




Redis压缩列表不仅在List中使用,同时在哈希表存储小整数的或者较短的字符串时也会使用压缩列表。压缩列表为了提高内存利用率,是一种使用特殊的编码实现的双向链表。
我们通过下面这张图来了解下压缩列表的结构:

zlbytes:压缩列表的总字节,图示中列表总字节为100bytes(0x64);
zltail:表示压缩列表中的最后一个元素从压缩列表起始位置的偏移量。图示中,p指向压缩列表起始位置,则p+80(0x50)则指向最后一个元素entry n;
zllen:表示元素个数,图示中的n表示有n个元素。
zlen:特殊值0xFF,表示压缩列表的尾部。
图示中在各个块下的数字表示该节点占用空间,zlbytes、zltail占4字节,zllen占2字节、zlen占1字节、entry不定,由存储的对象决定。
压缩列表中数据节点可存储字节数组或者整数,其结构如下图:
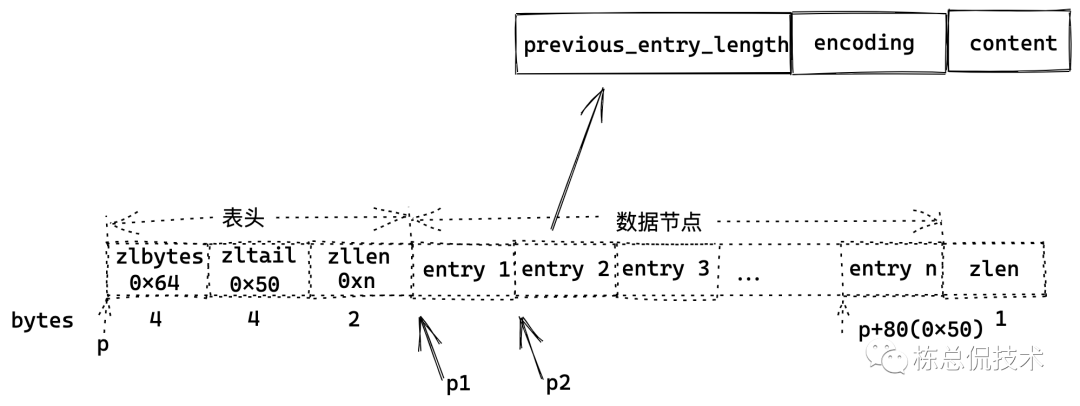
previous_entry_length: 前一个节点的长度,图示中p1(指向entry1的指针)= p2(entry2的指针)- entry2->previous_entry_length。
当前一个节点长度<254,previous_entry_length占用1个字节。
当前一个节点长度>=254,previous_entry_length占用5个字节,且第一个字节为固定的0xFE(十进制254)。
encoding:记录节点保存的值类型和长度。
content:保存节点的值,节点可以是字节数组或者整数,类型和长度由encoding决定。
| 编码 | 长度 | 备注 |
| 00xxxxxx | 1字节 | 字节数组,长度<=63 |
| 01xxxxxx xxxxxxxx | 2字节 | 字节数组,长度<=(2^14)-1 |
| 10_ xxxxxxxx xxxxxxxxxxxxxxxx xxxxxxxx | 5字节 | 字节数组,长度<=(2^32)-1 |
| 1100 0000 | 1字节 | int16 |
| 1101 0000 | 1字节 | int32 |
| 1110 0000 | 1字节 | int64 |
| 1111 0000 | 1字节 | 24位有符号整数 |
| 1111 1110 | 1字节 | 8位有符号整数 |
| 1111 xxxx | 1字节 | 无content 使用xxxx表示数字 |
遍历节点
压缩列表从尾部向头部进行遍历,利用previous_entry_length完成:
首先pN指针指向尾节点entryN
p(N-1) = pN - entryN.previous_entry_length,得到节点N-1
...
p1 = p2 - entry2.previous_entry_length,得到第一个节点entry1
而压缩列表从头部向尾部进行遍历,需要解码当前元素的encoding,获取长度,并使用当前指针加上对应的长度指向下一个节点。
插入节点
插入元素需要进行以下三步操作:
将插入的元素编码为entry结构
重新分配空间
拷贝数据
这里我们需要注意,重新分配的空间是否等于原有空间+需要插入节点的空间呢?答案是不一定的,当插入节点后,其后方节点的previous_entry_length可能是1个字节也可能是5个字节(由插入节点的长度是否大于254决定)。当插入一个长度小于4时,后一个节点的previous_entry_length可能从5变成1,导致虽然插入了一个元素,但是整个压缩列表的占用空间反而减少了。
删除节点
与插入节点类似,存在删除一个元素然而整个压缩列表的占用空间反而增加了,这里不再详细说明。
连锁更新
在删除节点、插入节点操作中,都存在着操作节点的后一个节点previous_entry_length从5字节到1字节(-4)或者从1字节到5字节(+4)。这样会导致当前节点的后面所有的节点出现空间重分配。这个过程叫做连锁更新。
大家不必对连锁更新带来的效率问题进行担忧,Redis无论是对各种数据结构的使用是有其开关和阀值控制的。在本篇开始就有说到在哈希表存储较少量数据时,Redis避免内存碎片化而使用压缩列表来存储数据。所以,针对不同的场景,Redis会灵活使用其数据结构来应对。压缩列表在少量数据场景时,是可以保证查询速率同时又保证了内存利用率的。
压缩列表的介绍就到这里了,我们通过本篇了解到Redis是如何实现压缩列表的。同时也了解到了Redis会根据不同的场景灵活使用不同的数据结构来保证访问速率同时也提升内存利用率。
往期回顾:
Redis系列2 - Redis为什么这么快?有序集合的实现
Redis系列4 - Redis为什么这么省?整数集合的实现

