为了改善特定类型查询的性能,表扩展转换在11gR2时被引入。如果你了解转换是如何工作的,你可以定制索引方案来改善执行计划。我们是基于以下几个关键点而增加了该转换:
- 基于索引的执行计划能显著改善性能。如果你仍不相信,请查阅我们在星形转换中的一个示例。
- 对于DML操作,索引维护会导致额外的开销,这让一些用户避免使用索引。
- 在很多系统中,只有很小的一部分数据是通过DML来主动更新的。
表扩展允许优化器生成在读最多的数据部分使用索引,而在更新活跃的数据部分不使用(索引)的执行计划。因此,DBA可以配置一张表只在读最多的数据部分创建索引,而又不必承担索引在更新活跃的数据部分而带来的开销负担。
这是表扩展所要实现的高级目标。实践中,我们描述数据的活跃和非活跃部分的方法是使用分区。可以在表上定义本地分区索引,并在特定的分区上标记其不可用。索引不可用的分区,在效果上就是没有索引。
分区裁剪和索引访问
为了理解由表扩展生成的执行计划类型,知道一点关于分区裁剪,以及优化器是如何确定访问哪个分区并是如何访问的,是有帮助的。基于查询中出现的谓词,优化器会对每一张表保持需要访问哪些分区的跟踪。让我们看一个简单的示例,它使用了Oracle样例SCHEMA的SH下的SALES表。这个表在TIME_ID上做了范围分区,请看查询Q1,它在该列上有一个过滤:
Q1
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38;
优化器可以从该过滤中确定,表上28个分区中,只有16个是需要访问的。我们可以在执行计划的“Pstart”和“Pstop”列上看到这一点:
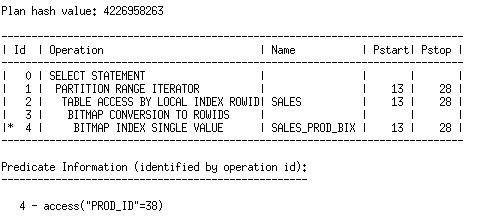
一旦优化确定了哪些分区要被访问,就会考虑所有这些分区上任何可用的索引。在上面的执行计划中,优化器选择使用了SALES_PROD_BIX索引。让我们看一下,如果我们禁用SALES表上一个分区的索引,会发生什么。
alter index SALES_PROD_BIX modify partition SALES_1995 unusable;
这会禁用掉在第一个分区(分区1)上的索引,其包含有所有1996年之前的销售数据。这些信息可以在USER_IND_PARTITIONS中找到。
如果我们再次为Q1生成执行计划,我们看到我们得到了同样的执行计划:
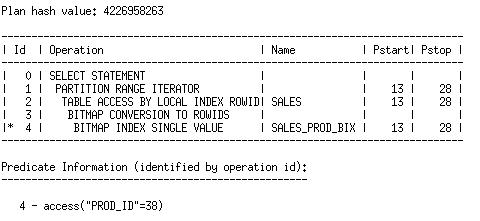
这是因为我们所去掉的索引分区,和我们的查询是不相关的。只要我们所要访问的分区是有索引的,我们就可以用索引来回答该查询。因为我们仅需访问分区16(译者注,应为分区13)到28,关掉在分区1上的索引,并不影响该执行计划。
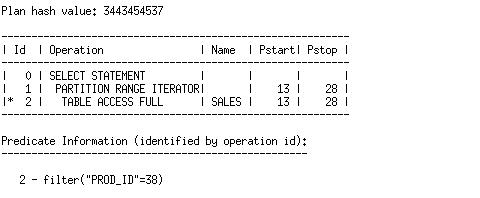
如果我们禁用在我们需要访问的分区上的索引,我们就不能再使用那个索引了(无表扩展时)。例如,让我们看一下我们禁用了分区28(SALES_Q4_2003)上的索引后的执行计划。回想一下,这是我们在查询中需要访问的分区之一。
alter index SALES_PROD_BIX modify partition SALES_Q4_2003 unusable;
表扩展是如何帮助我们的
在上例中,我们的查询访问了16个分区。这些分区中的15个的索引是可用的,但是在最后的分区上是无索引可用的。由于优化器必须要选择一个访问路径,或者其它的一个,因此,我们不能使用任何分区上的索引。而这正是表扩展所要解决的问题。表扩展允许优化器通过在不同的查询块来访问,来分别优化有索引的和没有索引的分区。上面的查询可以被重写为如下:
Q2
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND time_id < TO_DATE(' 2003-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38
UNION ALL
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND time_id >= TO_DATE(' 2003-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38;
在UNION ALL的第一个查询块中,访问了那些具有索引的分区,而第二个查询块则访问了无索引的分区。(译者注:在第二个查询块中有两处对TIME_ID均为>=的条件,只有更严格的第二个会被采用,同时,其比较操作符是>=,而在第一个查询块中,其比较操作符是<)这允许优化器在第一个查询块中选择使用索引,如果这比在被访问的分区上使用表扫描更优的话。以下是表扩展启用后的执行计划:
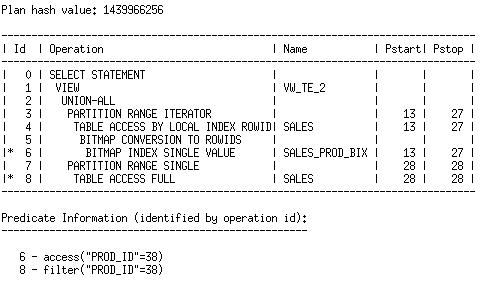
single-table-table-exp.JPG
通过表扩展,优化器可以为分区选择可用的,更有效的访问方法, 而不管这个方法对于查询块中访问的所有分区是否适用。优化器也可以跨UNION-ALL查询块分支,选择不同的连接方法,连接顺序等。
更有意思的一个例子
在近期的博文星形转换中,我们讨论了星形转换的优点。星形转换对于某些类型的查询来说是一个巨大的胜利,因为它允许我们避免访问大的事实表的大部分。唯一的缺点是它需要定义若干个索引。在更新活跃的表中,这可能会产生一些开销。在过去,这吓住了一些用户,不敢创建触发星形转换所需的索引。通过表扩展,您可以选择只在非活跃分区上定义这些索引,优化器可以考虑对具有索引的部分表进行星形转换。
考虑这个来自于星形转换博文,并做了少许修改的查询:
Q3
SELECT t.calendar_quarter_desc, SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc = 'Internet'
AND t.calendar_quarter_desc IN ('1999-01','1999-02')
GROUP BY t.calendar_quarter_desc;
假设SALES表的最后一个分区是更新活跃的(就像是经常遇到的,使用时间分区的情况)。我们禁用了最后一分区上的索引。
alter index SALES_CHANNEL_BIX modify partition SALES_Q4_2003 unusable;
alter index SALES_CUST_BIX modify partition SALES_Q4_2003 unusable;
优化器选择了表扩展,并且UNION-ALL分支使用星形转换,访问了除最后一个分区之外的所有分区。最后一个分区通过表扫描进行访问。
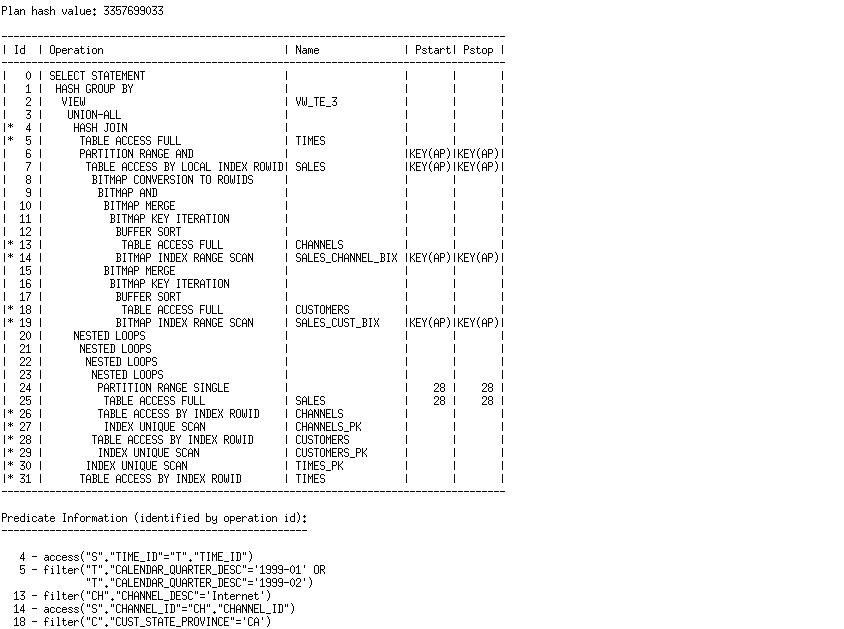
何时表扩展不被采用
当一张表及其索引被用这样的方式配置时,我们也不总是采用表扩展。首先,表扩展是基于成本的,因为它并不总是最优的。虽然扩展表的每个分区都只访问一次(跨越union-all的所有分支),但连接到它的任何表在每个分支中都要被访问。我们在最近关于OR扩展的博文中讨论了这个问题,OR扩展在生成的查询形状及其作用的限制方面,与表扩展非常相似。
例如,上面的星形转换例子是对原始博文中的查询略做了修改,因为对于原始查询使用表扩展并不划算。因为回连到customer表的连接(因为需要在SELECT和GROUP BY子句中出现的列)过于昂贵。两个分支重复连接到该表,比对整张表使用非星形转换的执行计划更昂贵。在这个案例,连接因式分解可以改善表扩展的执行计划。我们将在未来几个月的博文中讨论查询转换之间的相互作用。
还有若干个语义方面的原因, 使得像这样扩展表可能是无效的。例如,对出现在外连接右侧的表进行扩展是无效的。
该转换可以被提示EXPAND_TABLE(
)所控制。比如,对于Q3示例,提示EXPAND_TABLE(s)将覆盖基于成本的决定,但不包括语义检查。
总结
表扩展允许用户对于有高的更新量的表,利用上基于索引的执行计划。用户可以仅在较旧的,读最多的数据上定义索引,并且优化器会考虑使用索引,哪怕被访问的部分数据上是没有索引的。
原文链接:https://blogs.oracle.com/optimizer/post/optimizer-transformations-table-expansion
Optimizer Transformations: Table Expansion
January 1, 2020 | 6 minute read
Maria Colgan
Distinguished Product Manager
The table expansion transformation was introduced in 11gR2, to improve performance of a specific category of queries. If you understand how the transformation works, you can tailor your indexing scheme to improve plans. We added the transformation based on a few key observations:
- Index-based plans can improve performance dramatically. If you don’t already believe that, check out our post on star transformation for one example.
- Index maintenance causes overhead to DML, which causes some customers to avoid indexes.
- In many systems, only a small portion of the data is actively updated via DMLs.
Table expansion allows the optimizer to generate a plan that uses indexes on the read-mostly portion of the data, but not on the active portion of the data. Hence, DBAs can configure a table so that an index is only created on the read-mostly portion of the data, and will not suffer the overhead burden of index maintenance on the active portions of the data.
This is the high-level idea of what table expansion does. In practice, the way we can delineate active and inactive portions of the data is using partitioning. A local index can be defined on a table, and marked unusable for certain partitions. The partitions for which the index is unusable are in effect not indexed.
Partition Pruning and Index Access
In order to understand the kinds of plans generated by table expansion, it helps to know a bit about partition pruning, and how the optimizer decides what partitions to access and how. The optimizer keeps track of what partitions need to be accessed from each table, based on predicates that appear in the query. Let’s look at a simple example, using the SALES table from the Oracle sample schema SH. This table is range partitioned on TIME_ID. Consider query Q1, which has a filter on that column.
Q1
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38;
The optimizer can determine from that filter that only 16 of the 28 partitions in the table need to be accessed. We see this in the “Pstart” and “Pstop” columns of the plan:
Once the optimizer has determined which partitions will be accessed, it will consider any index that is usable on all of those partitions. In the plan above, the optimizer chose to use an index, SALES_PROD_BIX. Let’s see what happens to the plan for Q1 if we disable the index on a partition of the SALES table.
alter index SALES_PROD_BIX modify partition SALES_1995 unusable;
This disables the index on the first partition (partition 1), which contains all sales from before 1996. Note that you can find this information in USER_IND_PARTITIONS.
If we generate the plan for Q1 again, we see that we get the same plan.
This is because the index partition that we removed is not relevant to our query. As long as all of the partitions we access are indexed, we can answer the query with the index. Since we only access partitions 16 through 28, disabling the index on partition 1 does not affect the plan.
If we disable the index on a partition that we do need to access, we can no longer use that index (absent table expansion). For instance, let’s look at the plan after we disable the index for partition 28 (SALES_Q4_2003). Recall from the above plans that this is one of the partitions that we do access in the query.
alter index SALES_PROD_BIX modify partition SALES_Q4_2003 unusable;
How Table Expansion Can Help
In the above example, our query accesses 16 partitions. On 15 of those partitions, there is an index available, but there is no index available for the final partition. Since the optimizer has to choose one access path or the other, we cannot make use of the index on any of the partitions. This is what table expansion is meant to solve. Table expansion allows the optimizer to optimize the partitions that are indexed separately from those which are not, by accessing each in a separate query block. The above query can be rewritten as follows:
Q2
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND time_id < TO_DATE(' 2003-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38
UNION ALL
SELECT *
FROM sales
WHERE time_id >= TO_DATE('2000-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND time_id >= TO_DATE(' 2003-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
AND prod_id = 38;
The first query block in the union all accesses the partitions that are indexed, while the second query block accesses the partition which is not. This allows the optimizer to choose to use the index in the first query block, if that is more optimal than using a table scan of all of the partitions that are accessed. Here is the plan with table expansion enabled:
single-table-table-exp.JPG
With table expansion, the optimizer can choose the most efficient access method available for a partition, whether it exists for all of the partitions accessed in the query or not. The optimizer may also choose different join methods, join orders, etc. across the branches of the union-all query block.
A More Interesting Example
In a recent post, we discussed the virtues of star transformation. Star transformation can be a huge win for certain kinds of queries, since it allows us to avoid accessing large portions of big fact tables. The only downside is that it requires defining several indexes. In an actively updated table, this can have some overhead. In the past, this has scared some users away from creating the indexes necessary to trigger star transformation. With table expansion, you have the option of defining these indexes on just the inactive partitions, and the optimizer can consider star transformation on the indexed portions of the table.
Consider a slightly modified version of the query from the star transformation post:
Q3
SELECT t.calendar_quarter_desc, SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc = 'Internet'
AND t.calendar_quarter_desc IN ('1999-01','1999-02')
GROUP BY t.calendar_quarter_desc;
Suppose the last partition of SALES is actively being updated (as is often the case with time-partitioned tables). So we disable the indexes on the last partition:
alter index SALES_CUST_BIX modify partition SALES_Q4_2003 unusable;
The optimizer chooses table expansion, and the union-all branch accessing all but the last partition uses star transformation. The final partition is accessed via a table scan.
When Table Expansion Is Not Chosen
We will not always choose table expansion when a table and its indexes are setup this way. First, table expansion is cost-based, since it is not always optimal. While the partitions of the expanded table are each accessed only once (across all branches of the union-all), any tables that are joined to it will be accessed in each branch. We discussed this concern in our recent post on OR-expansion, which is quite similar to table expansion in terms of the query shape that is generated, and the restrictions on its usefulness.
For example, the star transformation example above was slightly modified from the query in the original post, because for the original query it is not cost-effective to use table expansion. The join back to customers (required due to a column from that table appearing in the SELECT and GROUP BY clauses) is so expensive that repeating the join to that table in both branches is more expensive than using the non-star transformation plan for the entire table. Join factorization may improve the table expansion plan in this case. We’ll discuss this interaction between transformations in a post in the next few months.
There are also several semantic reasons that it may not be valid to expand a table in this manner. For instance, a table appearing on the right side of an outer join is not valid to expand.
The transformation can be controlled with the hint EXPAND_TABLE(
), e.g. EXPAND_TABLE(s) for Q3. The hint will override the cost-based decision, but not the semantic checks.
Summary
Table expansion allows users to take advantage of index-based plans for tables that may have high update volume. Users can define an index scheme where only older, read-mostly data are indexed, and the optimizer will consider using the index even when some of the data accessed are not indexed.
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





