




我们很高兴地宣布 Apache Airflow 对 Databricks 支持的一系列增强。这些新功能使在流行的开源编排器中构建强大的数据和机器学习 (ML) 管道变得容易。借助最新的增强功能(例如新的 DatabricksSqlOperator),客户现在可以使用 Airflow 在 Databricks 上使用标准 SQL 查询和摄取数据,在笔记本上运行分析和 ML 任务,触发 Delta Live Tables 以转换 Lakehouse 中的数据等等。
Apache Airflow 是一个流行的可扩展平台,可使用 Python 以编程方式创作、调度和监控数据和机器学习管道(在 Airflow 中称为 DAG)。Airflow 包含大量内置操作符,可以轻松与从数据库到云存储的所有内容进行交互。Databricks 自 2017 年以来一直支持Airflow,使 Airflow 用户能够在 Databricks 的 Lakehouse 平台上触发结合笔记本、JAR 和 Python 脚本的工作流,该平台可扩展到地球上最具挑战性的数据和 ML 工作流。
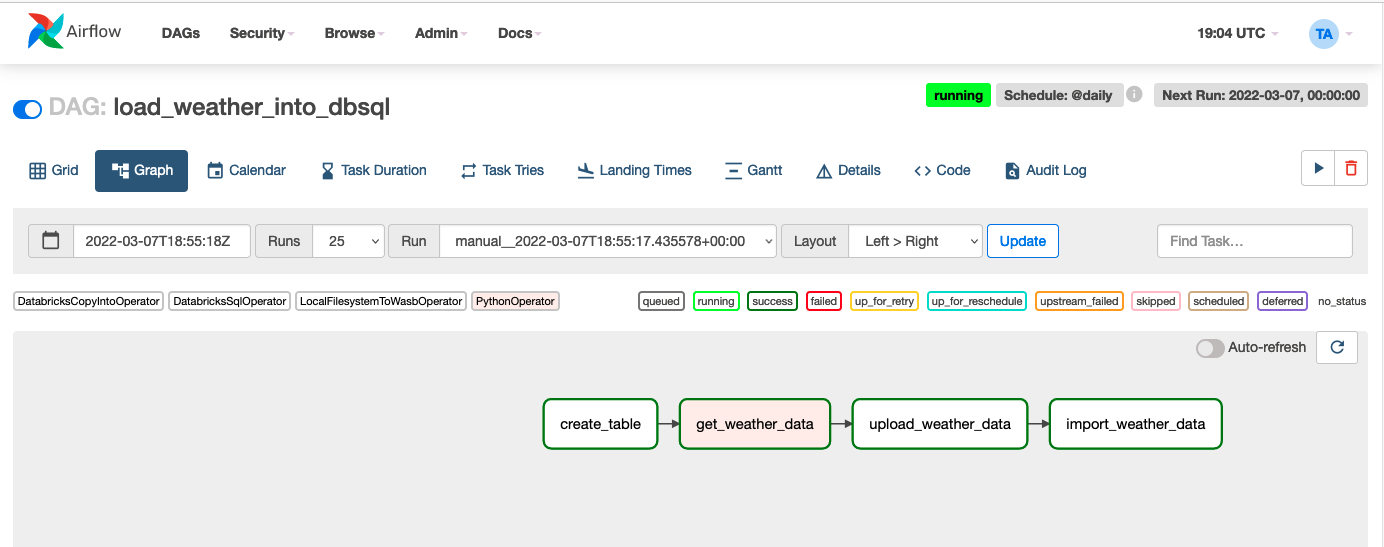
让我们通过一个真实的任务来了解新功能:构建一个简单的数据管道,将 API 中的新到达天气数据加载到 Delta 表中,而无需使用 Databricks 笔记本来执行该工作。出于这篇博文的目的,我们将在 Azure 上完成所有工作,但在 AWS 和 GCP 上的过程几乎相同。此外,我们将在SQL 端点上执行所有步骤,但如果您更喜欢使用通用 Databricks 集群,则该过程非常相似。最后一个示例 DAG 在 Airflow UI 中将如下所示:
为简洁起见,我们将从这篇博文中省略一些代码。
安装和配置 Airflow
这篇博文假设您安装了 Airflow 2.1.0 或更高版本并配置了Databricks 连接。为 Apache Airflow 安装最新版本的 Databricks 提供程序:
pip install apache-airflow-providers-databricks
创建一个表来存储天气数据
我们将 Airflow DAG 定义为每天运行。第一个任务create_table运行一条 SQL 语句,如果该表不存在,则在默认模式中创建一个名为airflow_weather的表。此任务演示了DatabricksSqlOperator,它可以在 Databricks 计算上运行任意 SQL 语句,包括 SQL 端点。
with DAG(
"load_weather_into_dbsql",
start_date=days_ago(0),
schedule_interval="@daily",
default_args=default_args,
catchup=False,
) as dag:
table = "default.airflow_weather"
schema = "date date, condition STRING, humidity double, precipitation double, " \
"region STRING, temperature long, wind long, " \
"next_days ARRAY<struct>"
create_table = DatabricksSqlOperator(
task_id="create_table",
sql=[f"create table if not exists {table}({schema}) using delta"],
)
</struct>
从 API 检索天气数据并上传到云存储
接下来,我们使用 PythonOperator 向天气 API 发出请求,将结果存储在一个临时位置的 JSON 文件中。
一旦我们在本地获得天气数据,我们使用 LocalFilesystemToWasbOperator 将其上传到云存储,因为我们使用的是 Azure 存储。当然,Airflow 也支持将文件上传到 Amazon S3 或 Google Cloud Storage:
get_weather_data = PythonOperator(task_id="get_weather_data",
python_callable=get_weather_data,
op_kwargs={"output_path": "/tmp/{{ds}}.json"},
)
copy_data_to_adls = LocalFilesystemToWasbOperator(
task_id='upload_weather_data',
wasb_conn_id='wasbs-prod,
file_path="/tmp/{{ds}}.json",
container_name='test',
blob_name="airflow/landing/{{ds}}.json",
)
请注意,上面使用 {{ds}} 变量来指示 Airflow 将变量替换为计划任务运行的日期,从而为我们提供一致、不冲突的文件名。
将数据提取到表中
最后,我们准备将数据导入表中。为此,我们使用方便的DatabricksCopyIntoOperator,它会生成一个COPY INTO SQL 语句。COPY INTO 命令是一种简单而强大的方法,可以将文件从云存储中幂等地摄取到表中:
import_weather_data = DatabricksCopyIntoOperator(
task_id="import_weather_data",
expression_list="date::date, * except(date)",
table_name=table,
file_format="JSON",
file_location="abfss://mycontainer@mystoreaccount.dfs.core.windows.net/airflow/landing/", files=["{{ds}}.json"])
就是这样!我们现在有一个可靠的数据管道,只需几行代码,就可以将 API 中的数据提取到表中。
但这还不是全部……
我们也很高兴地宣布改进,使 Airflow 与 Databricks 的集成变得轻而易举。
- DatabricksSubmitRunOperator 已升级为使用最新的 Jobs API v2.1。借助新 API,可以更轻松地为使用 DatabricksSubmitRunOperator 提交的作业配置访问控制,因此开发人员或支持团队可以轻松访问作业 UI 和日志。
- Airflow 现在可以触发 Delta Live Table 管道。
- Airflow DAG 现在可以为 JAR 任务类型传递参数。
- 可以将 Databricks Repos 更新到特定的分支或标签,以确保作业始终使用最新版本的代码。
- 在 Azure 上,可以使用 Azure Active Directory 令牌而不是个人访问令牌 (PAT)。例如,如果 Airflow 在具有托管标识的 Azure VM 上运行,Databricks 操作员可以使用托管标识向 Azure Databricks 进行身份验证,而无需 PAT 令牌。在此处了解有关此和其他身份验证增强功能的更多信息。
Databricks 上的 Airflow 用户的未来一片光明
我们对这些改进感到兴奋,并期待看到 Airflow 社区使用 Databricks 构建的内容。我们很想听听您对我们接下来应该添加哪些功能的反馈。
原文标题:Build Data and ML Pipelines More Easily With Databricks and Apache Airflow
原文作者:Alex Ott, Bilal Aslam, Lennart Kats, Shant Hovsepian and Robert Saxby
原文地址:https://www.databricks.com/blog/2022/04/29/build-data-and-ml-pipelines-more-easily-with-databricks-and-apache-airflow.html
