




- 时间:9月17日 14:00-17:00
- 地点:广州市天河区花城大道 770 号珠光·NT 空间 2楼企业活动厅
- 议题:国产分布式数据库 OceanBase 核心能力解读和支付宝实践
- 报名地址:https://survey.aliyun.com/apps/zhiliao/-NasGL9m3?&_use_mobile=true
在广州的小伙伴一起面基呀!!!
活动详情查看下方海报

成都站精彩内容回顾
数据库架构发展史
自20世纪60年代数据库系统诞生以来,其架构在企业成本、技术、业务需求等因素的驱动下不断变化。纵观数据库系统架构发展的这几十年,我们可以把它分为三个阶段(如图1)。
第一阶段:集中式+集群数据库架构。
第二阶段:基于中间件+数据库的分布式数据库。
第三阶段:基于多副本架构的原生分布式数据库。
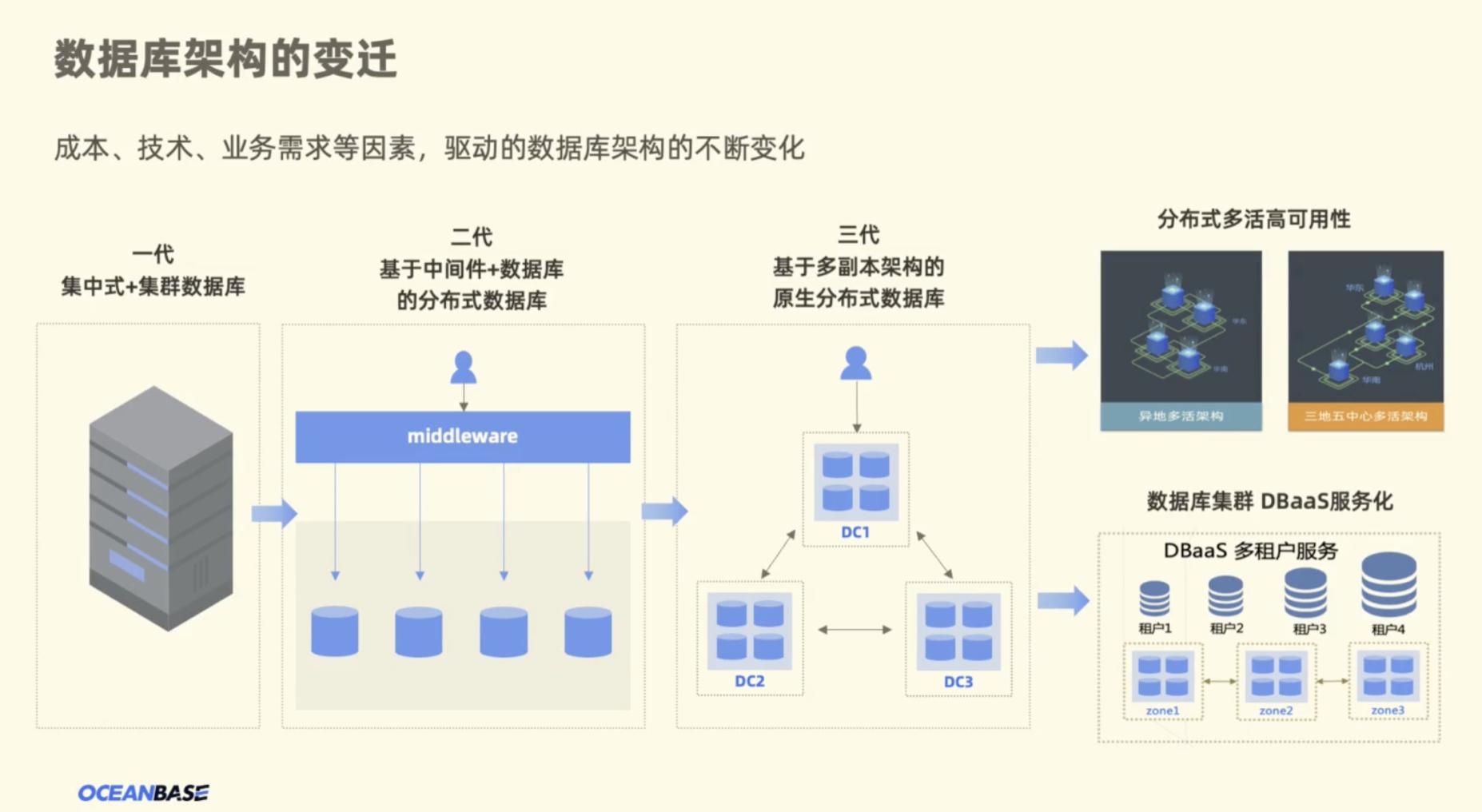
集中式+集群数据库的架构以 Oracle 为例,其典型特点是:高昂的 License 费用、依赖于高端的硬件存储。同时, Oracle 作为商业数据库,由于政治、经济等特殊原因可能会对使用该数据库的别国企业带来“卡脖子”风险。因此,越来越多的公司开始使用 MySQL 或 PostgreSQL 等基于中间件+数据库的开源分布式环境。
基于中间件+数据库的分布式数据库的一大作用是,单机存储容量通过中间件得到了释放。但与此同时,会引入一些新的问题,如全局唯一性、多表交易操作,此外,在企业没有一定的运营平台或运营能力时,做 DDL操作也会带来一些挑战。由于基于中间件+数据库的分布式数据库对业务并不透明,企业原有的数据库架构无法直接切换到中间件+数据库的架构下,导致架构迁移时需要对业务层进行改造,不仅增加了额外的改造成本,还可能影响业务正常运行。
基于多副本架构的原生分布式数据库拥有多个副本,数据均匀的打散在多个副本中,且每个副本中都有完整的用户数据,也带来了灵活扩缩容到特点。企业无需依赖越用越贵的硬件存储,也无需对业务层进行改造,增加成本与复杂性,避免了从架构、成本、业务等方面对企业不友好的问题。
无论是哪种数据库的架构,企业在做选型时,其目的都离不开“降本增效”,希望能通过技术的提升,带来效益的提升与成本的下降。那么,一套数据库系统可以从哪些方面实现“降本增效”呢?
数据库助力企业降本增效的要点
企业的降本增效主要依赖于数据库系统弹性扩缩容的能力、HTAP 能力、数据压缩能力,以及原生分布式的高可用、高性能、高兼容。通过上述能力结合完善的周边工具来降低企业的人力、财力及时间成本,进而打造一个用起来简单稳定、快速响应的数据库系统。
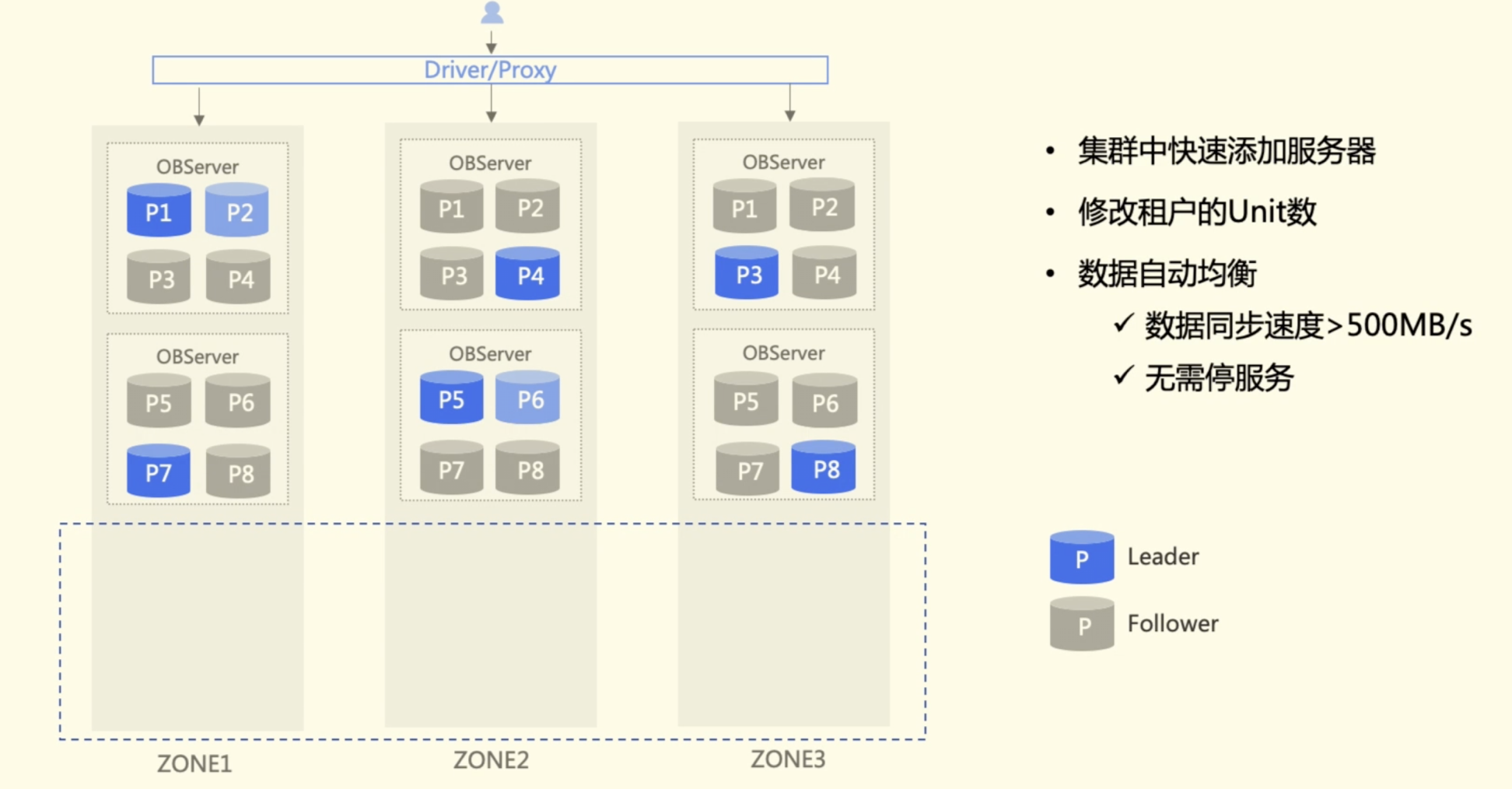
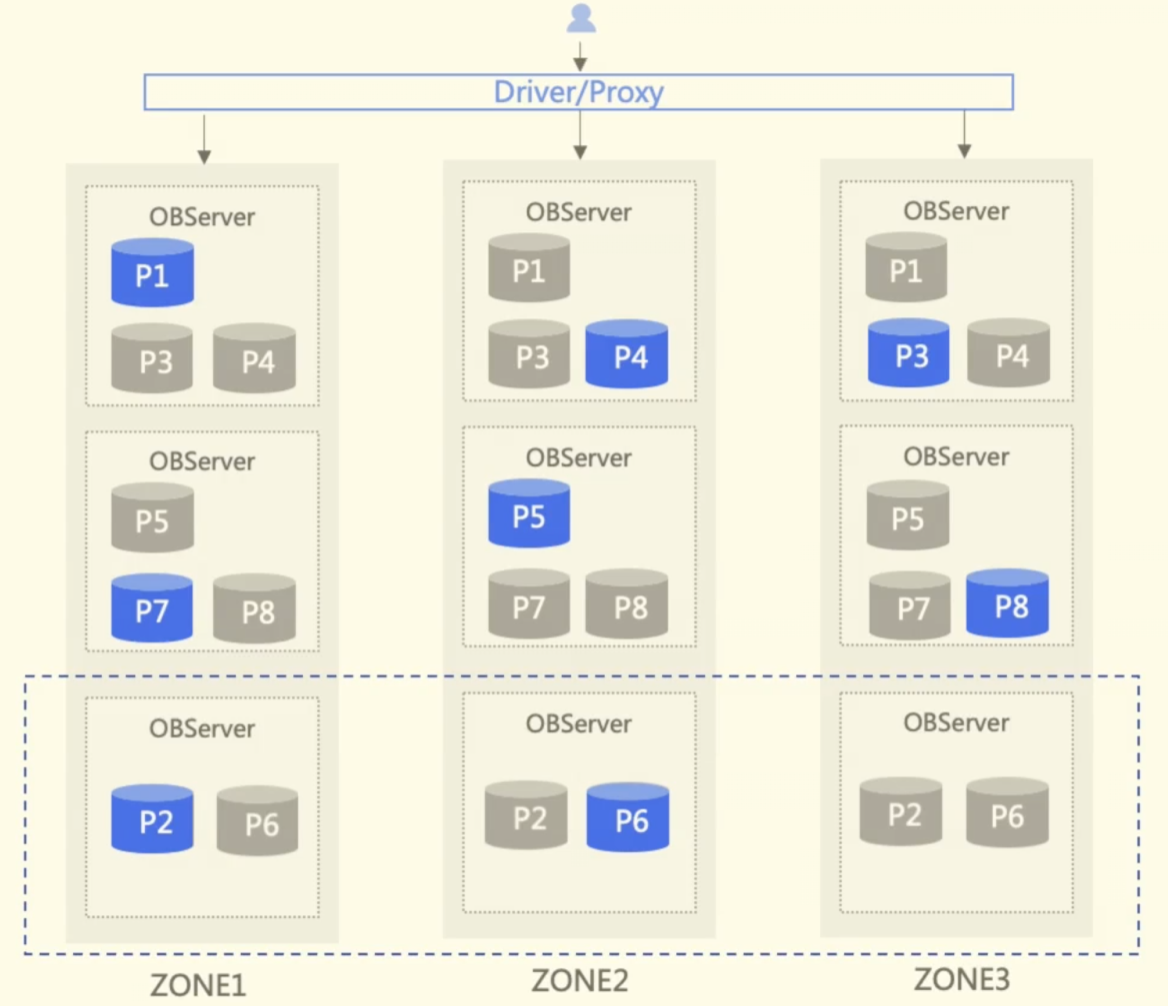
每种数据库都有一定的扩缩容能力,以 OceanBase 为例,OceanBase 会将所有的用户数据分散在副本中,保证每个副本都有一份完整的用户数据。从图2可见,该架构中有三个副本,每个副本中有 2 个 OBServer包含八个分区,蓝色圆柱体代表分区的 Leader 。正常的读写都在Leader 上进行,当算力或存储出现瓶颈时,可以给每个副本添加一个 OBServer,在添加之后,数据库内部会进行自动负载均衡调度,可以将 P2 或 P6 分别调到新加的节点上(如图3),不需要额外的修改路由策略。
在 OceanBase 中有一种理念:真正的 HTAP 在一套引擎中既支持 AP 负载又支持 TP 负载。为了避免 AP 业务对 TP 业务造成影响,将 AP 和 TP 业务从资源侧进行隔离。在一套系统中,如果同时包含了 AP 和 TP ,可以在一定程度上减少企业重复性建设的成本。在这里也需要说明一点:由于 AP 系统在一些特定的场景下,有自己的使用场景,因此,HTAP 能力并不能完全替代 AP 的系统。
-
数据压缩能力
LSM-Tree 会将离散且随机的数据写入请求中再转化成批量的顺序请求,可以减少随机写。一般 B-Tree 架构在写作时,是一个实时刷盘的过程。而 LSM-Tree 是将实时写转换成一步写。传统的数据库有压缩功能,但在日常使用的过程中,你可能也会很少见到数据库的压缩功能,这是因为:
- 传统的数据库有定常块。当你在做数据压缩后,如果没有达到定常块就需要进行数据补齐。
- 原地更新。原地更新的成本较高。
- 传统的数据库是实时写入的。在 LSM-Tree 架构中,实时写入且需要压缩的时候,对 CPU 资源的消耗较高。
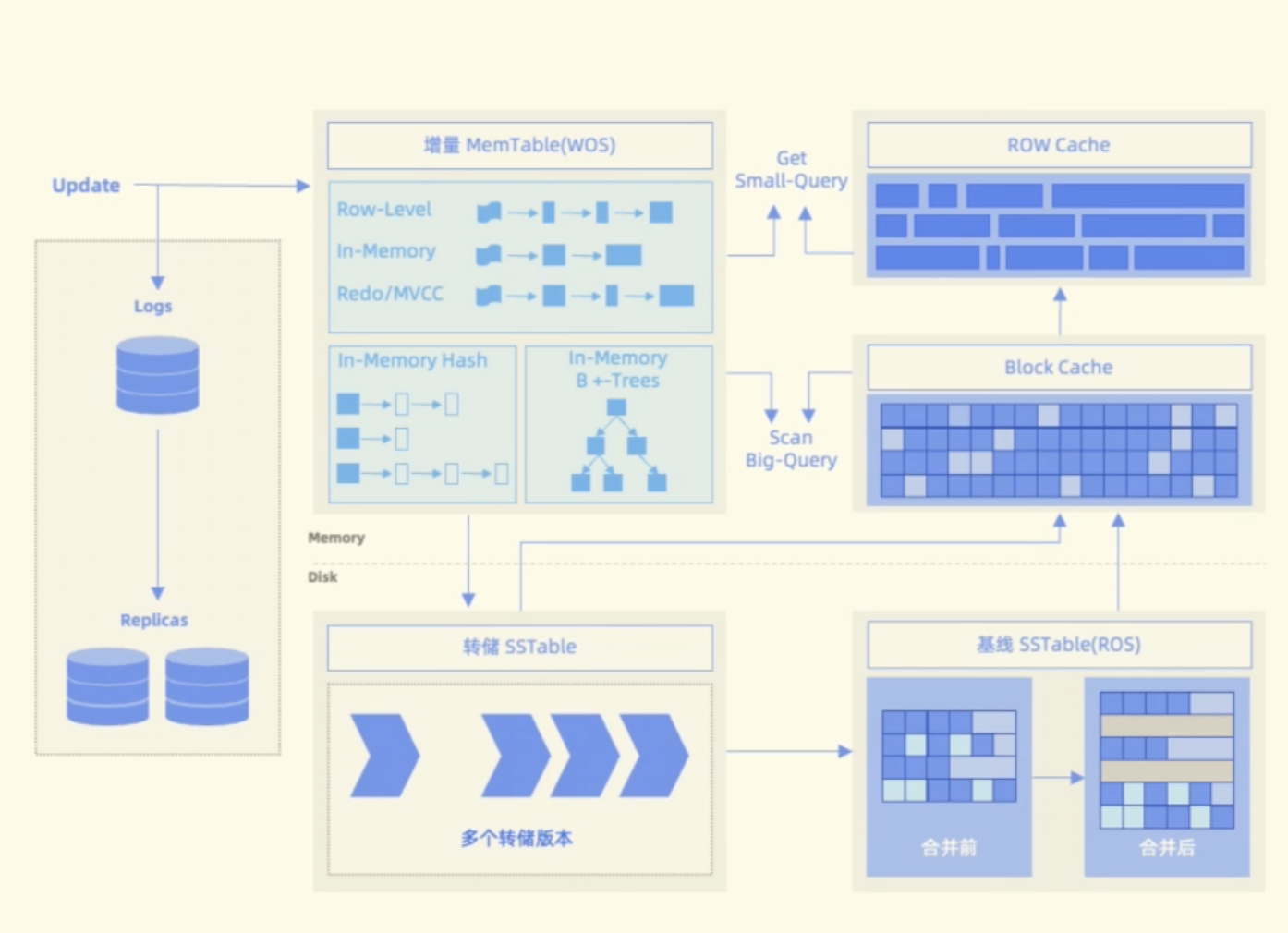
OceanBase 数据库的存储引擎基于 LSM Tree 架构,将数据分为静态基线数据(放在 SSTable 中)和动态增量数据(放在 MemTable 中)两部分,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;MemTable 支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 SSTable。在进行查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。同时在内存实现了 Block Cache 和 Row cache,来避免对基线数据的随机读。
图 5 是某用户生产环境真实的数据,从图中可以看出从其他数据库迁移到 OceanBase 后,依赖良好的压缩率,存储成本收益显著。这里很多人就会好奇,为什么 OceanBase 及 LSM-Tree 架构可以开启压缩功能?在 OceanBase 中所有的压缩都是在合并阶段进行的。在合并 SSTable 静态数据时,由于在OceanBase 的SSTable 粒度更小:由定长的宏块组成大小为2MB,宏块的内部是由若干个变长的微块组成,变长也是很好压缩的,而且在不影响性能的同时做到高压缩比。在OceanBase 现有的业务中,当客户将 MySQL 迁移至 OceanBase 后,迁移前在 MySQL 中数据量为 1TB,迁移后可能只有 300~400 GB,压缩到原数据量1/3或1/4左右。

-
原生分布式的高可用、高性能、高兼容能力
每一种数据库都提供了高可用能力,而OceanBase 是基于 Paxos 协议来实现三副本部署模式,原生数据自带强一致性,具备高可用,达到最高级别的容灾恢复能力的要求:RTO小于30秒,RTO等于0。在 OceanBase 中有很多部署模式,可以提供不同级别的容灾,比如:单机故障、机房级别融灾、城市级故障,可以保障自动故障切换,不停服,不丢数据。
当你有一套数据库系统需要迁移到基于多副本架构的原生分布式数据库如 OceanBase 时,你会需要了解 OceanBase 的兼容程度如何?以 MySQL 为例,OceanBase 社区版目前可以兼容 MySQL5.6、5.7绝大多数语法,也可以兼容 MySQL 8.0新特性 CTE。在我们使用 MySQL 时常用的工具有 Navicat、dbeaver、datax、canal等,这些第三方工具做到了与OceanBase 良好适配。正因具备高兼容性的因素,你就可以平滑地从 MySQL 迁移到 OceanBase。
-
完善的周边工具
一款数据库系统具备多种能力后,还需于完善的生态工具配合,才能助力企业降本增效。对于 OceanBase 而言,其主要的生态工具有:OceanBase 数据库迁移服务(OMS)、OceanBase 运维管理平台(OCP)、OceanBase 开发者工具(ODC)。
-
OMS是 OceanBase 提供的一站式数据传输产品,支持多种关系型数据库、大数据(OLAP)及消息队列等数据终端与 OceanBase 之间的数据复制,是一种集数据迁移、实时数据同步和增量数据订阅于一体的数据传输服务。
-
OCP是一款为 OceanBase 数据库集群量身打造的企业级管理平台,兼容 OceanBase 所有主流版本。OCP 提供对 OceanBase 集群的图形化管理能力,包括数据库组件及相关资源的全生命周期管理、监控告警、性能诊断、故障恢复、备份恢复等,协助客户更加高效地管理 OceanBase 数据库,降低企业的IT运维成本和用户的学习成本。
-
ODC作为 OceanBase 数据库量身打造的企业级数据库开发平台,帮助企业安全、高效地使用数据库。还可以通过 ODC 创建和管理数据库中的表、视图等 10 余种数据库对象。基于 WebSQL,ODC 提供了 SQL 窗口和匿名块窗口作为数据库开发者开发和诊断 SQL 和 PL/SQL 的工作区。你还可以为指定角色分配对应资源及该资源的访问权限,企业内不同角色间的开发协作亦会变得简单可控。
总的来说,没有完美的数据库架构,不同架构的数据库对企业降本增效的效果不同,企业用户选择适合自己的架构最重要。上述内容其实都跟我们企业降本增效息息相关,做好其中任何一点,都可以帮助企业降低成本,提升效率。未来,在 OceanBase 4.0版本,还会有更多的功能,将助力企业进一步实现降本增效的目的,简单列举一些:1、AP 能力进一步提升。
4.1 版本支持向量化及部分下压到存储层。
在向量化执行的过程中也可以对执行的列进行解码,降低了投影的开销。
2、存储压缩率更高。
在通用压缩基础上,开放数据编码功能( Encoding),行列混合存储。微块会按列对数据进行编码,编码后的定长数据存储在微块内部的列存区,存储空间进一步压缩。
3、灵活的高可用和容灾能力。
主备集群为客户提供更加灵活的高可用和容灾能力。主集群通过向备集群发送事务日志的方式实现数据同步,从而确保生产集群能够在遇到数据损坏、灾难等情况下仍然可以快速恢复业务。
4、资源隔离更加彻底和灵活。
在已有 CPU、内存隔离的基础上,支持 I/O 隔离。
支持用户级别资源(CPU)隔离。
5、性能进一步优化和提升。
单日志流,增加分区数上限,减少分区带来的额外开销。
6、更加灵活。
支持主键变更等涉及数据腾挪的 Online DDL。
7.迁移和使用更加简单。
在 MySQL 模式下,支持存储过程,在进行业务迁移时不需要对存储过程进行改造,迁移和使用更加方便。
