




ICML 2022 | Retroformer: Pushing the Limits of End-to-end Retrosynthesis Transformer
“文章信息
来源:Proceedings of the 39th International Conference on Machine Learning(ICML) 2022
”
标题:Retroformer: Pushing the Limits of End-to-end Retrosynthesis Transformer
作者:Yue Wan, Chang-Yu Hsieh, Ben Liao, Shengyu Zhang
链接:https://proceedings.mlr.press/v162/wan22a.html
代码:https://github.com/yuewan2/Retroformer
内容简介
逆合成预测是有机合成中的基本挑战之一。任务是预测给定核心产物的反应物。随着机器学习的进步,计算机辅助合成规划越来越受到关注,提出了许多方法来解决这个问题,它们对附加化学知识的依赖程度不同。本文提出了 Retroformer,这是一种新的基于 Transformer 的逆合成预测架构,无需依赖任何化学信息学工具进行分子编辑。通过提出的局部注意力头,该模型可以联合编码分子序列和图,并在局部反应区域和全局反应上下文之间有效地交换信息。Retroformer 达到了端到端无模板逆合成的最新精度,并在许多强大的基线上改进了更好的分子和反应有效性。此外,它的生成过程是高度可解释和可控的。总的来说,Retroformer 突破了深度生成模型的反应推理能力的极限。
本文对用于逆合成预测的无模板生成方法感兴趣。现有方法未能充分挖掘深度生成模型在反应推理方面的潜力,本文认为基于端到端 Transformer (Vaswani et al., 2017) 的架构可以达到相同的竞争基准精度以及良好的有效性和可解释性。本文提出了 Retroformer,这是一种新颖的端到端逆合成 Transformer,它引入了一个特殊的注意力头。它能够联合编码分子的顺序和图形信息,并允许在局部反应区域和全局反应上下文之间进行有效的信息交换。生成过程也对确切的反应区域敏感。本文的端到端模型不依赖于化学信息学工具对分子编辑的任何额外帮助。实验表明,本文的模型可以在已知和未知的反应类别设置中分别将原版 Transformer 提高 12.5% 和 14.4% 的 top-10 准确度。它达到了无模板方法的最新精度,并且与基于模板和半模板的方法都具有竞争力。与强基线模型相比,它还享有更好的分子和反应有效性。该模型对于下游使用具有高度的可解释性和可控性。
本文的贡献总结如下
本文提出了Retroformer,这是一种新颖的基于Transformer 的架构,它引入了局部注意力头,以突破深度生成模型在逆合成预测中的反应推理能力的极限。 所提出的方法在反应类别已知和未知设置下分别达到了 64% 和 53.2% 的 top-1 准确度,这是无模板逆合成的新的最先进性能。 与一般逆合成Transformer 相比,所提出的方法进一步将top-10 分子和反应有效性分别提高了23.6% 和22.0%。
Retroformer
本文提出了 Retroformer,这是一种新颖的基于 Transformer 的模型,能够以端到端的方式执行可解释的逆合成预测。本文提出了一种特殊类型的局部注意力头,可以支持反应重要性的局部区域和全局反应上下文之间的有效信息交换。它的生成过程对确切的局部区域也很敏感。整体训练和推理可以端到端的方式完成。它是一种完全无模板的方法,无需额外依赖 RDKit 进行分子编辑。整体架构包含一个编码器、一个解码器和两个反应中心标识符。本文还建议使用 SMILES 对齐和动态数据增强作为两种额外的训练策略。
具有边更新的局部全局编码器
由于分子图可以在 SMILES 序列之上提供额外信息,因此本文的编码器将 序列和 (即邻接矩阵和键特征)作为输入。与现有的在整个模块内计算图自注意力的图 Transformer不同,本文的模型在头部级别对图信息进行编码。本文指定了两种类型的注意力头:全局头和局部头。global head 和 vanilla self-attention head 一样,它的感受野是整个 SMILES 序列。另一方面,局部头考虑分子的拓扑结构。单个令牌的接受域仅限于其一跳邻域。此外,本文在关键向量和边缘特征之间执行逐元素乘法,以将键信息合并到计算中。对于第 个令牌,在第 层的局部头部自注意力的推出形式表示为:
其中 A 是键特征矩阵,,, 是用于计算查询 、键 和值 的投影矩阵, 是 softmax 操作。然后将来自全局和局部头的计算表示沿隐藏维度连接并传递到线性层,该层表示更新的令牌特征 。同时,边缘更新模块是一个全连接层(FFN),它将接收和发送令牌的更新特征的串联作为输入:
局部、全局注意力头和边缘更新模块的集成使模型能够有效地在局部区域和全局分子上下文之间交换信息。与 vanilla Transformer (Vaswani et al., 2017) 相同,在编码器层之间强制执行层归一化和残差连接。
反应中心检测
反应中心代表对化学转化有贡献的原子和键组。然而,现有的基于半模板的方法将此概念简化为精确的反应位点。作者认为这种简化可能会导致反应上下文的信息丢失,例如官能团的影响。这些方法也不能以端到端的方式执行逆合成,因为它们依赖 RDKit 将产品转换为合成子。相反,Retroformer 预测每个原子和键的反应概率 ,并将 的反应区域转换为解码器的注意接收场。简而言之,检测到的反应中心 是 的一个子集。
下图显示了预测反应概率的热图可视化。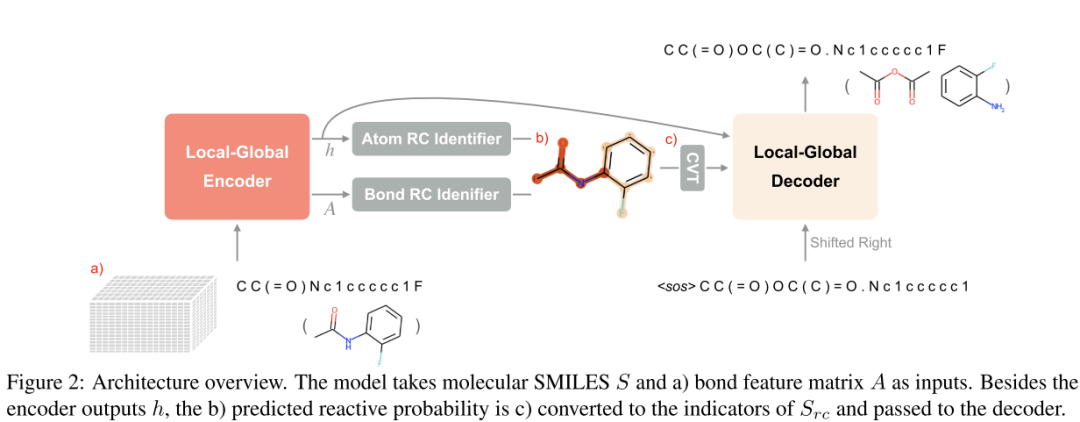 它由两个名为 Atom RC Identifier 和 Bond RC Identifier 的全连接层完成:
它由两个名为 Atom RC Identifier 和 Bond RC Identifier 的全连接层完成:
局部-全局解码器
解码器从上一步获取其生成结果,编码器输出 ,反应中心 作为输入。与编码器类似,本文也在其交叉注意力模块中引入了两个不同的头。全局头与香草头相同。相反,局部头部仅对检测到的反应中心 可见。它计算稀疏交叉注意而不是完全交叉注意。
与编码器相同,来自全局和局部头的计算表示然后沿着隐藏维度连接并传递到表示表示 的线性层。
它本质上将解码器转换为条件生成模块,类似于以转换后的合成子为条件的反应物生成模块(基于半模板的方法)。然而,由于 仅建议反应重要性区域,因此该条件比转换后的合成子的严格条件更为宽松。更重要的是,由于 Retroformer 可以端到端训练,生成反馈可以反向传播到反应中心学习。
实验分析
在已知反应类别的情况下,本文的增强模型可以达到 64.0% 的 top-1 和 88.3% 的 top-10 准确率。它达到了无模板方法的最先进性能,并且与基于模板和半基于模板的方法具有竞争力。它比原版逆合成 Transformer 分别提高了 6.9% top-1 和 11.9% top-10。在反应类别未知的情况下,本文的增强模型可以达到 52.9% 的 top-1 和 76.4% 的 top-10 准确率。top-1 准确度达到了 Graph2SMILES 的最新性能。此外,Retroformerbase 在两种设置中都大大超过了香草逆合成 Transformer。它展示了深度生成模型在执行端到端逆合成预测和反应空间探索方面的巨大潜力。如下表所示:

总结
本文提出了 Retroformer,这是一种新颖的基于 Transformer 的架构,它达到了无模板逆合成的新的最先进性能。通过提出的局部注意力头和图形信息的结合,该模型能够识别局部反应区域并在检测到的反应中心有条件地生成反应物。了解反应中心还鼓励模型生成具有改进的分子有效性、反应有效性和可解释性的反应物。本文计划使用 Retroformer 作为单步逆合成预测主干,进一步研究多步无模板逆合成规划问题。
