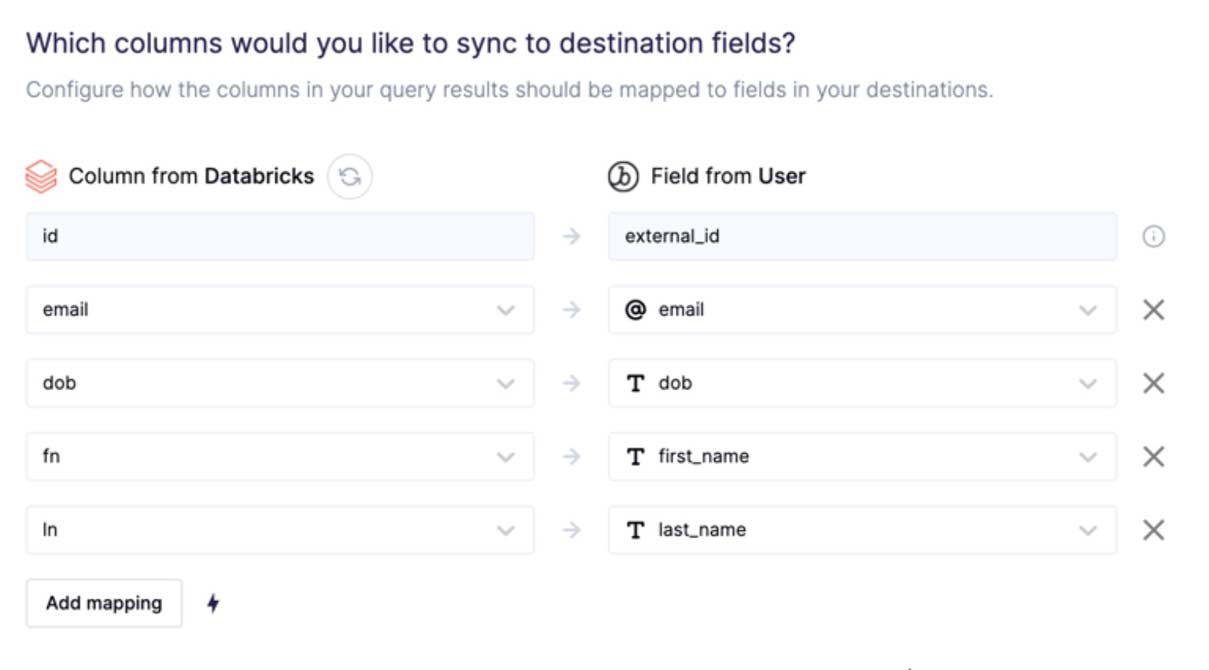
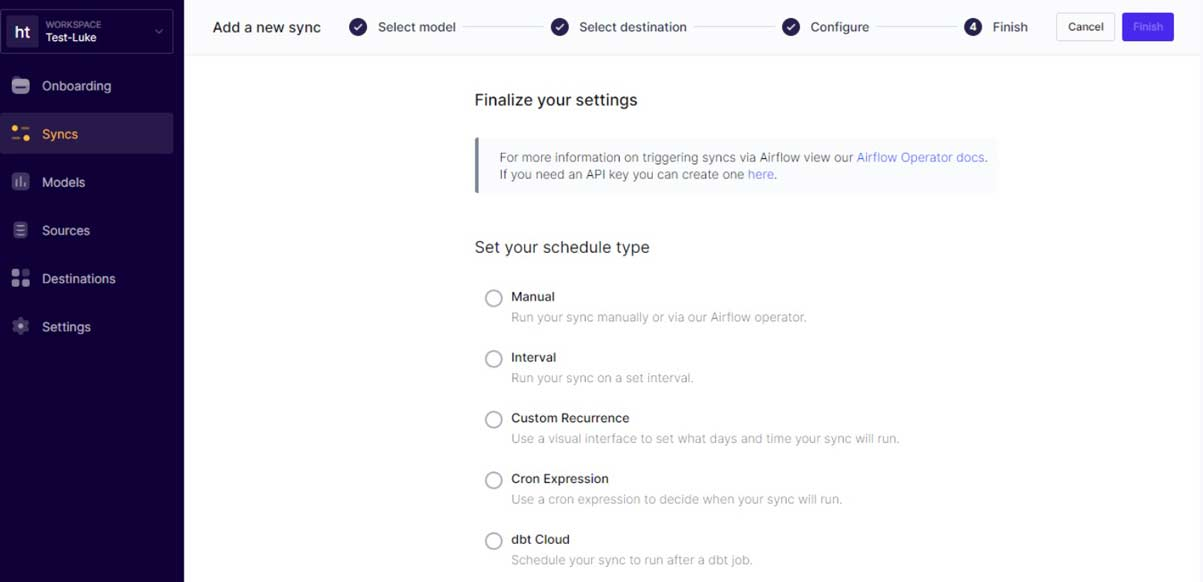
第 6 步:安排同步。
Databricks 和 Hightouch 入门
有关如何开始将数据从 Databricks 发送到 Hightouch 的更多信息,请访问Databricks 文档。您可以通过注册14天免费试用免费测试 Databricks 上的集成。如果您想了解有关反向 ETL 的更多信息,请下载 Hightouch 的指南。与 Hightouch 的首次集成是免费的,因此您可以自行测试或在此处预订演示。
原文标题:Using Hightouch for Reverse ETL With Databricks
原文作者:Prasad Kona and Luke Kline
原文地址:https://www.databricks.com/blog/2022/04/01/using-hightouch-for-reverse-etl-with-databricks.html
