




DSE精选文章
使用半监督多级神经方法的细粒度多标签分类
Fine‑Grained Multi‑label Sexism Classification Using a Semi‑Supervised Multi‑level Neural Approach
文章介绍
性别歧视被定义为基于性别的陈规定型、偏见或歧视,以各种公开和微妙的形式出现,渗透到个人和职业空间。随着越来越多的人分享他们经历或目睹的性别歧视案例,将这些案例自动分类为已有的性别歧视类别有助于打击这种压迫,还可以帮助性别研究员更好地分析性别歧视。该文研究了性别歧视账户(报告)的细粒度、多标签分类,主要贡献如下:
(1)该文基于23种性别歧视的分类,设计了针对问题的多标签性自我提炼技术,以利用未标记的样本来扩充标记集。
(2)该文将现有标记集的高文本多样性作为候选未标记实例的预期质量,还将多标签分类的缓解类不平衡的方法融入到半监督学习中。
(3)该文提出了一种神经网络架构,将biLSTM和注意机制与领域适应的BERT模型相结合,允许对多标签性别歧视分类进行端到端的训练。该文制定了一种多级训练方法,使用不同粒度级别的性别歧视类别顺序训练模型。
(4)该文设计了一个损失函数,能够利用与数据相关的任何标签可信度得分。
(5)在Parikh等人提出的包含13023个性别歧视账户的数据集上,该文提出的几种方法优于各种多标签性别歧视分类的基线模型。
实验效果
该文实验部分使用上文提及的数据集,文中设计的半监督方法还可以自动扩展此数据集。评估指标包括SA、Fins、Acc、Fmac和Fmic,其中SA计算精确匹配的分数,是最严格的度量标准。
如图1所示,该文提出的性别歧视分类体系结构,其中性别歧视的每个原始输入文本都被表示为多个三维张量,包含每个张量嵌入每条句子的每个单词。

图1. 性别歧视分类架构
如图2所示,性别歧视类别有三级层次结构,不同的级别合并的类别以不同的颜色显示。首先,使用级别“1类别“训练模型,该类别具有全连接层,具有8个输出单元。其次,使用15个中间级类别修改的训练数据来训练该模型。最后,训练23个类别的3级模型,并使用该模型执行所需的细粒度性别歧视分类。
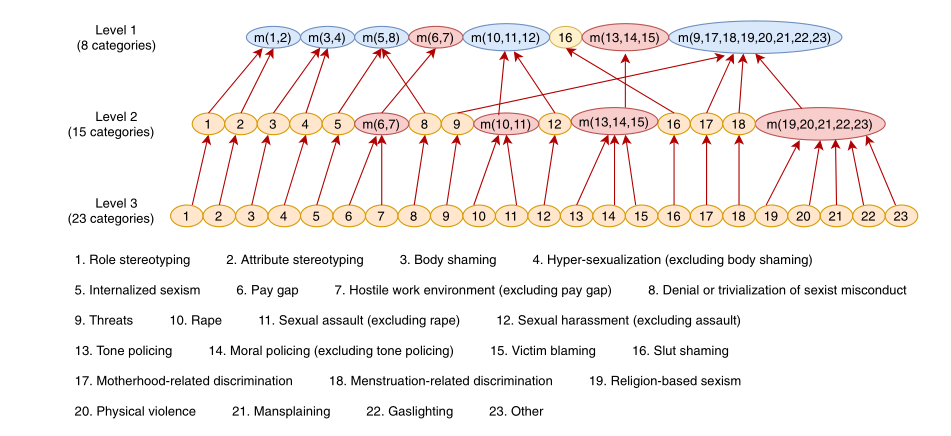
图2. 多级训练的类别层次结构
如图3所示,从五个深度学习基线分类器的Fins、Fmac和SA结果可以看到文章的最佳增强方法在三个指标的不同分类器中增强数据的相对有效性。图4展示了原始数据和使用该文的最佳方法(Diversity.label∩ Support.weakest)提供的数据的每个标签的正负样本覆盖率。
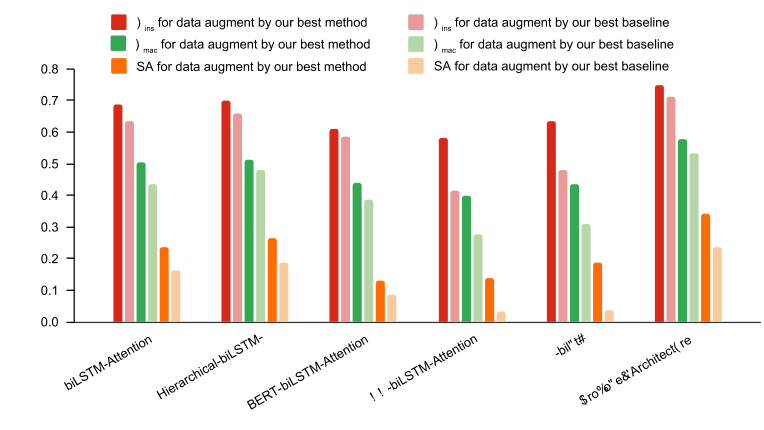
图3. 不同方法的性能对比
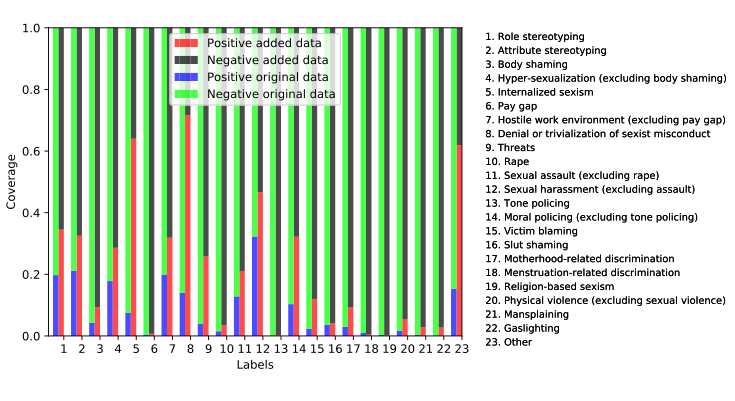
图4. 标签正负样本覆盖率
如表1所示,该文比较了在不同阶段的PA和最佳分类基线方法(Opti-DL)的评估结果。可以观察到,与Opti-DL相比,PA都能生成最佳的增强数据,并作为最终分类器表现良好。
表1. 所有指标在不同阶段的表现

如图5所示,该文比较了提出的总体最佳方法(CBCE损失的多级P-aug)与最佳基线模型(Opti-DL)的类性能。每个类包含了两种方法在三次实验中的F分数平均值。结果表明,对于大多数类别,所提出方法的F分数优于基线模型F分数。
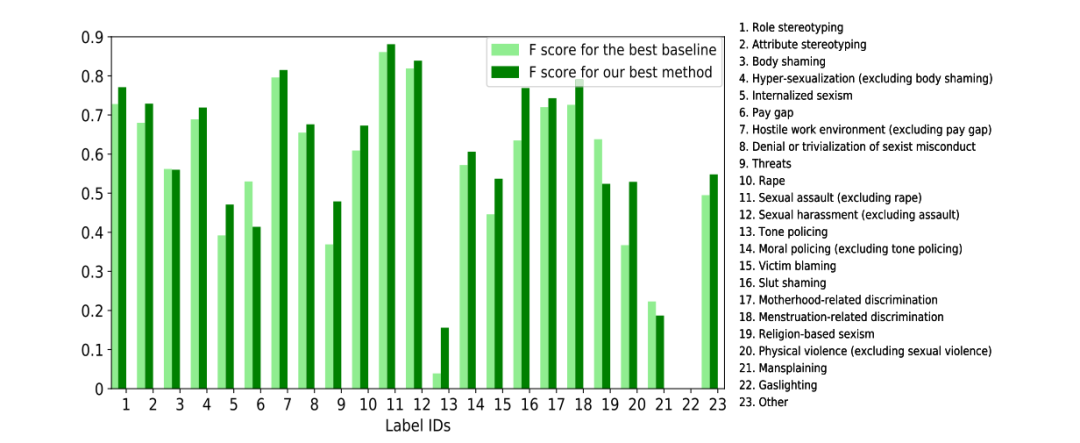
图5. 不同方法的性别歧视分类F分数
结语
该文研究了使用23种性别歧视类别对性别歧视账户进行精细分类的半监督学习,提出了一套基于自训练的方法,设计多标签技术,以利用未标记的性别歧视实例来增加训练数据。该文设计了一个损失函数,还提出了一种神经结构,该结构包含一个端到端训练的领域自适应BERT模型,以提高细粒度性别歧视分类性能。该文还设计了一种从粗粒度到细粒度的多标签性别歧视分类训练方法,其中使用不同粒度级别的性别歧视类别顺序训练模型。该文提出的方法在许多标准度量中的性能优于各种传统的机器学习和深度学习基线模型。作者未来工作的一个方向是调整和扩展性别歧视分类方法,另一个可能的方向是研究神经网络方法,以识别和分类特定形式的性别歧视。
作者简介




期刊简介



