Mysql数据类型 | mongoimport数据类型 | |
1 | tinyint | int32() |
2 | smallint | int32() |
3 | mediumint | int32() |
4 | integer | int32() |
5 | bigint | int64() |
6 | decimal | decimal() |
7 | float | double() |
8 | double | double() |
9 | char | string() |
10 | varchar | string() |
11 | tinytext | string() |
12 | text | string() |
13 | mediumtext | string() |
14 | longtext | string() |
15 | year | string() |
16 | date | date_oracle(YYYY-MM-DD) |
17 | time | string() |
18 | datetime | date_oracle(YYYY-MM-DD HH24:MI:SS) |
19 | timestamp | date_oracle(YYYY-MM-DD HH24:MI:SS) |
20 | bit | int32() |
mongoimport导入命令需注意以下参数:
--type 指定导入文件的类型,可选值有CSV、TSV、JSON
--fields指定Json文档的字段名
--columnsHaveTypes表示指定每个字段的数据类型,如果加了此选项,field字段后面就要加数据类型,如msisdn.string()
命令示例:
mongoimport--db ring***ne_prod --collection=Di***bt --parseGrace=skipField--fields="ms**dn.string(),r***ame.string(),nic**me.string(),co***ntId.string(),cop***tId.string(),fil***pe.string(),dat***atus.string(),localF***Path.string(),diyTran*****nId.string(),diyFtp***ath.string(),diyFile***at.string(),cre***me.date_oracle(YYYY-MM-DDHH24:MI:SS),lastM****ime.date_oracle(YYYY-MM-DDHH24:MI:SS),sta***e.string(),e***ime.string(),he***Str.string(),dep***onId.string(),act***Id.string(),l***el.string()"--type tsv --file=t_m****bt_info.tsv --numInsertionWorkers=100--columnsHaveTypes
在上面也说过,在Mongodb中的表(集合)上没有严格的结构定义,所以字段数据没有NULL的概念,如果该字段值数据为NULL,则直接就不需要这个字段。而在mysqldump的时候,如果数据是NULL,则导出的文本文件就会出现NULL,导入后会呈现如下情况:
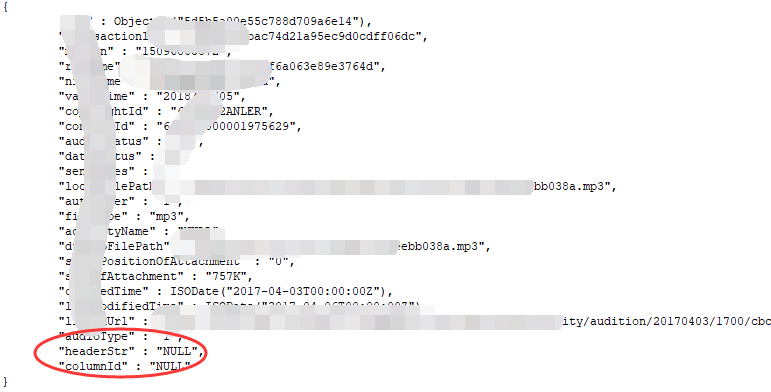
此时,建议导出的时候使用selectifnull(column_name,’’)****intooutfile的形式进行导出;在使用mongoimport导入是指定参数--ignoreBlanks,这样导入的json文档就不会存在null的字段。如果大批量的表数据迁移,则使用selectinto outfile比较麻烦,可以考虑使用shell脚本对原始文本文件进行全量的Null替换,然后再导入。
另外在生产中,Mysql数据中可能存在以字符串形式保存的Json文档,在Mongodb中,这种Json文档建议以子文档的形式存储入数据库中,此时使用mongoimport就不能满足需求,此时可以考虑使用python对文本数据进行转换后写入mongodb。