




gaussdb才用线程池模型,高并发连接切换代价小、内存损耗小,执行效率高,一万并发连接比最优性能损耗<5%。采用增量Checkpoint机制,可以 “小批快跑”,实现性能波动<5%
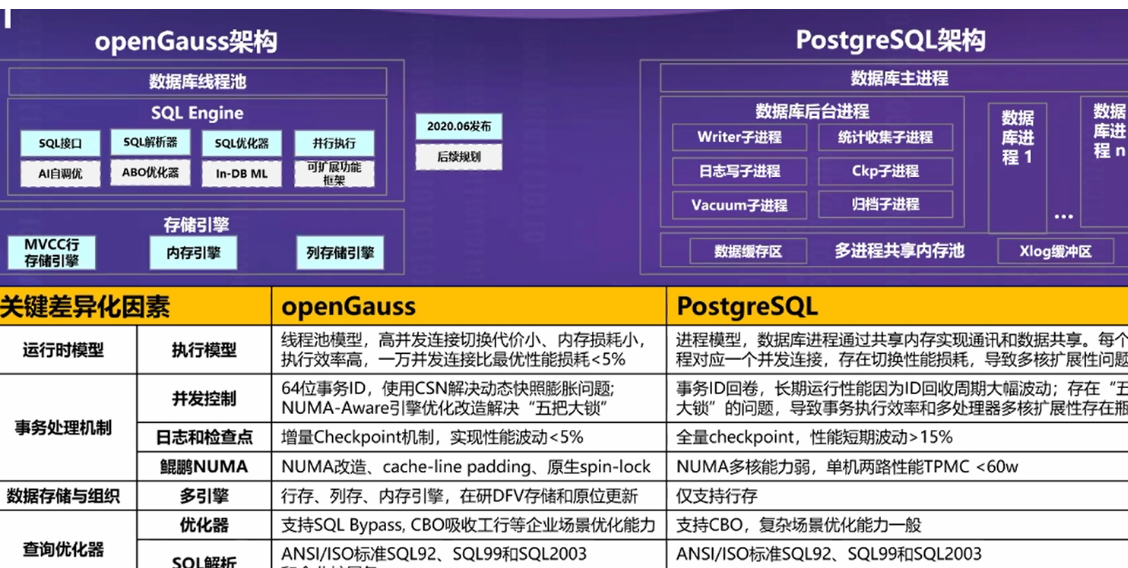
主要流程:
1、启动流程
2、业务处理流程
3、检查点流程
4、归档流程
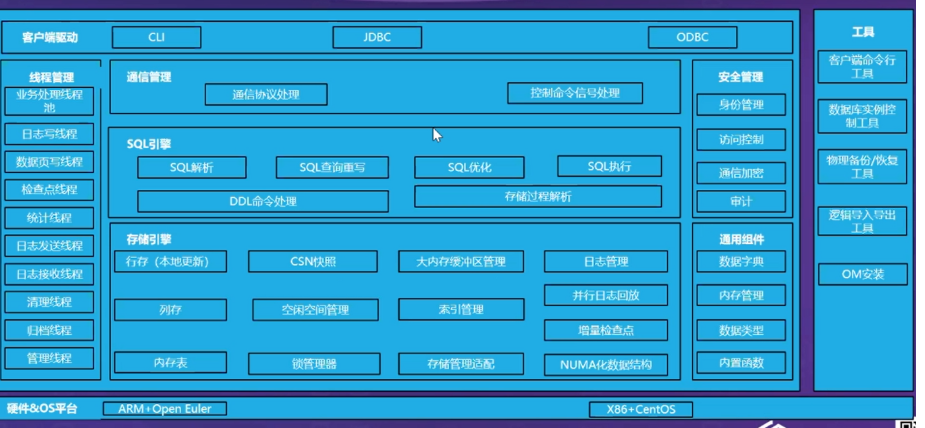
SQL查询语句解析的解析器(parser)阶段包括如下:
(1)词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,每个词确定自己固有的词性。
(2)语法分析:根据SQL语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的语法树(Abstract Synatax Tree,AST)。
(3)语义分析:对语法树(AST)进行检查与分析,检查AST中对应的表、列、函数、表达式是否有对应的元数据(指数据库中定义有关数据特征的数据,用来检索数据库信息)描述,基于分析结果对语法树进行扩充,输出查询树。
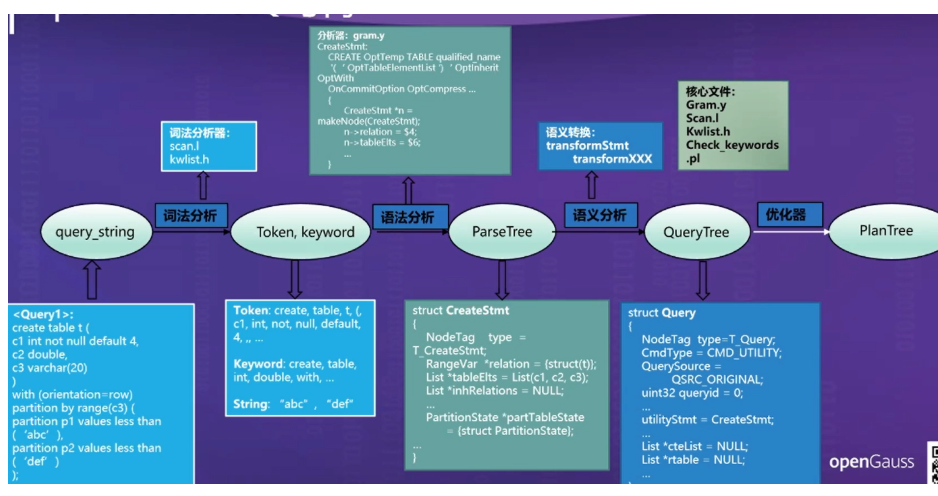
算子是执行树的最基本的运算单元。按照不同的功能,算子划分为如下几种。
1.控制算子 控制算子并不映射代数运算符,而是为使执行器完成一些特殊的流程所引入的
扫描算子负责从底层数据来源抽取数据,数据来源可能来自文件系统,也可能来自网络(分布式查询)。扫描节点(算子在执行树上称为节点)都位于执行树的叶子节点,作为执行数的数据输入来源.
物化算子指算子的处理无法全部在内存中完成,需要进行下盘(即写入磁盘)操作。因为物化算子算法要求,在做物化算子逻辑处理的时候,要求把下层的数据进行缓存处理。因为对于下层算子返回的数据量不可提前预知,所以需要在物化算子算法上考虑数据无法全部放置到内存的情况。
连接算子是为了应对数据库中最常见的连接操作,根据处理算法和数据输入源的不同,连接算子分成以下几种类型
基于操作系统能力,对工作进程进行NUMA绑核,减少跨核访问
Ø 全局数据结构(ProcArray/Buffer/B-Tree等)NUMA分区化改造,减少跨核、跨处理器竞争冲突;
Ø 并发控制原语改造,高并发Spin Lock原子锁效率和临界区代价高2-3倍
Cache line对齐,减少cache miss,提升整体性
内存表、也就是指MOT内存引擎,作为在openGauss中与传统基于磁盘的行存储、列存储并存的一种高性能存储引擎,基于全内存态的数据存储,为openGauss提供了高吞吐的实时数据处理分析能力和极低的事务处理延时,在不同的业务负载场景下,可以达到其他引擎事务处理能力的3~10倍。
内存引擎之所以有较强的事务处理能力,并不是简单地因为它是基于内存而非磁盘,更多的是因为它的索引结构以及整体的数据组织都是基于Masstree模型实现的,Masstree架构的乐观并发控制和高效的缓存块利用率使得openGauss可以全面地利用内存中可以实现的无锁化数据及索引结构、高效的数据管控、基于NUMA架构的内存管控、优化的数据处理算法及事务管理机制等。
需要注意的是,全内存态存储并不代表着内存引擎中处理的数据会因为系统故障而丢失,相反,内存引擎有着与openGauss的原有机制相兼容的并行持久化、检查点能力(CALC逻辑一致性异步检查点),使得内存引擎有着与其他存储引擎相同的容灾能力以及主备副本带来的高可靠能力。
openGauss还将引入全程加密技术,数据在客户端进行加密后进入服务端,服务端基于密文场景,对密文进行查询和检索。并且,openGauss将构建基于可信硬件的可信计算能力,在可信硬件中,完成对数据的解密和计算,计算完毕后再加密返回,构成完整的openGauss全程加密方案架构。
