【笔记】数据库技术与机器学习深度融合的思考和实践
主讲人:王宏志

机器学习驱动的数据库技术
为什么数据库需要机器学习技术?
人难以了解数据全貌(big data era: increasing data size, complex data type, etc.) 可调式的内容增加 (more complex database system, e.g. lots of parameters that can be tuned) 固有的难解问题 模型操作效率高于数据 (replace some data with models, especially when there are more data)
机器学习驱动数据库技术的方法
代价/工作负载预测 (操作代价的预测、未来工作负载预测后可优化系统) 学习增强算法 (视图选择/存储划分等为NP难问题,机器学习提供求解问题的新途径) 机器学习驱动的查询优化 (查询优化是难的问题,特别是当查询很大的时候,性能受限/准确度下降) 机器学习驱动的索引推荐 (同一组数据可能有多种索引可选,对workload的预测?数据类型/分布的掌握?) 机器学习驱动的存储选择 (对于不同类型数据,即使是同一种模态,都可以有不同的存储选择模式, e.g. 行存储/列存储,图数据:native graph/k-v/relational) 学习索引 (将索引看成是一种预测) ...
机器学习驱动的数据库技术例析
基于强化学习的NOSQL数据库索引选择技术
目的:自适应NoSQL上的动态负载变化,实现自动化配置索引 效果:可以在短时间内自动高效地推荐出适合于当前工作负载变化的最佳索引 解决方案:结合强化学习的DQN和dueling network技术建立深度神经网络模型,提出一种以数据库为环境,以机器学习模型为代理的强化学习结构,通过这种方式逐步训练模型。
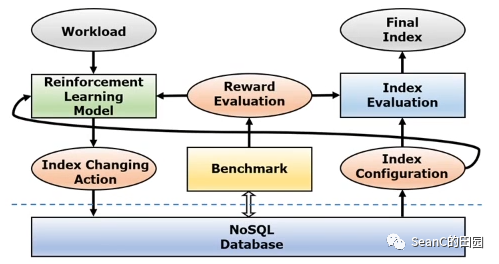
结果:开源测试基准YCSB上,在未训练过的工作负载上,本方法的吞吐量与B-Tree相比可提高3.25%,与Hash相比可提高3.19%,与LSM-Tree相比可提高20.15%,表明了深度强化学习方法在索引选择上的有效性。
基于卷积神经网络的索引推荐 (General Model for Index Recommendation based on Convolutional Neural Networks)
目的:解决工作负载频繁变化情况下,DBA调整索引结构费时费力 效果:在文档数据库上的实验结果表明,基于卷及神经网络的索引推荐明显优于no-index和random-index 解决方案:将索引推荐问题转化为一个细粒度的多分类问题,输入是数据和工作负载,输出是索引类型。设计了分层抽样来减少数据的规模,将数据编码为向量,设计了多核卷积神经网络来更加细致地提取数据的特征 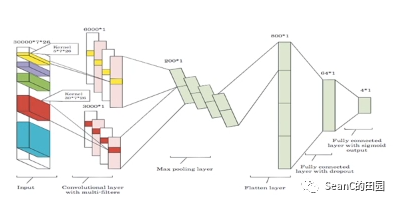
结果:使用两组同分布的数据集和工作负载对模型进行了测试,实验结果表明基于细粒度卷积神经网络的方法能够正确捕捉到数据的特征,高效推荐出索引。
基于Seq2Seq模型的SparQL查询预测
目的:实现高效、跨数据源可用的SPARQL查询预测 效果:利用序列模型进行查询预测,有效提高了查询的缓存命中率 解决方案:以信息完备性、还原性、泛化能力为原则,将三元组视为整体,查询视为一个序列,以位置信息表达三元组,对三元组使用等价类划分。使用seq2seq的模型进行序列预测,加入注意力机制对不同时刻的输入添加相应权重,使用集束搜索降低单个时间步预测出错造成的误差
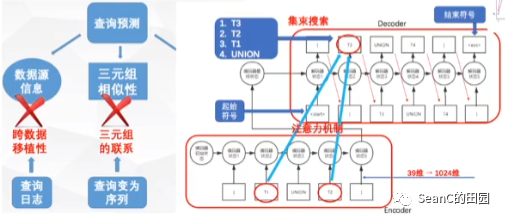
结果:在USEWOD2016数据集上,研究了历史查询个数、训练数据量、注意力机制、集束搜索对预测性能的影响,最后发现在使用注意力机制的情况下,当历史查询个数取3个时预测性能最好,平均缓存百分比可以达到80%。
基于强化学习的RDF图数据分表存储方法 (Efficient RDF Graph Storage based on Reinforcement Learning)
目的:进一步优化大规模RDF图数据的关系数据库存储性能 效果:智能体推荐的存储结构虽然牺牲了一部分空间代价,但是时间开销比现有的基于关系表存储系统大大缩短 解决方案:将强化学习的优化问题转换为马尔科夫决策过程(MDP),结合RDF数据的存储执行过程,定义了MDP的五元组(状态、动作、策略、立即奖励、累积奖励),提出了基于强化学习方法的存储方案。提出了一个将状态、动作特征化的方法,进行数据特征提取,使得不同的表存储状态能够转换为固定长度的向量,便于强化学习算法的处理。提出了基于优先级的查询重写策略,使得立即奖励的计算更加精准,同时也提高了在存储过程中的查询效率。 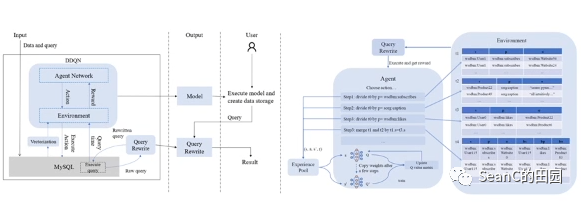
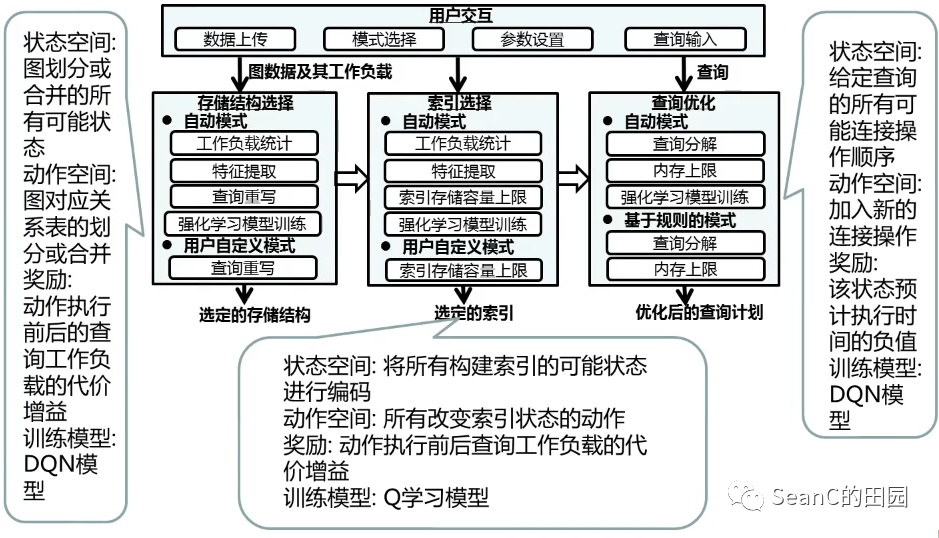
APRIL:基于强化学习的图自动管理 (An Automatic Graph Data Management System Based on Reinforcement Learning)
基于机器学习的文档自动管理
目的:实现文档数据的自动化管理,毫无经验的用户也可以高效管理数据 效果:首次提出了文档数据的自动管理系统,该系统可以自动高效地进行文档数据的管理 解决方案:设计基于机器学习的自动存储方案,实现存储结构的自动选择;设计了基于多核卷积神经网络的自动化索引选择方案 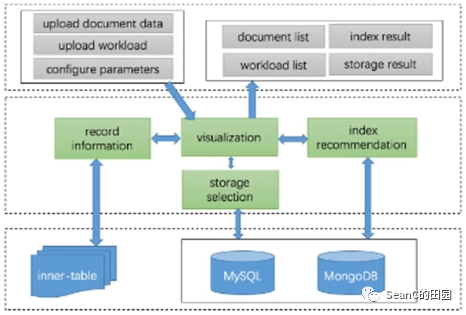
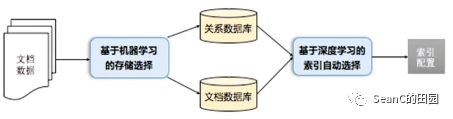
结果:系统非常用户友好地实现了自动化地解析json格式的文档以及工作负载,然后针对该数据集合工作负载推荐最佳的存储方案,继而在该存储方案的基础上给出高效的索引配置
基于系学习代价的存储结构自动选择系统
目的:解决对多引擎数据库下存储引擎的选择问题以及对工作负载的数据布局选择问题 效果:相较于现有技术,可以实现存储结构的充分使用,大大提高工作负载执行效率 解决方案:设计基准测试,对不同存储引擎收集性能数据,并针对不同存储引擎建立性能模型。提出层次聚类技术,判断一个表中不同列间的关联性,并得到列族推荐结果。使用先前得到的性能模型,计算当前负载在不同存储设计下的代价并进行推荐。 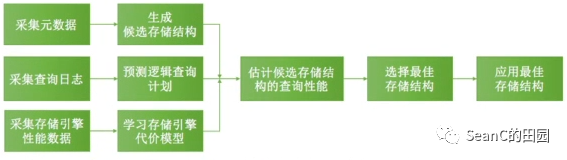
结果:经过四种工作负载(事务型、多事务少分析型、多分析少事务型、分析型)下的测试,我们发现同时推荐数据布局和存储引擎能获得最优的性能;并且数据分区上的工作负载越典型,则得到的存储结构性能越好。
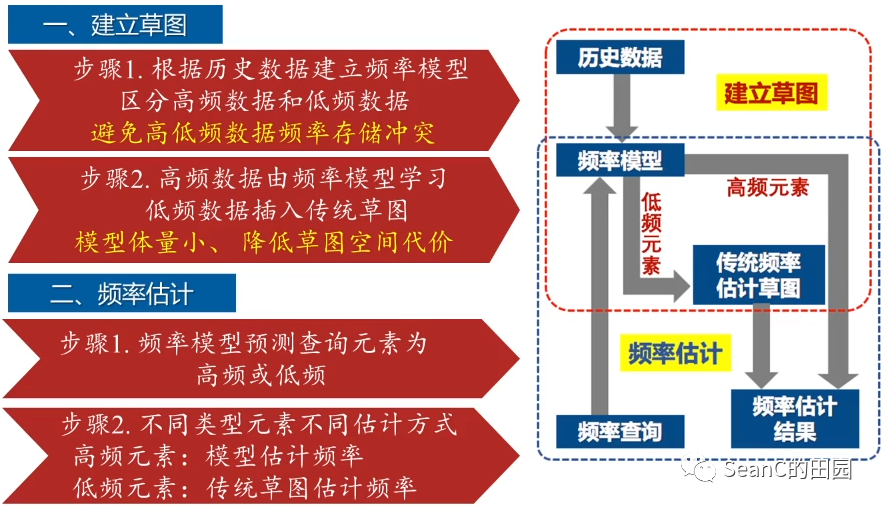
Learned Sketches for Frequency Estimation
思想:将机器学习方法与传统频率估计草图相结合 目的:降低草图的空间代价、提高频率估计准确性
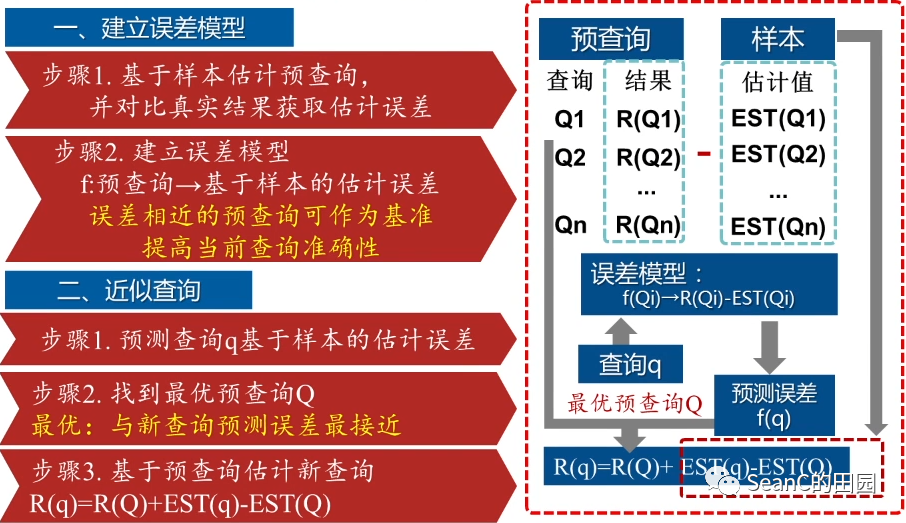
LAQP: Learning-based approximate query processing
思想:将机器学习方法与抽样、预聚集查询相结合 目的:提高近似查询的准确性、降低样本量、提供误差界限
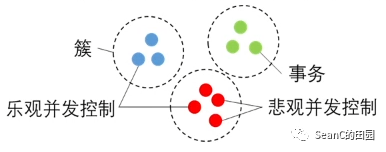
智能数据库事务并发控制算法
目的:突破缓解悲观并发控制算法和乐观并发控制算法的性能瓶颈 效果:利用人工智能技术解决了高冲突型工作负载的并发控制,性能明显优于两种传统算法 解决方案:提出了事务聚类这一新概念以及高效的实现算法,便于有效快速地选择事务之间最佳的隔离方式。提出了基于聚类的并发控制算法,能有效缓解乐观和悲观两种并发控制算法的性能瓶颈。基于马尔科夫模型的事务工作集预测算法用于事务聚类,不同工作负载下预测准确率均在90%以上。
结果:在四种高冲突工作负载(高偏斜读密集,高偏斜写密集,低偏斜读密集,低偏斜写密集)下,新算法的性能明显优于其所基于的悲观并发控制算法和乐观并发控制算法,这说明算法能有效地缓解传统算法的性能瓶颈。
支撑学习的数据库技术
机器学习的演化
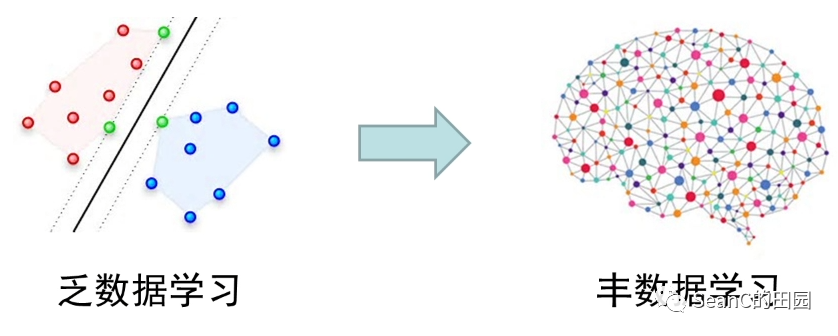
大数据机器学习任务的特点
数据规模大:机器学习任务面向的训练数据海量增长,学习难以在内存中进行 多次迭代,运算复杂多样:涉及大量迭代计算,运算过程非常复杂,任务的优化十分苦难
总结:高效地执行复杂机器学习任务十分困难
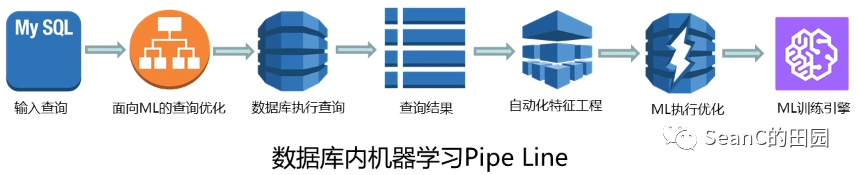
为何要将机器学习放到数据库内?
数据管理困难:机器学习算法的训练效果高度依赖数据规模,但过大的数据规模往往给数据管理带来极大的困难 系统高效的数据管理:使用成熟数据库管理大数据:高效率、高可靠性、高质量 数据传输代价高:训练时需要将数据从数据库内查询并拷贝出来,训练及其难以容纳这些数据的同时,还浪费大量时间在数据传输的过程中,更带来数据泄露的隐患 数据始终在数据库内部:训练时无需拷贝数据到数据库外部,查询结束后可以在数据库系统内直接进行训练,高效且安全性更高 难以设计高效的训练pipeline:从数据库内查询数据涉及join等昂贵的外存操作,由于训练机器的存储空间限制、网络传输速率限制等因素,常常会出现训练进程等待数据的情况 易于机器学习全流程的管理:便于利用数据库进行数据管理、模型管理,利用数据库的任务调度能力管理训练pipeline,减少训练gap
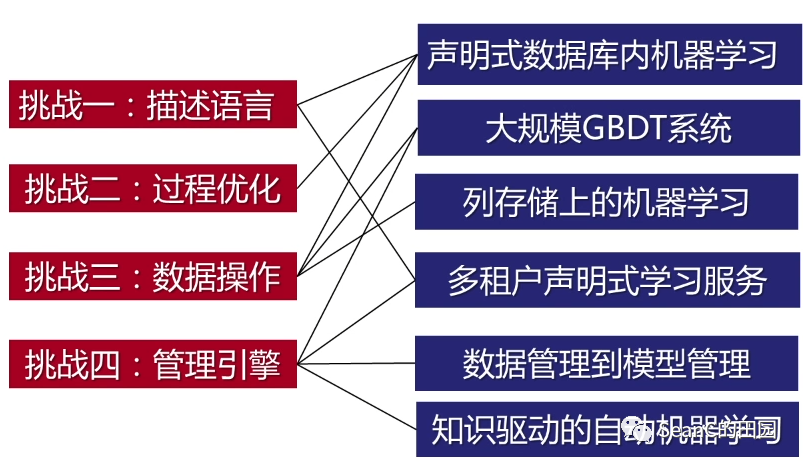
数据库内机器学习的挑战一
如何设计完备的声明式语言模型 面向机器学习的声明式语言、声明式语言的完备性
数据库内机器学习的挑战二
如何实现数据库内机器学习执行过程的优化 面向ML的优化引擎 ML基本数据操作代价估计 ML算法自动生成 ML模型版本管理
数据库内机器学习的挑战三
如何设计底层机器学习基本数据操作执行引擎 基于关系运算的机器学习基本操作 异构机器学习计算引擎 分布式加速架构 机器学习执行优化技术
数据库内机器学习的挑战四
如何设计面向机器学习的数据管理引擎 面向ML的数据存储/索引 面向ML的数据清洗 面向ML的特征提取
数据库内机器学习技术例析
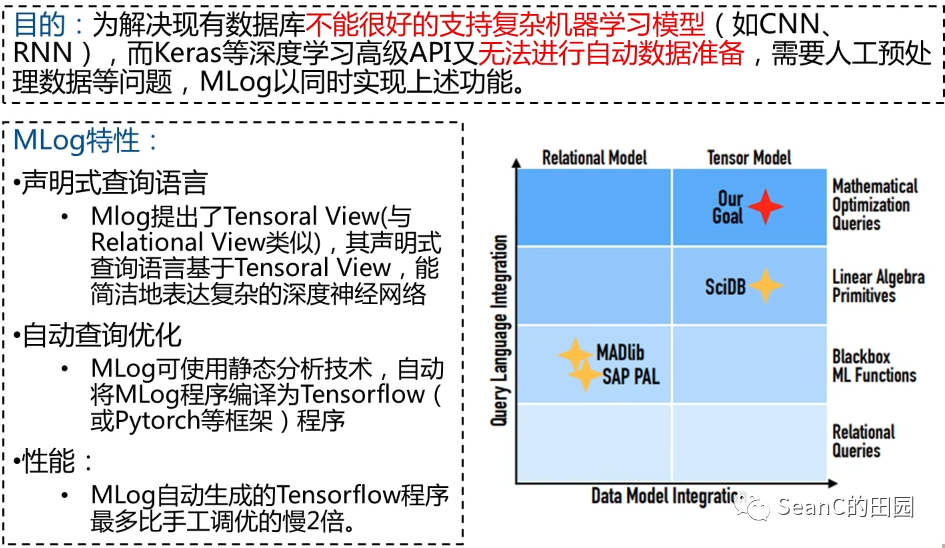

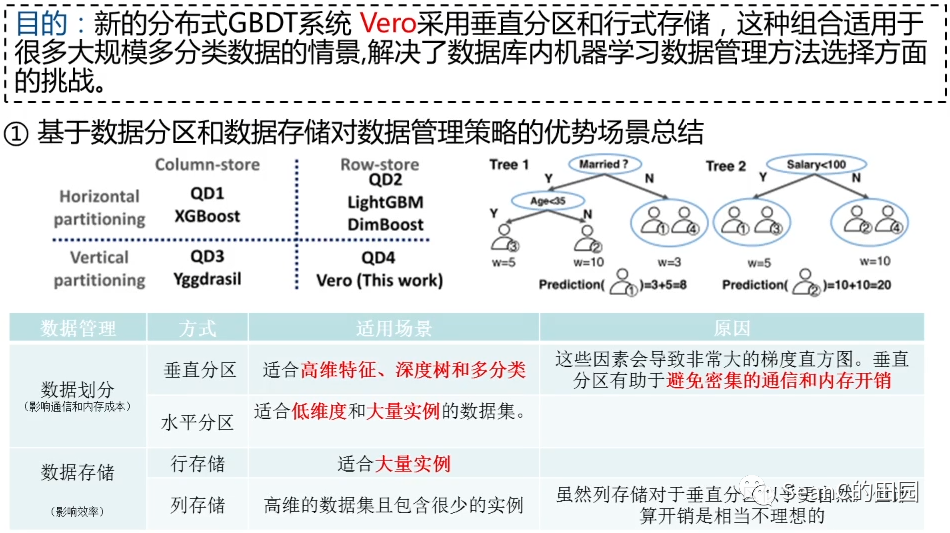
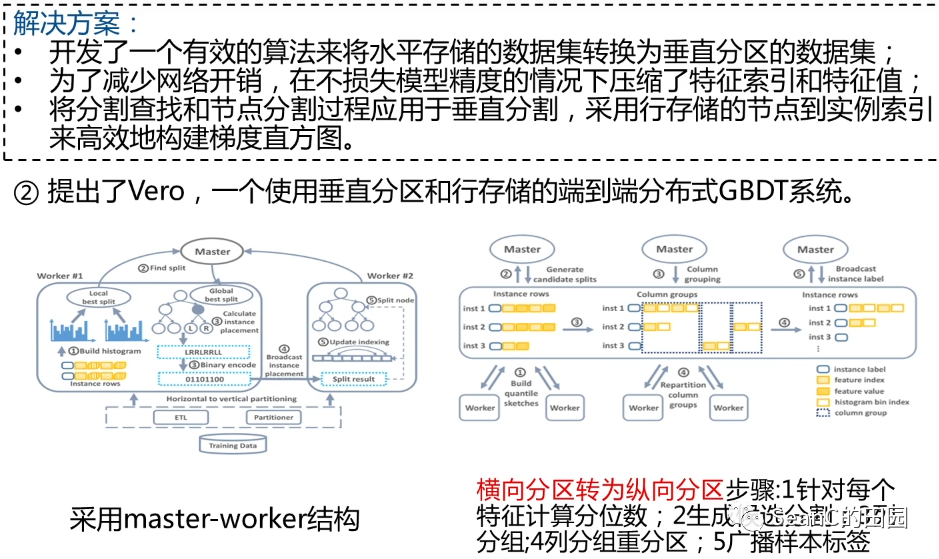
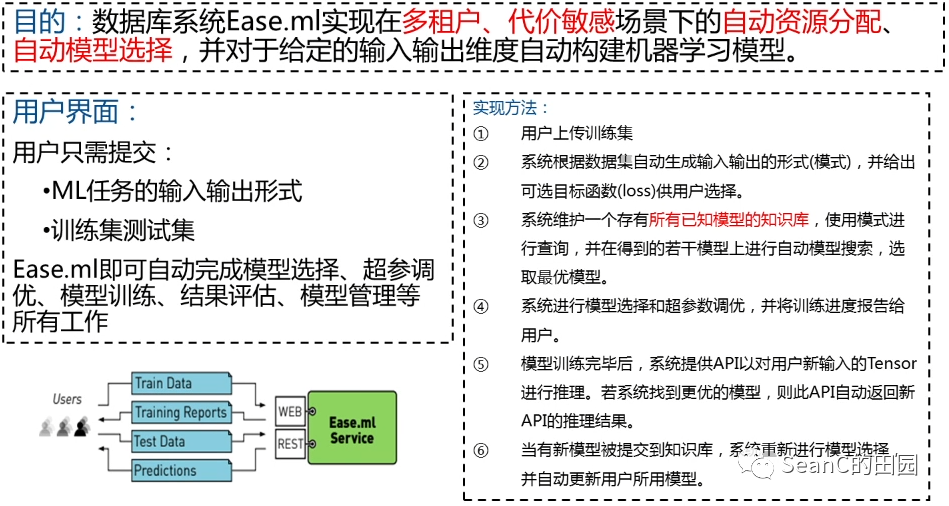
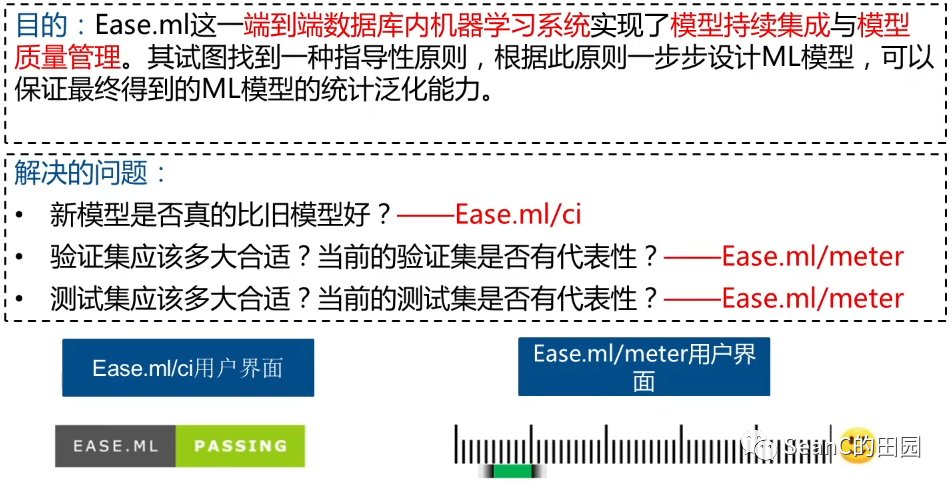
Ease.ml: Towards Multi-tenant Resource Sharing for Machine Learning Workloads
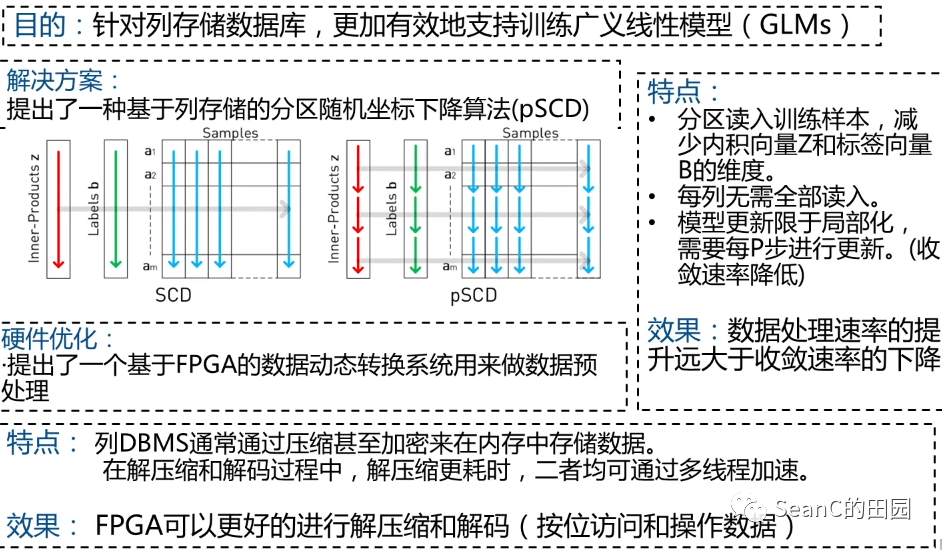
Ease.ml/ci and Ease.ml/meter in Action: Towards Data Management for Statistical Generation

知识驱动的自动机器学习
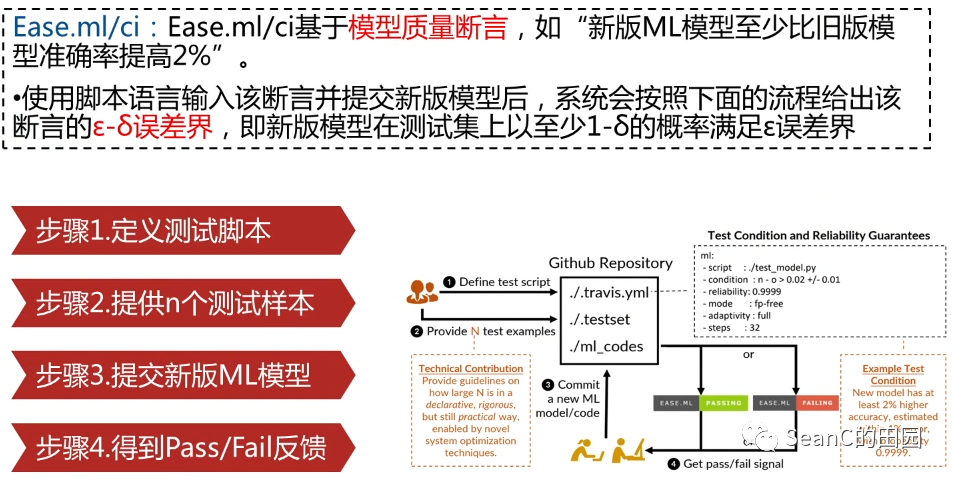
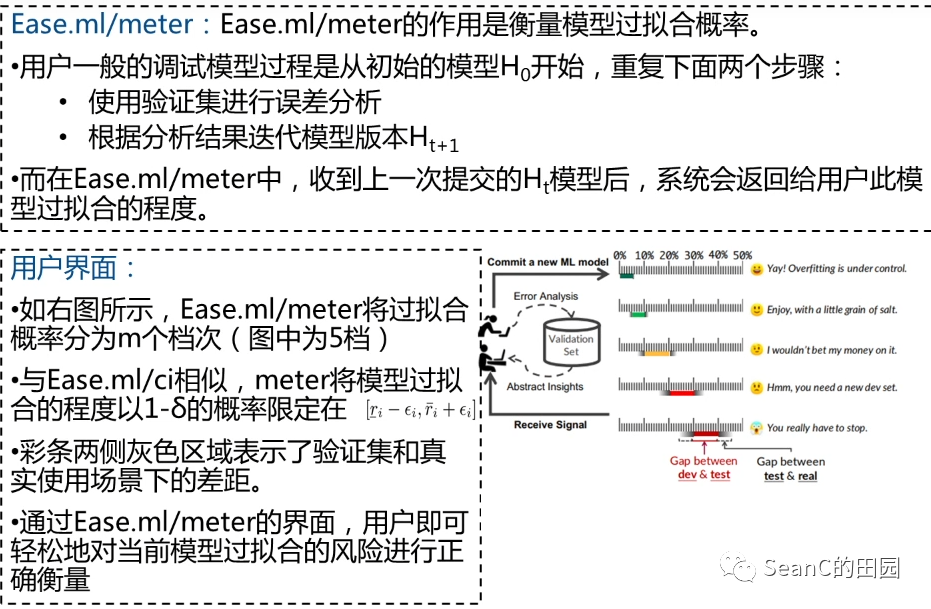
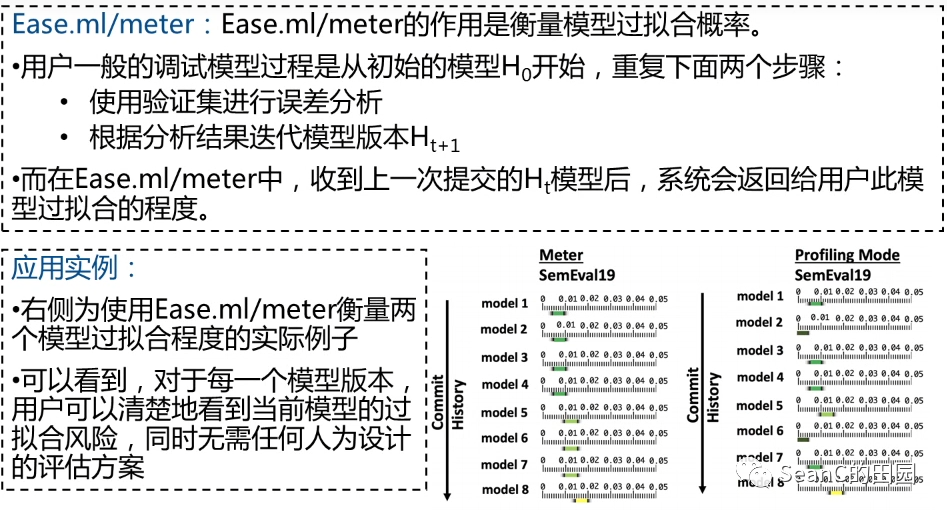
问题:算法选择与参数调优组合问题:根据给定任务实例,帮助用户快速有效地选择合适的机器学习算法和超参数设置
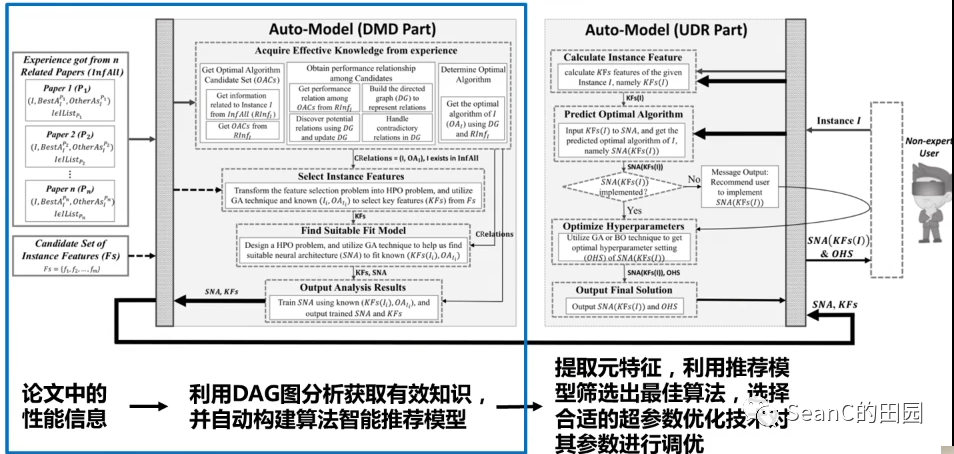
Multi-Objective Neural Architecture Search Based on Diverse Structures and Adaptive Recommendation

更深一步的融合
DB4AI管理技术现状
现有的存储和索引技术不够灵活 对于较为复杂的算法依然不能够完全嵌入到数据库中执行 原始数据、中间结果和模型的存取依靠有经验的DBA实现 机器学习任务的执行优化基本依靠手工完成 尚未有统一的机器学习优化技术来对任务进行执行优化 毫无经验的用户很难实现高效的模型学习
复杂机器学习计算任务亟需自动化的高效数据管理技术
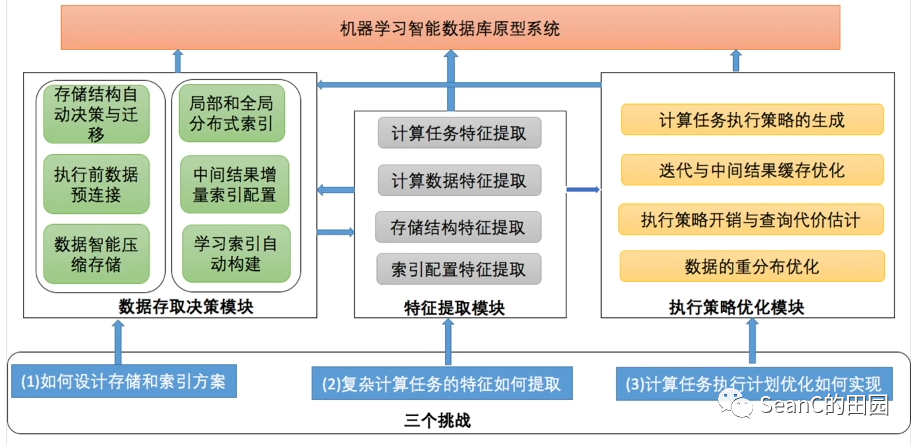
拟解决的难题
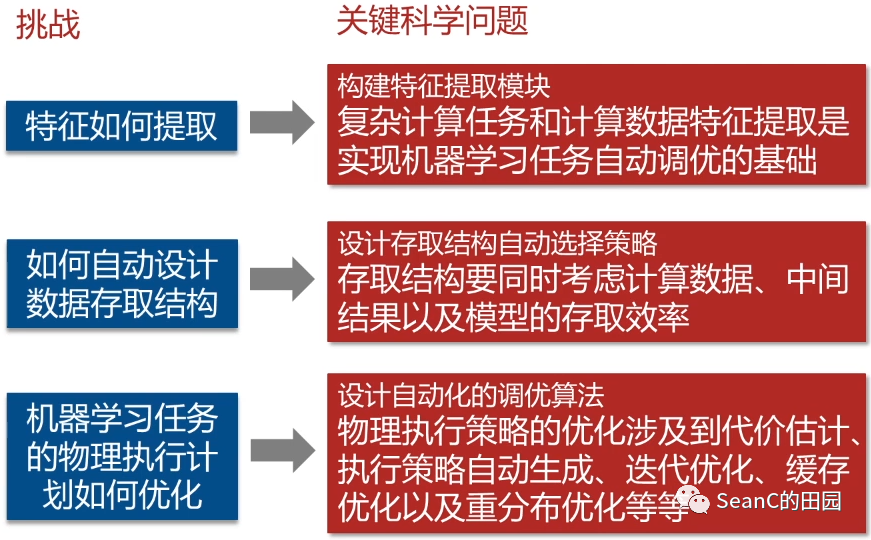
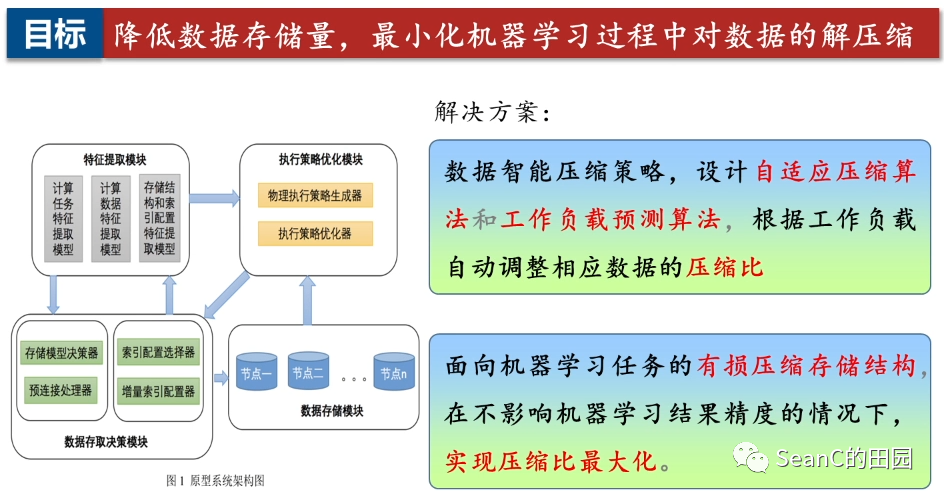
原型系统架构图
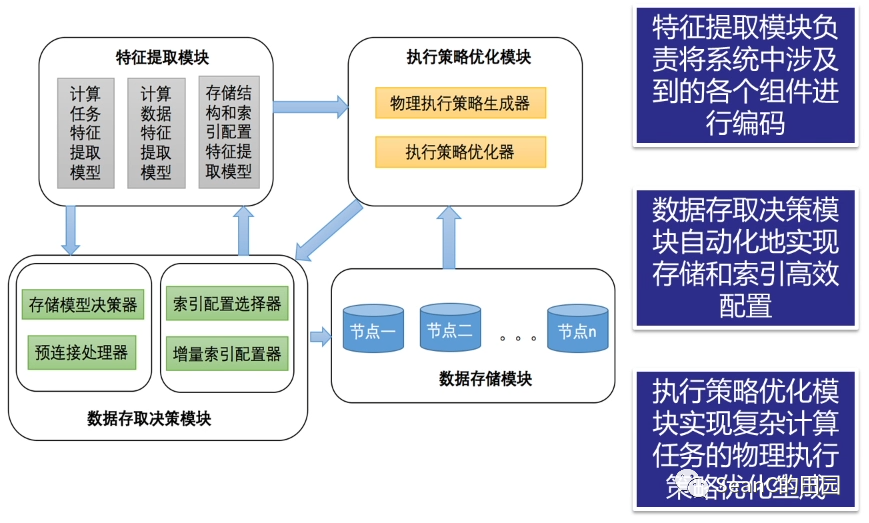
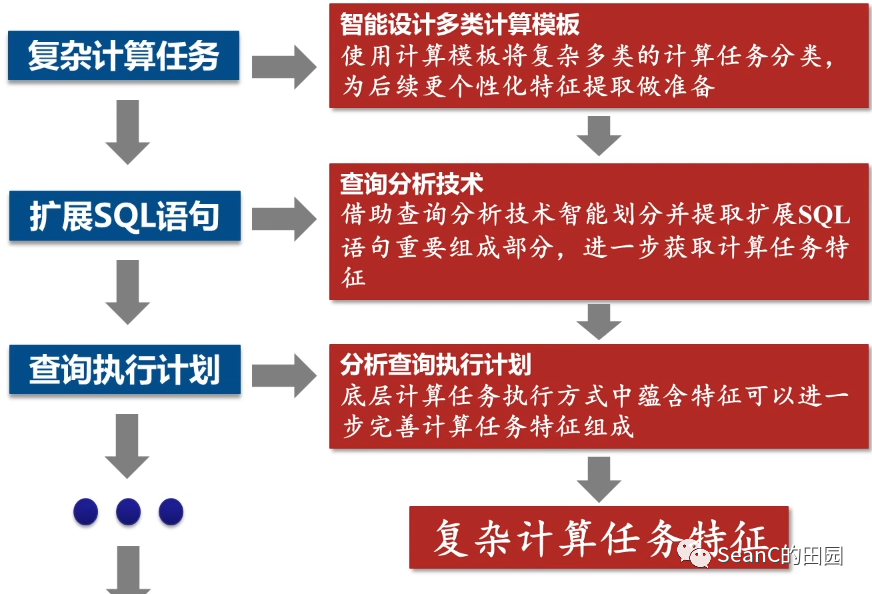
复杂计算任务特征提取
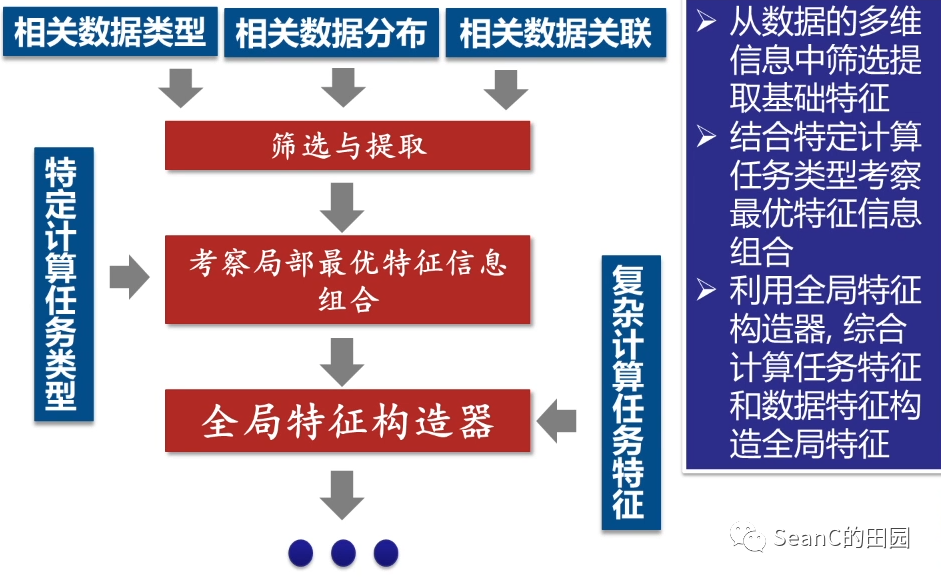
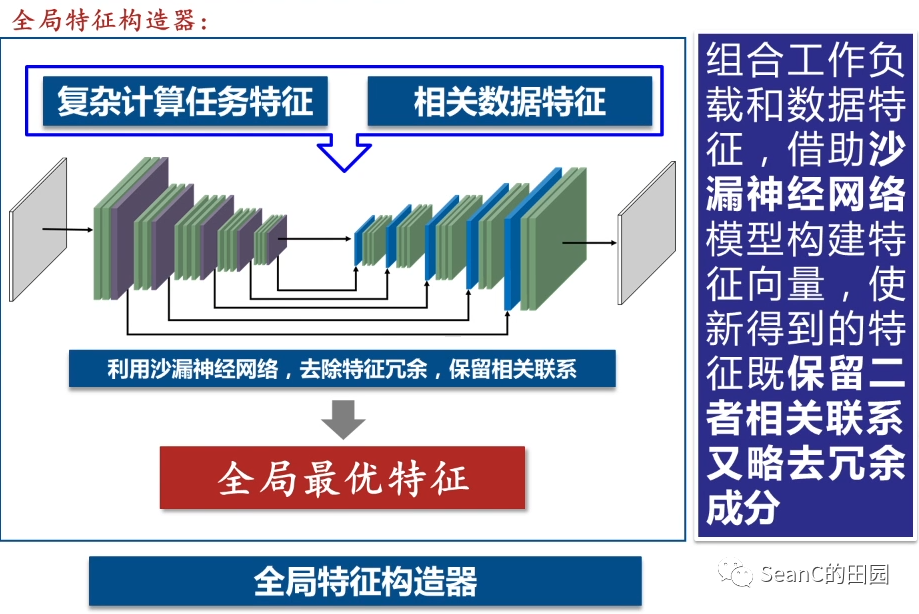
数据特征提取
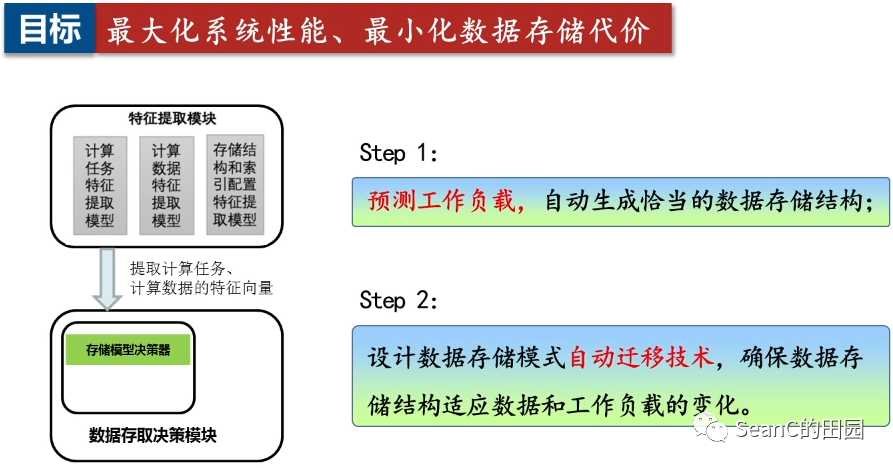
存储结构自动决策与迁移
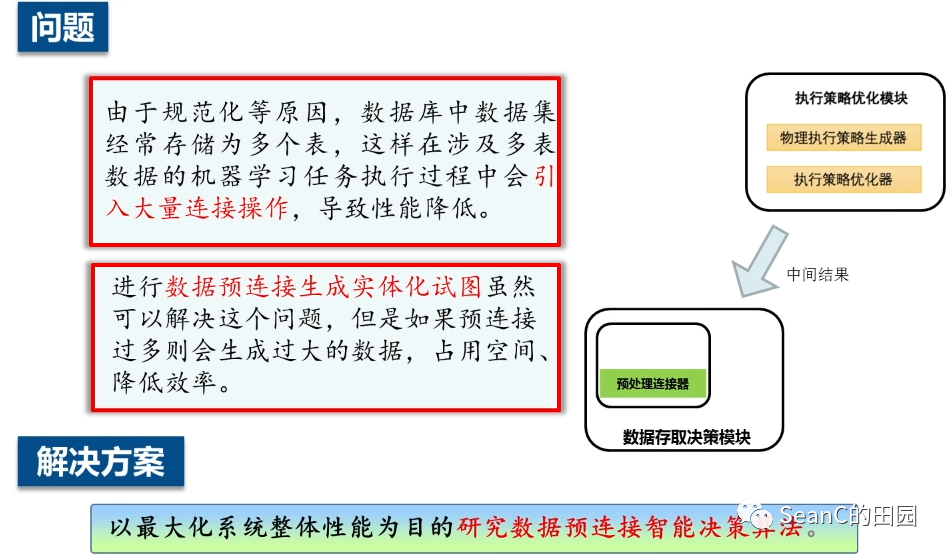
数据预连接智能决策
数据智能压缩
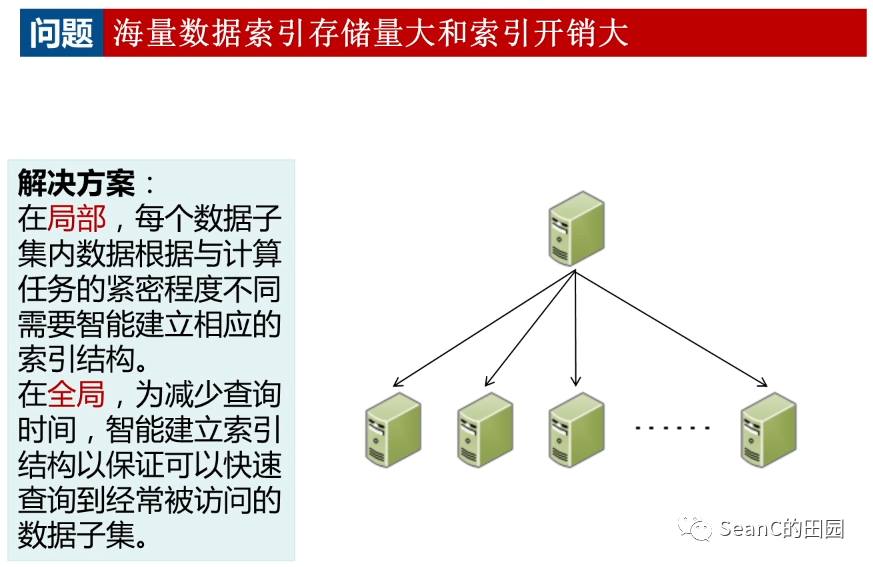
分布式索引
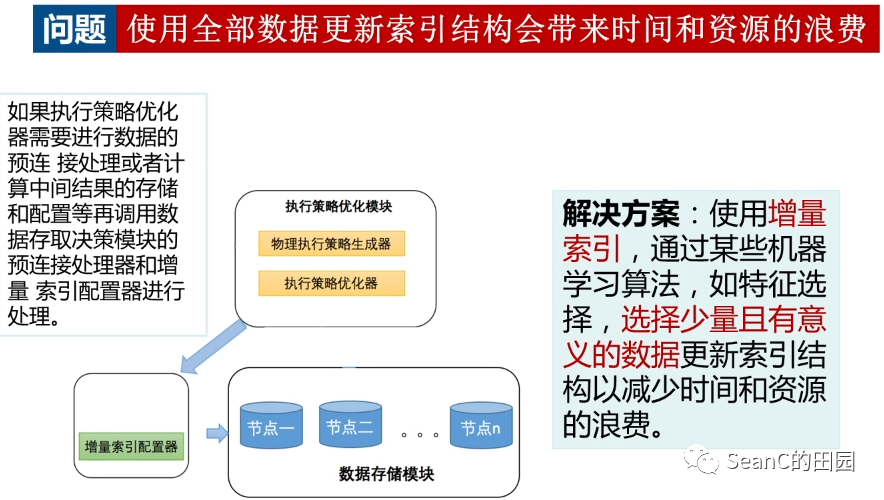
增量索引
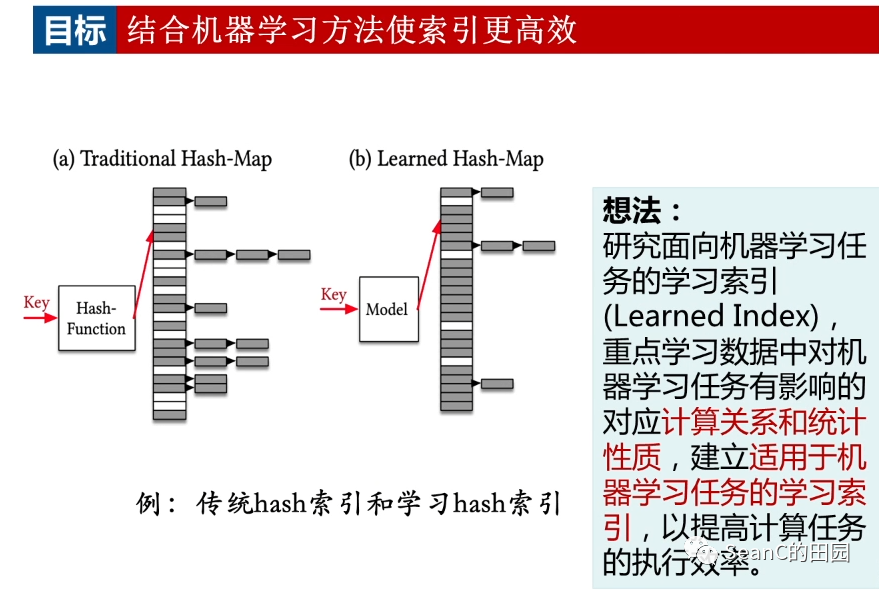
学习索引
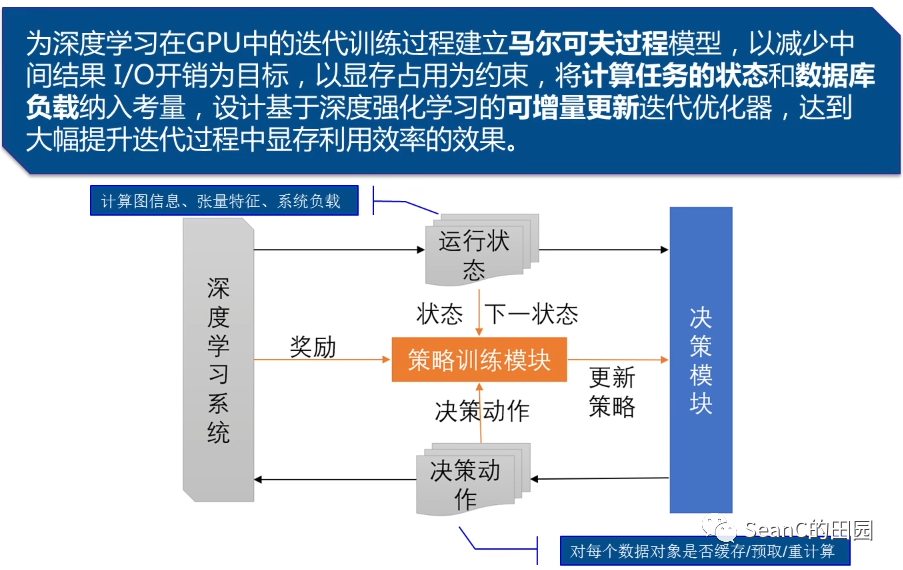
迭代与中间结果缓存优化
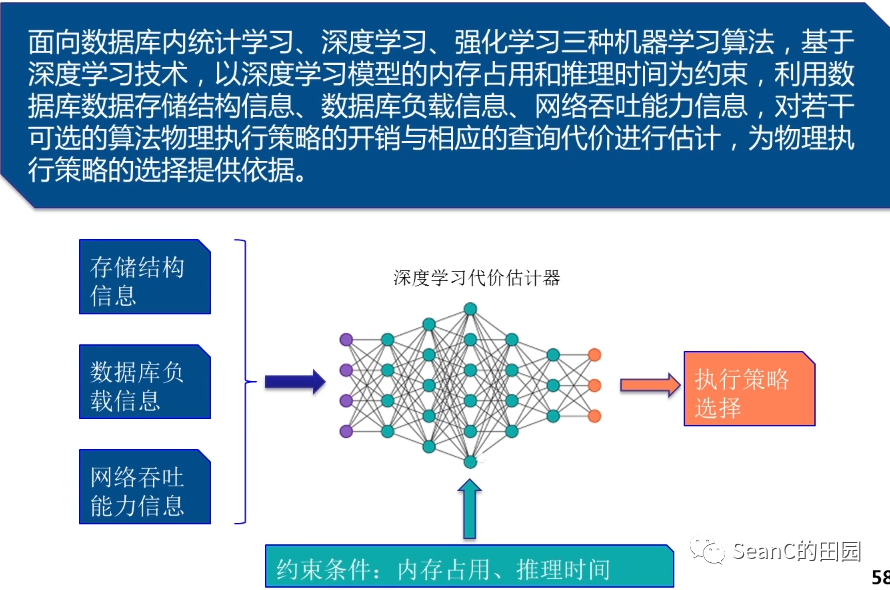
基于深度学习的自动代价估计
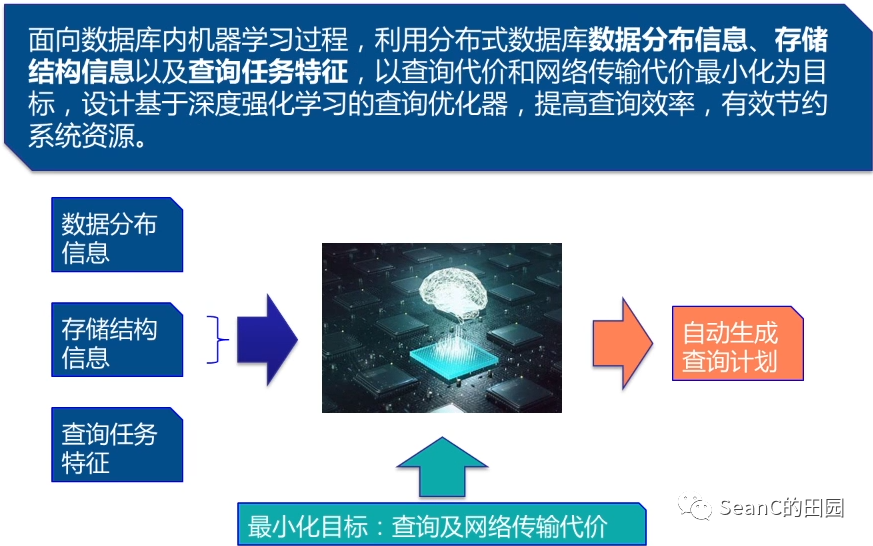
基于强化学习的查询计划优化
基于强化学习的数据重分布