




自动化运维,你玩转了吗?
【摘要】
对CMDB很了解但对于Python还没有上手的读者,强烈建议阅读前面几篇; 对Python了解较少只能写出简单脚本的读者,强烈建议阅读此篇; 已经可以熟练写出Python脚本,但对CMDB不是很了解的读者,建议阅读此篇; 即了解Python,又了解CMDB的读者,可以出门左转,看下一篇。
【CMDB v1.5源码阅读】
【类的关系】
if __name__ == "__main__":
try:
file_path = os.path.join(os.path.dirname(__file__), "data.json")
file_store = Store("FILE", file_path) # 实例化一个文件存储的存储对象
cmdb = CMDB(file_store) # 传入读出的数据源实例化一个CMDB的对象
cmd_params = Params(cmdb.operations) # 实例化从命令行获取参数的对象
op, args = cmd_params.parse(sys.argv) # 使用参数对象的解析方法解析出要做的操作和具体的参数
result = cmdb.execute(op, args) # 传入参数对象解析出的操作和具体参数,调用CMDB对象的执行操作方法
print(result)
except Exception as e:
print(e)
Params参数类,
Store存取类以及
CMDB类, 通过入口函数中类的实例化以及参数的传递可以看出三个对象之间的关系。
先实例化存取类负责数据的读取和保存 再实例化CMDB类,并将存取对象传入CMDB类中,负责具体操作时对数据的读写 最后实例化参数类,解析命令行参数,并将解析结果传入CMDB类的实例方法中
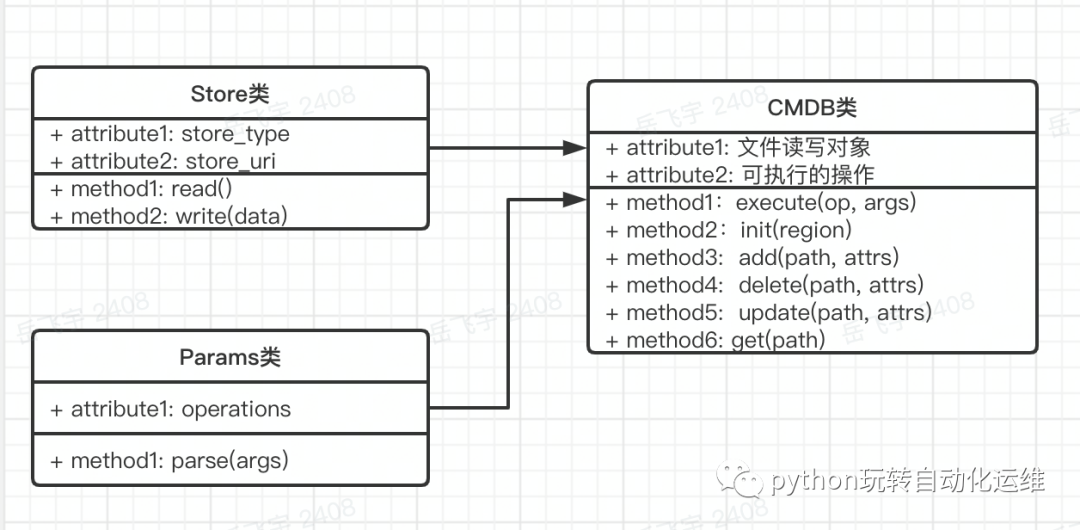
【CMDB类】
cmdb = CMDB(file_store) # 传入读出的数据源实例化一个CMDB的对象
Tips 这里用到了类之间的组合,这属于一种编程规范:在面向对象的过程中,尽量避免不必要的继承,而是要多使用对象的组合。
一、属性
class CMDB:
def __init__(self, store):
self.store = store
self.operations = self.methods()
def methods(self):
ops = []
for m in dir(self): # 获取self变量的所有属性和方法
if m.startswith("__") or m.startswith("__"): # 过滤掉内置属性和方法
continue
if not callable(getattr(self, m)): # 过滤掉属性
continue
ops.append(m)
return ops
__init__()函数在实例化类的时候传入的,而允许执行的操作需要我们调用自身类中的一个实例方法去获取。
dir()这个方法不知道大家是否还有印象,在之前的文章中提到过,由于Python中所有变量皆对象,可以用过
dir()这个方法获取到某个变量具有的所有属性和方法,所以这里通过
dir(self)来获取实例对象所有的属性和方法,并循环去进行判断。
__,而内置的方法前后都会加
__,所以在每次循环时,通过判断这个变量名是否以
__开头或结尾,便可以过滤出内置的属性和方法。
callable()函数会返回一个
bool值,可以判断传入的参数是否是可被调用的,如果返回True就说明传入的参数是一个函数。
getattr(obj, name)函数可以传入一个对象和一个字符串,会根据传入的name返回obj中对应的属性或方法
二、实例方法
class CMDB:
def __init__(self, store):
self.store = store
self.operations = self.methods()
def execute(self, op, args):
if op not in self.operations:
raise Exception("%s is not valid CMDB operation, should is %s" % (op, ",".join(self.operations)))
method = getattr(self, op)
return method(*args)
def init(self, region):
data = self.store.read()
if region in data:
raise Exception("region %s already exists" % region)
data[region] = {"idc": region, "switch": {}, "router": {}}
self.store.save(data)
return region
1. 上一讲已经提到,类的实例方法是类必须实例化之后才能被调用的,且第一个参数必须是self
,CMDB的已知操作分别是init(), add(), delete(), update(), get()
,这些都应该是实例方法,用法也都几乎一样。
2. execute(self, op, args)
函数是在CMDB类中额外新增一个功能,它要求传入要执行的操作和操作所需的参数。
这个函数的功能是作为CMDB统一对外暴露的入口,执行增删改查的操作都通过这个函数来进行,主要目的是为了增加整个CMDB类的可扩展性。大家可以参照之前没有重构过的代码进行比较一下:
if args[1] == "init":
init(args[2])
elif args[1] == "add":
add(*args[2:])
elif args[1] == "get":
get(args[2])
elif args[1] == "update":
update(*args[2:])
elif args[1] == "delete":
delete(*args[2:])
else:
print("operation must be one of get,update,delete")
execute()方法,直接根据
operation的名字去调用对应的函数即可。
if...else..的方式是不是每次都需要去修改代码,这其实就是扩展性不够好的体现,现在重构过之后使用
execute()方法,则完全可以不用修改额外的代码,大家可以仔细体会一下。
init(self, region)这个函数是CMDB初始化地域的函数,大家注意与
__init__()区分
def init(self, region):
data = self.store.read()
if region in data:
raise Exception("region %s already exists" % region)
data[region] = {"idc": region, "switch": {}, "router": {}}
self.store.save(data)
return region
read_file()或者
write_data()函数,但现在需要通过存取对象来实现。
self.store此刻就已经是存取对象,可以直接通过
self.store.read()或者
self.store.save()来实现数据的读写功能。
init()的方法改写一下其他的增删改查操作,将原先的函数改写为实例方法
三、静态方法
@staticmethod,这属于Python中的装饰器,装饰器也会单独在番外篇中详细讲解,也是属于Python中的一大特点。
self参数,因为静态方法的特点就是该方法不属于任何类或者实例对象,它是静态的,它只是因为这个方法从面向对象的角度来说,可以让它放在CMDB类中,但它本身并不需要引用到任务与该类或者该类的实例相关的其他属性或方法。
import json
class CMDB:
@staticmethod
def check_parse(attrs):
# 检查参数的合法性
if attrs is None:
return
try:
attrs = json.loads(attrs)
return attrs
except Exception:
raise Exception("attributes is not valid json string")
@staticmethod
def locate_path(data, path):
# 根据path定位到data的位置
target_path = data
path_seg = path.split("/")[1:]
for seg in path_seg[:-1]:
if seg not in target_path:
print("location path is not exists in data, please use add function")
return
target_path = target_path[seg]
return target_path, path_seg[-1]
self,并且它本身也与实例对象无关,它只是形式上归属于CMDB类,所以可以直接通过
CMDB.check_parse()来调用,如下面的
add():
class CMDB:
def add(self, path, attrs):
attrs = CMDB.check_parse(attrs)
if not attrs:
raise Exception("attrs is invalid json string")
data = self.store.read()
target_path, last_seg = CMDB.locate_path(data, path)
if last_seg in target_path:
raise Exception("%s already exists in %s, please use update operation" % (last_seg, path))
target_path[last_seg] = attrs
self.store.write(data)
return attrs
【总结】
import json
import sys
import os
import time
class Store:
version = None
update_time = None
def __init__(self, store_type, store_uri):
self.store_type = store_type # 存储介质类型
self.store_uri = store_uri # 存储介质的路径
def save(self, data): # 存储方法
data["version"] = (Store.version or 1) + 1
data["update_time"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
with open(self.store_uri, "w+") as f:
json.dump(data, f, indent=2)
def read(self): # 读取方法
with open(self.store_uri, "r+") as f:
data = json.load(f)
try:
Store.version = data.pop("version")
Store.update_time = data.pop("update_time")
except Exception:
pass
return data
class CMDB:
version = None
update_time = None
def __init__(self, store):
self.store = store
self.operations = self.methods()
def methods(self):
ops = []
for m in dir(self):
if m.startswith("__") or m.startswith("__"):
continue
if not callable(getattr(self, m)):
continue
ops.append(m)
return ops
def execute(self, op, args):
if op not in self.operations:
raise Exception("%s is not valid CMDB operation, should is %s" % (op, ",".join(self.operations)))
method = getattr(self, op)
return method(*args)
def init(self, region):
data = self.store.read()
if region in data:
raise Exception("region %s already exists" % region)
data[region] = {"idc": region, "switch": {}, "router": {}}
self.store.save(data)
return region
def add(self, path, attrs):
attrs = CMDB.check_parse(attrs)
if attrs is None:
raise Exception("attrs is invalid json string")
data = self.store.read()
target_path, last_seg = CMDB.locate_path(data, path)
if last_seg in target_path:
raise Exception("%s already exists in %s, please use update operation" % (last_seg, path))
target_path[last_seg] = attrs
self.store.save(data)
return attrs
def delete(self, path, attrs=None):
attrs = CMDB.check_parse(attrs)
data = self.store.read()
target_path, last_seg = CMDB.locate_path(data, path)
if attrs is None:
if last_seg not in target_path:
raise Exception("%s is not in data" % path)
target_path.pop(last_seg)
if isinstance(attrs, list):
for attr in attrs:
if attr not in target_path[last_seg]:
print("attr %s not in target_path" % attr)
continue
if isinstance(target_path[last_seg], dict):
target_path[last_seg].pop(attr)
if isinstance(target_path[last_seg], list):
target_path[last_seg].remove(attr)
self.store.save(data)
return attrs
def update(self, path, attrs):
attrs = CMDB.check_parse(attrs)
if attrs is None:
raise Exception("attrs is invalid json string")
data = self.store.read()
target_path, last_seg = CMDB.locate_path(data, path)
if type(attrs) != type(target_path[last_seg]):
raise Exception("update attributes and target_path attributes are different type.")
if isinstance(attrs, dict):
target_path[last_seg].update(attrs)
elif isinstance(attrs, list):
target_path[last_seg].extend(attrs)
target_path[last_seg] = list(set(target_path[last_seg]))
else:
target_path[last_seg] = attrs
self.store.save(data)
return attrs
def get(self, path):
if "/" not in path:
raise Exception("please input valid path")
data = self.store.read()
if path == "/":
return json.dumps(data, indent=2)
try:
target_path, last_seg = CMDB.locate_path(data, path)
ret = target_path[last_seg]
except KeyError:
raise Exception("path %s is invalid" % path)
return json.dumps(ret, indent=2)
@staticmethod
def check_parse(attrs):
if attrs is None: # 判断attrs的合法性
return None
try:
attrs = json.loads(attrs)
return attrs
except Exception:
raise Exception("attributes is not valid json string")
@staticmethod
def locate_path(data, path):
target_path = data
path_seg = path.split("/")[1:]
for seg in path_seg[:-1]:
if seg not in target_path:
print("location path is not exists in data, please use add function")
return
target_path = target_path[seg]
return target_path, path_seg[-1]
class Params:
def __init__(self, operations) -> None:
self.operations = operations
def parse(self, args):
if len(args) < 3:
raise Exception("please input operation and args, operations: %s" % ",".join(self.operations))
operation = args[1]
params = args[2:]
return operation, params
if __name__ == "__main__":
try:
file_path = os.path.join(os.path.dirname(__file__), "data.json")
file_store = Store("FILE", file_path) # 实例化一个文件存储的存储对象
cmdb = CMDB(file_store) # 传入读出的数据源实例化一个CMDB的对象
cmd_params = Params(cmdb.operations) # 实例化从命令行获取参数的对象
op, args = cmd_params.parse(sys.argv) # 使用参数对象的解析方法解析出要做的操作和具体的参数
result = cmdb.execute(op, args) # 传入参数对象解析出的操作和具体参数,调用CMDB对象的执行操作方法
print(result)
except Exception as e:
print(e)
【篇后语】

yuefeiyu1024
文章转载自python玩转自动化运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
