




规划我的旅程
我想带您了解我如何使用 Databricks 最近推出的 Delta Live Tables 产品来构建一个端到端分析应用程序,该应用程序使用实时数据和仅限 SQL 的技能集。
我于 2021 年 11 月上旬加入 Databricks,担任产品经理。我显然还是该公司的新手,但自 90 年代中期以来,我一直从事数据仓库、BI 和业务分析方面的工作。在我的时代,我已经建立了相当多的数据仓库和数据集市(Kimball 或 Inmon,任你选择),并且几乎曾经使用过几乎所有的 ETL 和 BI 工具。
按照今天的标准,我不是数据工程师。我很了解 SQL,但我更像是点击者而不是编码器。我的技术经验是使用 Informatica、Trifacta(现在是Alteryx的一部分)、DataStage等工具与 Python 和 Scala 等语言。我认为我的角色更像是我们 dbt 实验室的朋友所说的分析工程师与数据工程师。
因此,以所有这些为背景,为了尽可能多地学习 Databricks 产品(考虑到我在公司的新手身份),我开始了构建我的应用程序的旅程。而且我不希望它只是另一个无聊的静态 BI 仪表板。我想用实际的实时数据构建更类似于生产应用程序的东西。
因为我住在芝加哥,所以我将使用 Divvy Bikes 数据。我见过很多使用他们的静态数据集的演示,但几乎没有使用他们的实时 API。这些 API 跟踪全市所有 842 个车站的“实时”车站状态(例如 # 辆自行车可用、# 码头可用等)。鉴于自行车租赁非常依赖天气,我将使用OpenWeather API将这些数据与每个站点的实时天气信息结合起来。这样我们就可以看到残酷的芝加哥冬季对 Divvy Bike 使用的影响。
捕获和摄取源数据
鉴于我们的数据源是Divvy Bikes和OpenWeather API,我需要做的第一件事是弄清楚如何捕获这些数据,以便它可以在我们的云数据湖中使用(即在我的情况下为 ADLS,因为我的 Databricks 工作区在 Azure 中运行)。
我可以为这项任务选择很多数据摄取工具。通过我们的合作伙伴连接生态系统,只需单击几下即可使用其中的许多功能,例如 Fivetran 。但是,为了简单起见,我只创建了3 个简单的 Python 脚本来调用 API,然后将结果写入数据湖。
构建和测试后,我将脚本配置为两个不同的 Databricks Jobs。
第一个作业每分钟获取一次实时站点状态,返回一个 JSON 文件,其中包含芝加哥所有 1,200 个左右 Divvy Bike 站点的当前状态。示例有效载荷如下所示。管理数据量和文件数量将在这里受到关注。我们每分钟都在检索每个站点的状态。这将每天收集 1,440 个 JSON 文件(60 个文件/小时*24 小时)和约 170 万个新行。以这样的速度,一年的数据为我们提供了大约 52 万个 JSON 文件和大约 6.3 亿行需要处理。
第二个作业包含两个每小时运行的任务。
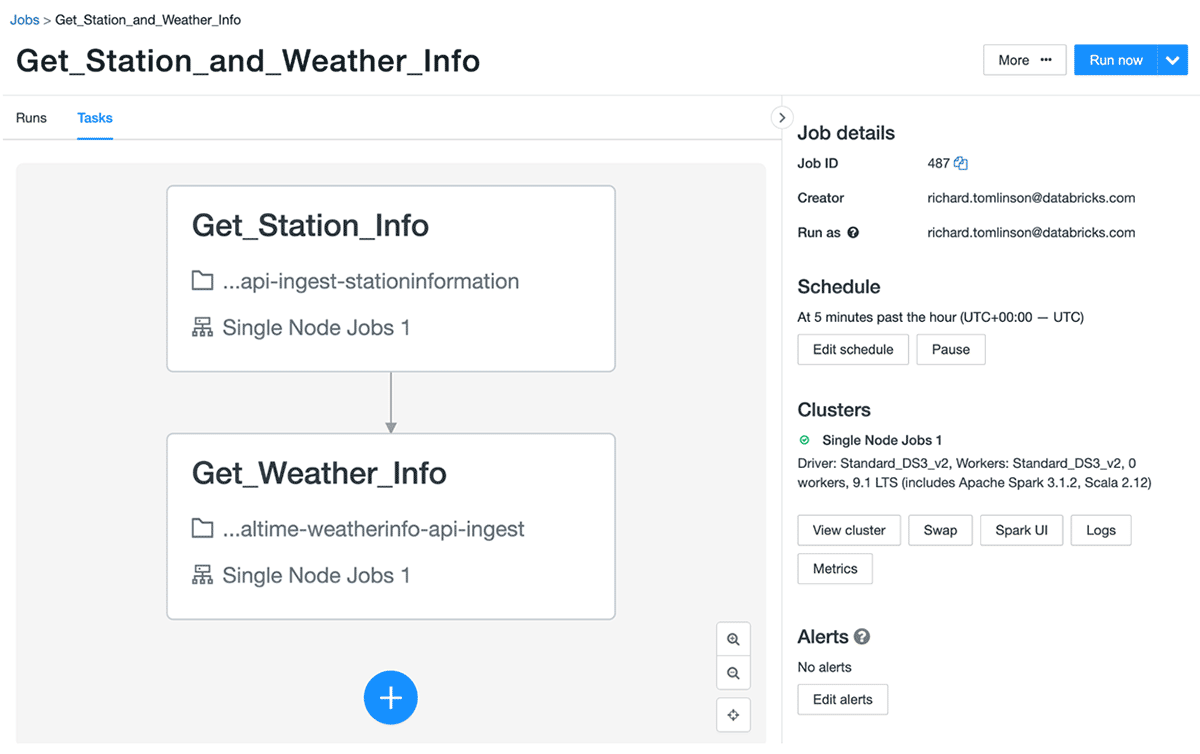
第一个任务检索每个站点的描述性信息,例如名称、类型、纬度、经度等。这是数据仓库术语中的经典“缓慢变化维度”,因为我们不希望这些信息经常变化。尽管如此,我们还是会每小时刷新一次数据,以防万一;例如,一个新站可能会上线,或者现有站可能会更新或停用。在此处查看示例有效负载。
然后,作业中的第二个任务为大约 1200 个站点中的每个站点获取实时天气信息。这是其中一个站的示例有效载荷。我们使用其纬度/经度坐标调用 API。由于我们将为每个站点调用 OpenWeather API,因此我们每天最终会收到 28,800 个文件 (1200*24)。推断一年后,我们可以管理约 1050 万个 JSON 文件。
这些脚本已经运行了一段时间。我于 2022 年 1 月 4 日开始使用它们,从那时起,它们一直在我的数据湖中愉快地创建新文件。
实现我的“简单”演示实际上非常复杂
知道我现在需要混合和转换所有这些数据,并对潜在体积进行了数学计算,并稍微查看了数据样本,这就是我开始出汗的地方。我咬得比我能咀嚼的多吗?与您的平均“静态”仪表板相比,有几件事使这个具有挑战性:
1.我不知道如何管理全天不断到达的数千个新 JSON 文件。我还想捕捉几个月的数据来查看历史趋势。需要管理数百万个 JSON 文件!
2.如何构建实时 ETL 管道以使数据为快速分析做好准备?我的源数据是原始 JSON,需要清理、转换、与其他源连接以及聚合以提高分析性能。在我的管道中将有大量的步骤和依赖项需要考虑。
3.如何处理增量负载?当数据不断流入数据湖并且我们想要构建实时仪表板时,我显然无法从头开始重建我的表。所以我需要找到一种可靠的方法来处理不断移动的数据。
4.OpenWeather JSON 模式是不可预测的。我很快了解到架构会随着时间而改变。例如,如果没有下雪,则不会在有效负载中返回下雪指标。当您无法预测源架构时,您如何设计目标架构!?
5.如果我的数据管道出现故障会怎样?我怎么知道它何时失败以及如何在它停止的地方重新启动它?我如何知道哪些 JSON 文件已被处理,哪些尚未处理?
6.我的仪表板中的查询性能如何?如果它们是实时仪表板,则它们需要很敏捷。当新数据不断流入时,我不能有未完成的查询。为了复合这一点,我将很快处理数亿(如果不是数十亿)行。我如何为此进行性能调整?如何随着时间的推移优化和维护我的源文件?帮助!
好的,我现在就停下来。刚写下这份清单我就慌了,我敢肯定还有一百个小障碍要跳过。我什至有时间建造这个吗?也许我应该只看一些其他人这样做的视频并收工?
不,我会继续努力的!
使用 Delta Live Tables 减压
好的,接下来——如何编写实时 ETL 管道。好吧,不是“真实的”实时。我称之为近实时——我敢肯定,当 90% 的人说他们需要实时时,这就是他们真正的意思。鉴于我每分钟只从 API 中提取数据,我不会获得比我的分析应用程序中更新鲜的数据。对于这样的监控用例来说,这很好。
Databricks 最近宣布全面推出 Delta Live Tables(又名 DLT)。DLT 恰好适合这一点,因为它提供了“一种简单的声明式方法来构建可靠的数据管道,同时自动大规模管理基础设施,因此数据分析师和工程师可以花更少的时间在工具上,专注于从数据中获取价值。” 听起来不错!
DLT 还允许我在SQL中构建管道,这意味着我可以保持我的纯 SQL 目标。对于它的价值,如果你愿意,它还允许你在Python中构建管道——但这不适合我。
最大的胜利是 DLT 允许您编写声明性 ETL 管道,这意味着我可以将时间花在“做什么”而不是“如何”上,而不是手动编写低级 ETL 逻辑。使用 DLT,我只是指定如何转换和应用业务逻辑,而 DLT 会自动管理管道中的所有依赖项。这可以确保我的管道中的所有表都以正确的顺序正确填充。
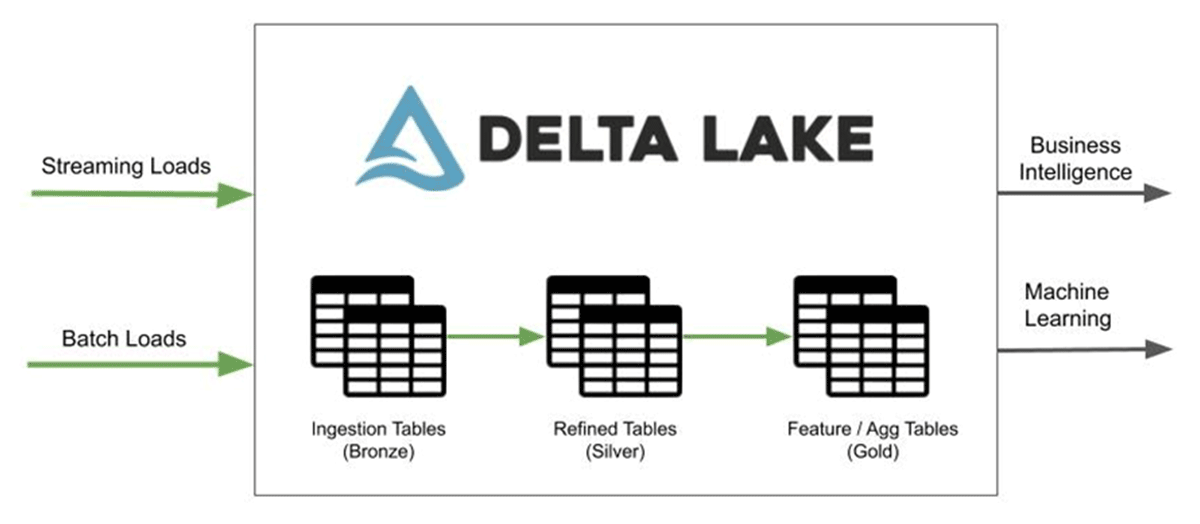
这很棒,因为我想构建一个奖章架构来简化变更数据捕获并在同一数据上启用多个用例,包括那些涉及数据科学和机器学习的用例——这是使用Lakehouse的众多原因之一。
DLT 的其他大好处包括:
- 数据质量检查以根据我设置的期望(规则)在流经管道时验证记录
- 自动错误处理和恢复——所以如果我的管道出现故障,它可以恢复!
- 开箱即用的监控,因此我可以查看实时管道健康统计数据和趋势
- 单击部署到生产和回滚选项,让我可以选择遵循 CI/CD 模式
更重要的是,DLT 可以批量或连续工作!这意味着我可以让我的管道“始终开启”,而不必了解复杂的流处理或如何实现恢复逻辑。
好的,所以我认为这解决了我在上一节中的大部分担忧。我可以感觉到我的压力水平已经下降。
快速浏览 DLT SQL 代码
那么这一切是什么样的呢?如果您想动手操作,可以在此处下载我的 DLT SQL 笔记本;这很简单,但我会带你了解重点。
首先,我们在奖章架构中构建青铜表。这些表只是以表格式表示原始 JSON。在此过程中,我们将 JSON 数据转换为 Delta Lake 格式,这是一种开放格式的存储层,可在数据湖上提供可靠性、安全性和性能。在这一步中,我们并没有真正转换数据。以下是其中一张表的示例:

首先,请注意我们已将其定义为“STREAMING”活动表。这意味着该表将根据不断到达的数据自动支持更新,而无需重新计算整个表。
您还会注意到,我们还使用 Auto Loader (cloud_files) 从对象存储 (ADLS) 中读取原始 JSON。Auto Loader 是该管道的关键部分,它提供了一种无缝方式来以低成本和延迟加载原始数据,并且只需最少的 DevOps 工作量。
Auto Loader 会在新文件登陆云存储时增量处理它们,因此我不需要管理任何状态信息。它通过利用云服务有效地跟踪到达的新文件,而无需列出目录中的所有文件。即使目录中有数百万个文件,它也是可扩展的。它也非常易于使用,并且会自动设置增量处理所需的所有内部通知和消息队列服务。
它还处理模式推断和演化。您可以在此处阅读更多内容,但简而言之,这意味着我不必提前知道 JSON 模式,它会随着时间的推移优雅地处理“不断发展”的模式,而不会导致我的管道失败。非常适合我的 OpenWeather API 负载 - 消除了另一个压力因素。
一旦我定义了所有青铜级别的表,我就可以开始做一些真正的 ETL 工作来清理原始数据。这是我如何创建“银”奖章表的示例:
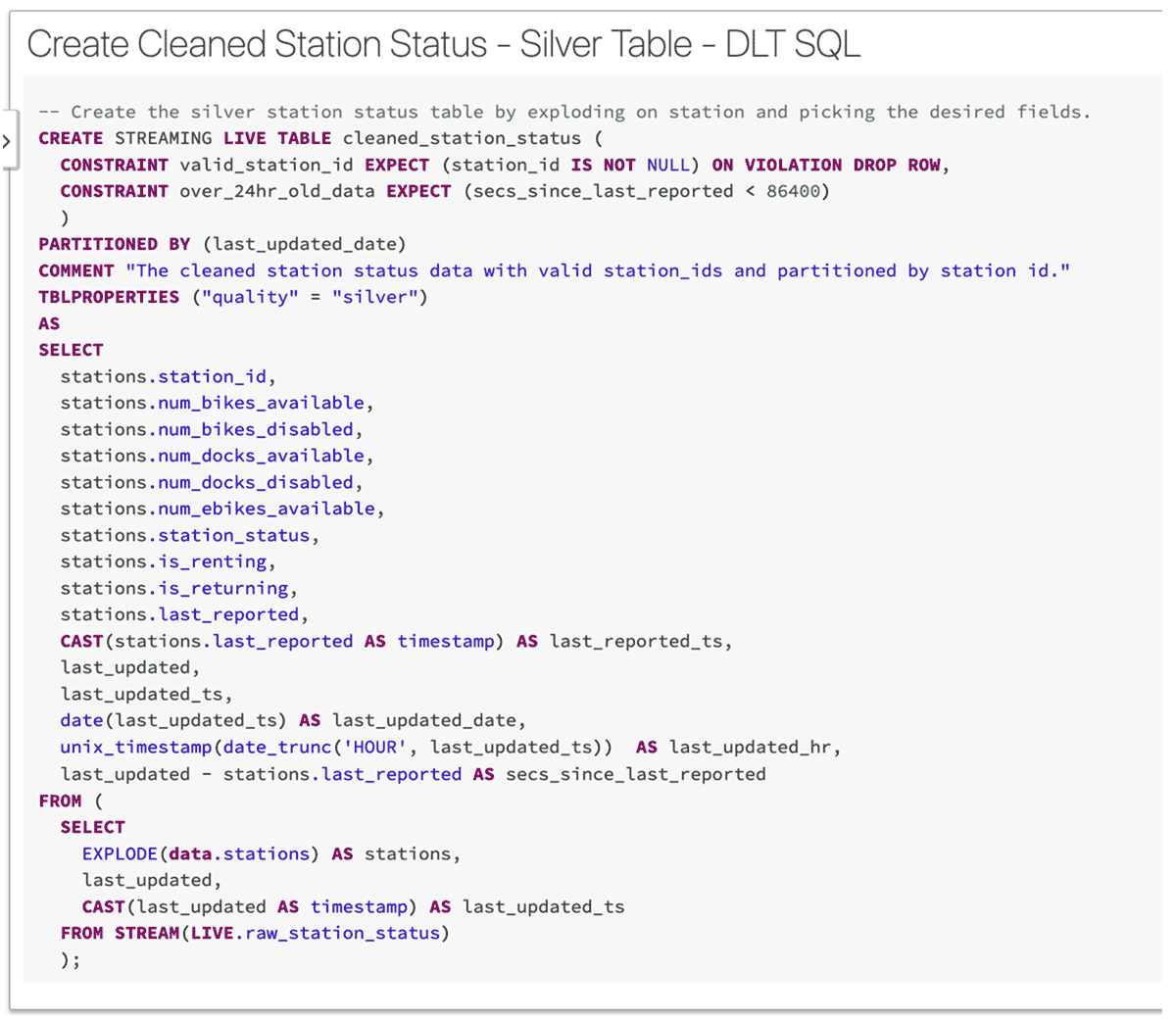
你会注意到这里有很多很酷的东西。首先,它是另一个流式表,因此一旦数据到达源表(raw_station_status),它就会立即流式传输到该表。
接下来,请注意我设置了 station_id 不是 NULL 的规则。这是DLT 期望或数据质量约束的示例。我可以声明任意数量的这些。期望由描述、规则(不变量)和记录未通过规则时采取的操作组成。上面我决定在遇到 NULL station_id 时从表中删除该行。Delta Live Tables 在日志中捕获管道事件,因此我可以轻松监控诸如触发规则的频率之类的事情,以帮助我评估我的数据质量并采取适当的行动。
我还添加了注释和表格属性,因为这是最佳实践。谁不喜欢元数据?
最后,您可以释放 SQL 的全部功能,以完全按照您的需要转换数据。请注意我如何将我的JSON分解为多行并执行一大堆日期时间转换以用于进一步下游的报告目的。
处理缓慢变化的尺寸
上面的示例概述了用于加载事务表或事实表的 ETL 逻辑。因此,我们需要处理的下一个常见设计模式是渐变维度(SCD)的概念。幸运的是,DLT 也可以处理这些!
Databricks 刚刚宣布 DLT支持常见的 CDC 模式,并为 SQL 和 Python 提供了新的声明性 APPLY CHANGES INTO 功能。这项新功能使 ETL 管道可以轻松检测源数据更改并将其应用于整个湖库的数据集。DLT 以增量方式处理 Delta Lake 中的数据更改,在处理 CDC 事件时标记要插入、更新或删除的记录。
我们的 station_information 数据集是什么时候使用它的一个很好的例子。

如果行已经存在(基于 station_id),我们不是简单地追加,而是更新行,如果不存在则插入新行。我什至可以使用 APPLY AS DELETE WHEN 条件删除记录,但我很久以前就知道我们从不删除数据仓库中的记录。因此,这被归类为SCD 类型 1。
部署数据管道
到目前为止,我只在我的管道中创建了青铜和白银表,但这没关系。我可以创建黄金级表来提前预聚合我的一些数据,使我的报告运行得更快,但我不知道我是否还需要它们,以后可以随时添加它们。
所以部署的数据管道目前看起来是这样的:
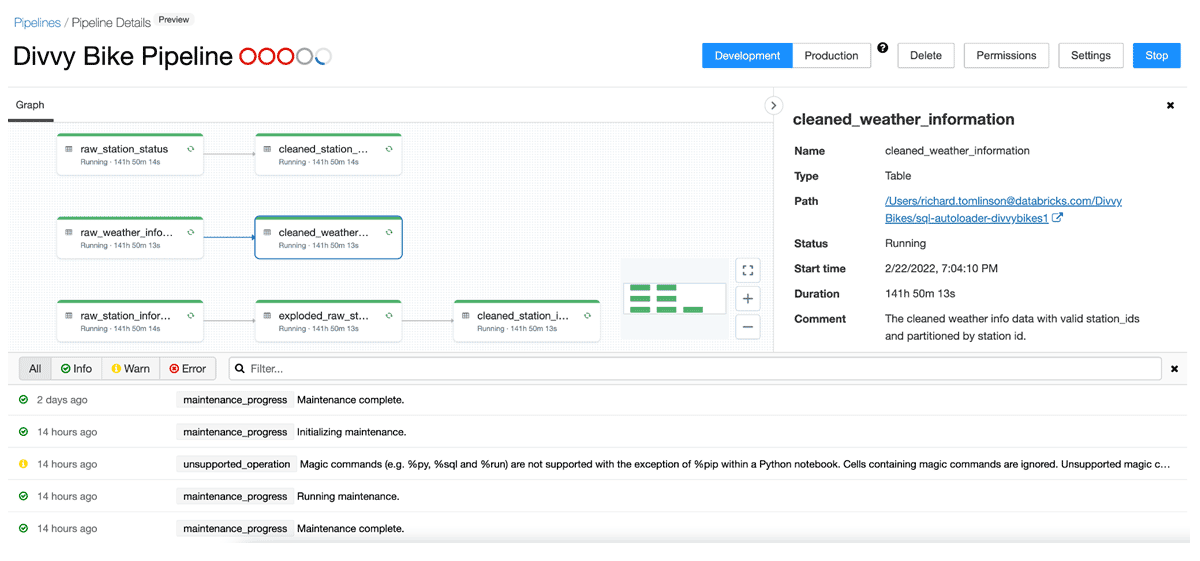
3 个青铜(原始)表、一个中间视图(一些 JSON 体操需要)和 3 个准备报告的银表。
部署管道也很容易。我只是将我所有的 SQL 放入一个笔记本并创建了一个连续的(与触发的)DLT 管道。由于这是一个演示应用程序,我尚未将其投入生产,但有一个按钮,我可以在此处在开发和生产模式之间切换,以更改管道运行的底层基础设施。在开发模式下,我可以避免自动重试和集群重启,但在生产中打开这些。我也可以随心所欲地启动和停止这个管道。DLT 只是跟踪它已加载的所有文件,因此确切地知道从哪里获取。
使用 Databricks SQL 创建令人惊叹的仪表板
最后一步是构建一些仪表板,以可视化所有这些数据如何实时组合在一起。这个特定博客的重点更多地放在 DLT 和数据工程方面,所以我将在后续文章中讨论我构建的查询类型。
您还可以在此处下载我的仪表板 SQL 查询。
我的查询、可视化和仪表板是使用Databricks SQL (DB SQL) 构建的。我可以继续详细介绍Photon查询引擎令人惊叹的破纪录功能,但这也是另一次了。
DB SQL 包括数据可视化和仪表板功能,我在本例中使用了这些功能,但您也可以连接您最喜欢的BI 或数据可视化工具,所有这些都可以无缝工作。
我最终构建了 2 个仪表板。我将快速浏览每一个。
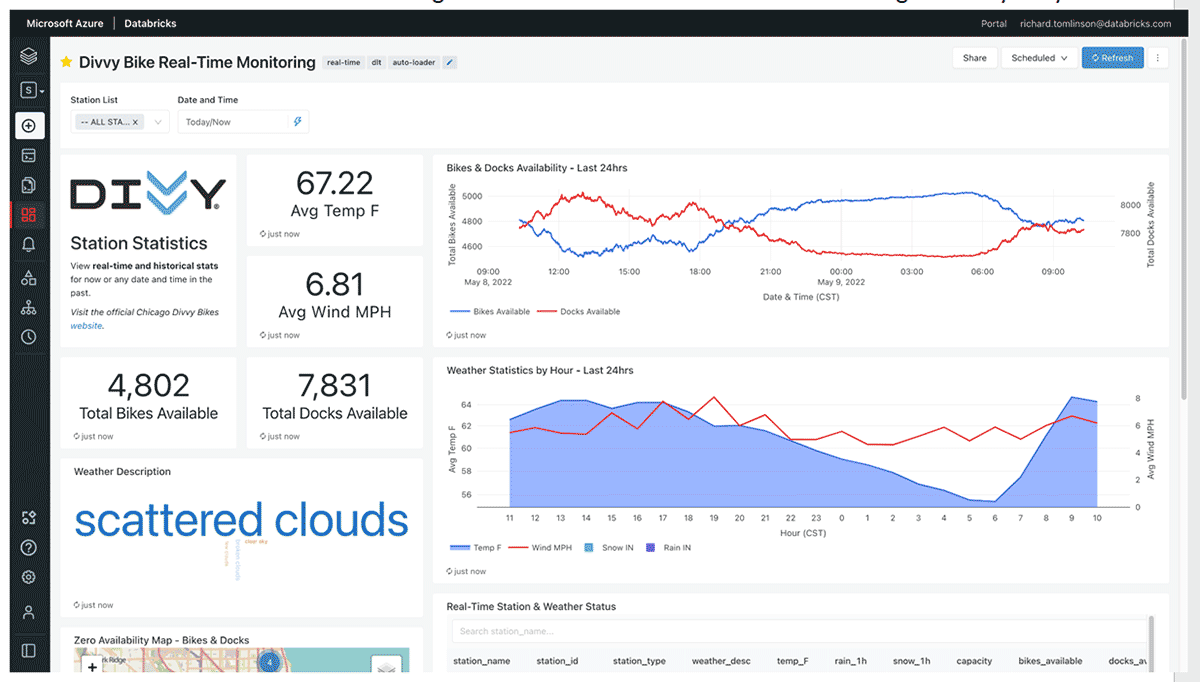
第一个仪表板侧重于实时监控。它根据自行车/码头的可用性以及每个站点的天气统计数据显示任何站点的当前状态。它还显示了过去 24 小时的趋势。“现在”显示的指标永远不会超过一分钟,因此它是一个非常可操作的仪表板。值得注意的是,5 月初芝加哥的气温为 67.22°F,温暖宜人!
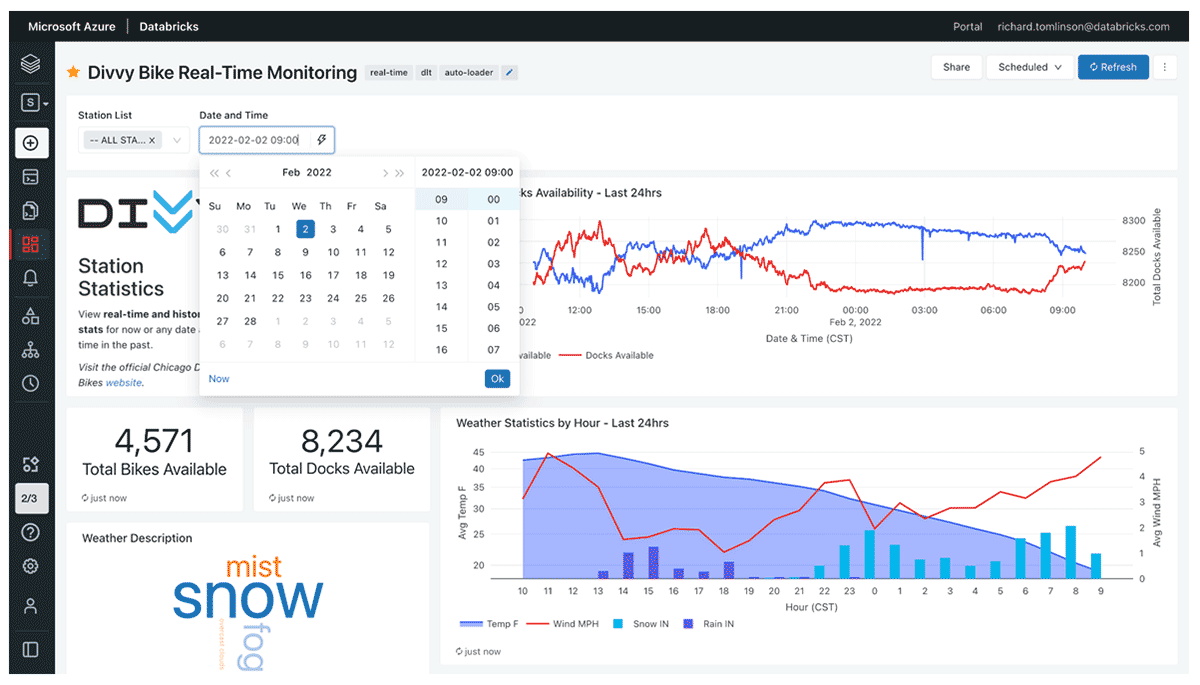
另一个很酷的功能是您可以切换到任何一天、小时和分钟,以查看过去的状态。例如,我可以将“日期和时间”过滤器更改为 2022 年 2 月 2 日上午 9 点(美国中部标准时间),以了解暴风雪期间游乐设施受到的影响。
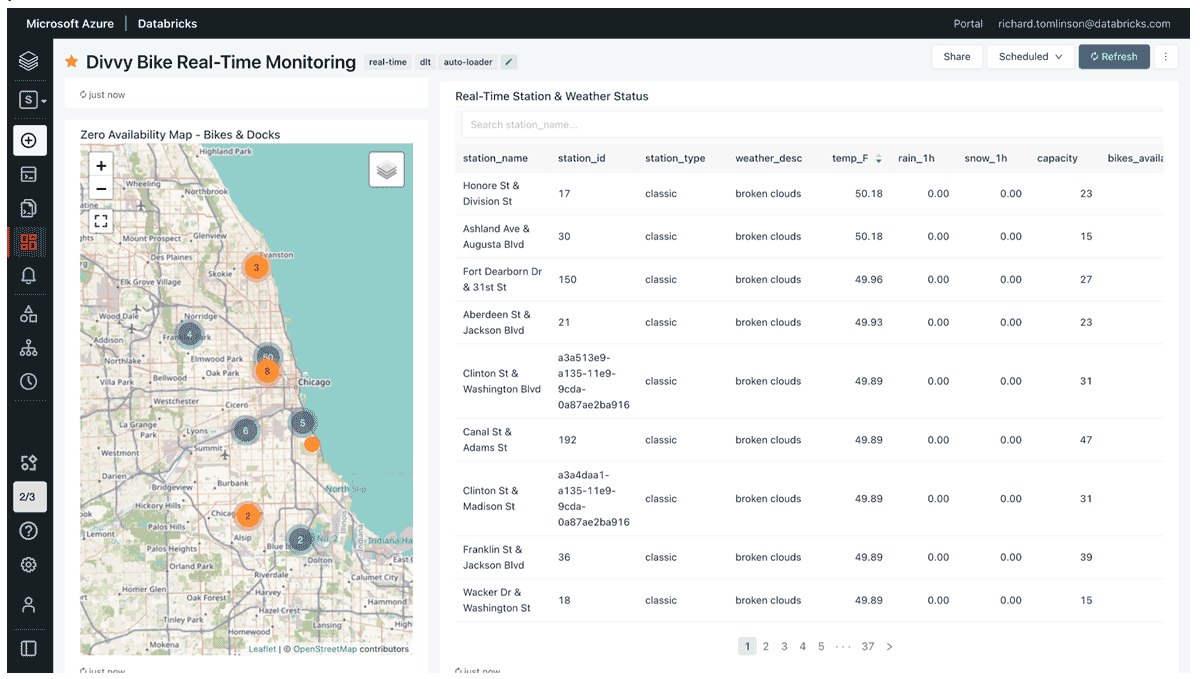
我还可以在地图上实时查看可用性为零的站点,或者查看过去任何日期和时间的站点。
第二个仪表板显示了从首次收集数据到现在的一段时间内的趋势:
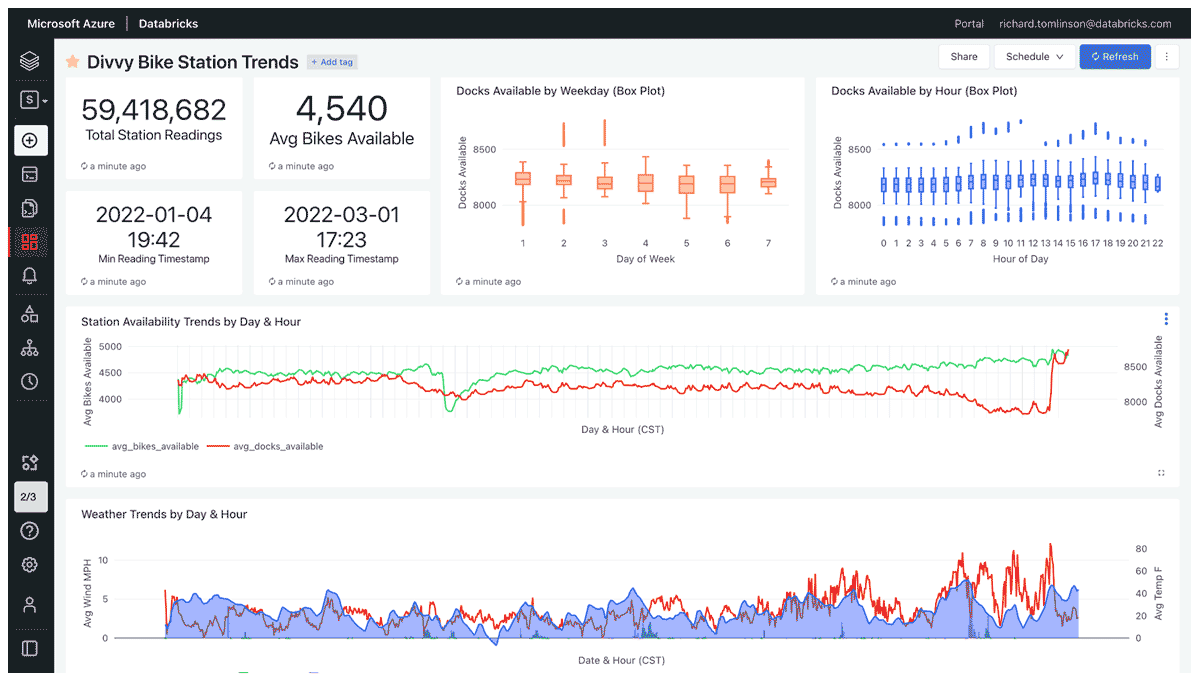
在仪表板查询性能方面,我只能说我还没有觉得有必要在我的奖章架构中创建任何聚合或“黄金”级别的表。SQL 查询性能原样良好。没有查询运行时间超过约 3 秒,大多数运行在一两秒内。
除了 Photon 引擎的出色查询性能之外,DLT 的主要优势之一是它还执行日常维护任务,例如每 24 小时对我的管道表执行一次完整的OPTIMIZE操作,然后执行VACUUM 。这不仅有助于提高查询性能,还可以通过删除不再需要的旧版本表来降低成本。
概括
我已经结束了这部分旅程,这也是我与 Databricks 的第一次旅程。考虑到我之前概述的许多问题,我对到达这里如此简单感到惊讶。我实现了构建具有实时数据的完整端到端分析应用程序的目标,而无需编写任何代码或拿起 batphone 来获得“认真”数据工程师的帮助。
有很多与我有着相似背景和技能的数据和分析专家,我觉得像 Delta Live Tables 这样的产品将真正解锁 Databricks,以吸引更多的数据和分析从业者。它还将通过简化和自动化繁重的操作任务来帮助更复杂的数据工程师,使他们能够专注于他们的核心任务——利用数据进行创新。
如果您想了解有关 Delta Live Tables 的更多信息,请访问我们的网页。在那里,您可以找到电子书、入门技术指南和网络研讨会的链接。您还可以在我们的 YouTube 频道上观看 Divvy Bike 演示的录制演示,并在 Github 上 下载演示资产。
谢谢!
原文标题:How I Built A Streaming Analytics App With SQL and Delta Live Tables
原文作者:Richard Tomlinson
原文地址:https://www.databricks.com/blog/2022/05/19/how-i-built-a-streaming-analytics-app-with-sql-and-delta-live-tables.html
