




ICML 2022 | Structure-Aware Transformer for Graph Representation Learning
“文章信息
来源:Proceedings of the 39th International Conference on Machine Learning(ICML) 2022
”
标题:Structure-Aware Transformer for Graph Representation Learning
作者:Dexiong Chen, Leslie O’Bray, Karsten Borgwardt
链接:https://proceedings.mlr.press/v162/chen22r.html
代码:https://github.com/BorgwardtLab/SAT
内容简介
Transformer 架构最近在图表示学习中获得了越来越多的关注,因为它通过避免其严格的结构归纳偏差,而是仅通过位置编码对图结构进行编码,自然地克服了图神经网络 (GNN) 的几个限制。在这里,本文展示了由带有位置编码的 Transformer 生成的节点表示不一定能捕捉到它们之间的结构相似性。为了解决这个问题,本文提出了 Structure-Aware Transformer,这是一类简单灵活的图 Transformer,它建立在一种新的自注意力机制之上。这种新的自注意力通过在计算注意力之前提取以每个节点为根的子图表示,将结构信息合并到原始自注意力中。本文提出了几种自动生成子图表示的方法,并从理论上表明,生成的表示至少与子图表示一样具有表现力。根据经验,本文的方法在五个图形预测基准上实现了最先进的性能。本文的结构感知框架可以利用任何现有的GNN来提取子图表示,并且本文表明它相对于基本 GNN 模型系统地提高了性能,成功地结合了 GNN 和Transformer 的优势。
虽然现在已经有许多不同的消息传递策略提出,但在这类 GNN 中发现了一些关键限制。包括 GNN 的有限表达能力(Xu et al., 2019; Morris et al., 2019),以及诸如过度平滑等已知问题(Li et al., 2018; 2019; Chen et al., 2020; Oono 和 Suzuki,2020 年)和过度挤压(Alon 和 Yahav,2021 年)。过度平滑表现为所有节点表示在足够多的层之后收敛到一个常数,而过度挤压则发生在来自远距离节点的消息没有有效地通过图中的某些“瓶颈”传播时,因为太多消息被压缩成一个固定的-长度向量。因此,设计超越邻域聚合的新架构对于解决这些问题至关重要。
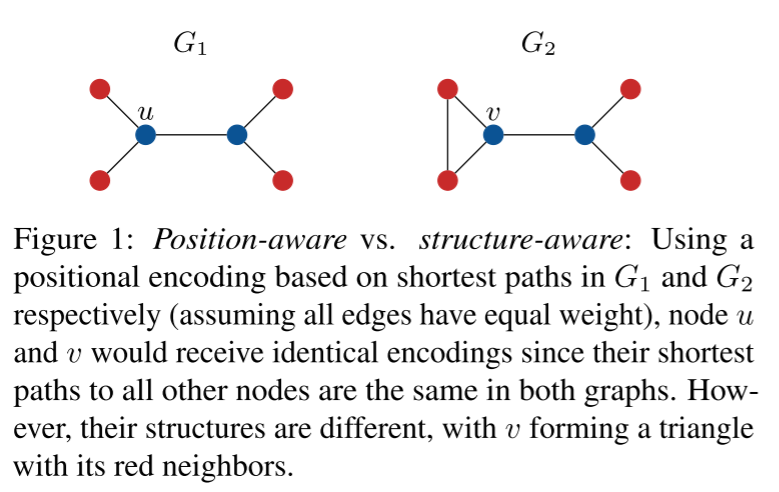
Transformers (Vaswani et al., 2017),已被证明在自然语言理解 (Vaswani et al., 2017)、计算机视觉 (Dosovitskiy et al., 2020) 和生物序列建模 (Rives et al., 2021),提供了解决这些问题的潜力。Transformer 架构不仅能够在消息传递机制中聚合局部邻域信息,还能够通过单个自注意力层捕获任何节点对之间的交互信息。此外,与 GNN 相比,Transformer 避免在中间层引入任何结构归纳偏差,解决了 GNN 的表达能力限制。相反,它只将关于节点的结构或位置信息编码到输入节点特征中,尽管它限制了它可以从图结构中学习多少信息。因此,将有关图结构的信息集成到 Transformer 架构中已经在图表示学习领域获得了越来越多的关注。然而,大多数现有方法仅编码节点之间的位置关系,而不是显式编码结构关系。因此,他们可能无法识别节点之间的结构相似性,并且可能无法对节点之间的结构交互进行建模(如下图)。这可以解释为什么它们的性能在几个任务中由稀疏 GNN 主导。
本文的主要贡献: 本文解决了如何将结构信息编码到 Transformer 架构中的关键问题。本文的引入了一种灵活的结构感知自注意机制,该机制明确考虑了图结构,从而捕获了节点之间的结构交互。生成的 Transformer类,本文称为 Structure-Aware Transformer (SAT),可以提供图的结构感知表示,与大多数现有的用于图结构化数据的位置感知 Transformer 形成对比。具体来说:
本文重新制定了自注意力机制。作为内核平滑器,并通过提取以每个节点为中心的子图表示来扩展节点特征上的原始指数内核以考虑局部结构。 本文提出了几种自动生成子图表示的方法,使生成的内核更平滑,以同时捕获节点之间的结构和属性相似性。理论上保证得到的表示至少与子图表示一样富有表现力。 本文展示了SAT模型在五个图和节点属性预测基准上的有效性,表明它比最先进的GNN 和Transformer 具有更好的性能。此外,本文展示了 SAT 如何轻松利用任何 GNN 来计算包含子图信息并优于基本 GNN 的节点表示,使其成为任何现有 GNN 的轻松增强器。 最后,本文展示了本文可以将性能提升归因于本文架构的结构感知方面,并展示了 SAT 如何比具有绝对编码的经典 Transformer 更具可解释性。
结构感知Transformer
结构感知的自注意力机制
Transformer 中的自注意力可以重写为内核平滑器,其中内核是定义在节点特征上的可训练指数内核,并且仅捕获一对节点之间的属性相似性。这个内核平滑器的问题在于,当它们具有相同或相似的节点特征时,它无法过滤掉结构上与感兴趣的节点不同的节点。为了也纳入节点之间的结构相似性,本文考虑了一个更通用的内核,该内核还考虑了每个节点周围的局部子结构。通过引入以每个节点为中心的一组子图,本文将结构感知注意力定义为:
其中 表示 中以与节点特征 相关联的节点 为中心的子图, 可以是比较一对子图的任何内核。这种新的自注意力功能不仅考虑了属性相似性,还考虑了子图之间的结构相似性。因此,它生成的节点表示比原始的 self-attention 更具表现力。此外,这种自注意力不再与节点的任何排列等价,而仅与特征和子图重合的节点等价,这是一个理想的属性。
在本文的其余部分,本文将考虑以下形式的 ,它已经包含一大类表达性和计算上易于处理的模型:
其中 是一个结构提取器,它提取一些以 为中心的具有节点特征 的子图的向量表示。本文在下面提供了结构提取器的几种替代方案。值得注意的是,本文的结构感知自注意力足够灵活,可以与任何生成子图表示的模型相结合,包括 GNN 和(可微)图内核。为了符号简单,本文假设没有边属性,但是只要结构提取器可以容纳边属性,本文的方法就可以轻松地合并边属性。因此,边属性在自注意力计算中不被考虑,而是被合并到结构感知节点表示中。在本文提出的结构提取器中,这意味着只要基本 GNN 能够处理边属性,就会包含边属性。
结构感知Transformer
定义了本文的结构感知自注意力功能后,结构感知转换器的其他组件遵循原文第 3.1 节中描述的转换器架构;有关可视化概览,请参见下图。
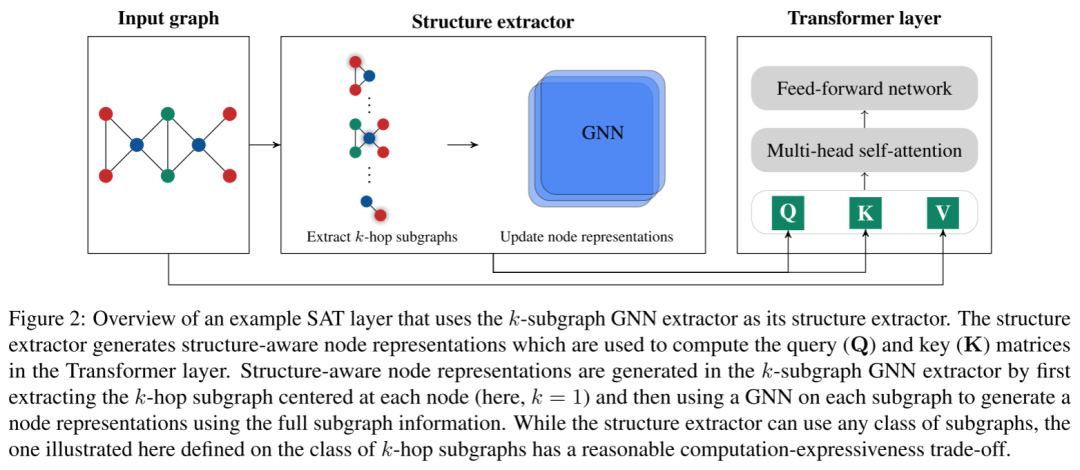
具体来说,self-attention函数后面是一个skip-connection、一个FFN和FFN前后的两个归一化层。此外,本文还在跳跃连接中包含度数因子,这被认为有助于减少高度连接的图组件的压倒性影响,即:
其中表示节点的度数。经过一个Transformer层后,本文得到一个结构相同但节点特征不同的新图,其中对应Transformer层的输出.
结合绝对编码
本文选择使用 RWPE,尽管也可以使用任何其他绝对位置表示,包括可学习的表示.本文进一步认为,仅使用 Transformer 的绝对位置编码会表现出过于宽松的结构归纳偏差,即使两个节点具有相似的局部结构,也不能保证生成相似的节点表示。这是因为距离或基于拉普拉斯算子的位置表示通常用作结构或位置签名,但不提供节点之间结构相似性的度量,尤其是在两个节点来自不同图的归纳情况下。在不使用本文的结构编码的情况下,它们的性能相对较差。相比之下,结构感知注意力中使用的子图表示可以定制以测量节点之间的结构相似性,因此如果它们具有相似的属性和周围结构,则生成相似的节点级表示。本文可以用以下定理正式说明这一点:
实验分析
本文在五个图和节点预测任务上评估 SAT 模型与几种用于图表示学习的 SOTA 方法,包括 GNN 和 Transformers,并分析本文架构的不同组件以确定驱动性能的因素。总之,本文发现了关于 SAT 的以下方面:
结构感知框架在图和节点分类任务上实现了 SOTA 性能,优于 SOTA 图 Transformer 和稀疏 GNN。 SAT 的两个实例,即k-subtree 和ksubgraph SAT,总是在它所建立的基础GNN 上进行改进,突出了本文的结构感知方法的改进表达能力。 本文表明,通过本文的结构感知注意力合并结构相对于仅使用节点属性相似性而不是合并结构相似性的 RWPE 的 vanilla Transformer 带来了显着的改进。本文还表明,较小的 k 值已经导致良好的性能,同时不会受到过度平滑或过度挤压的影响。 本文表明,选择适当的绝对位置编码和读出方法可以提高性能,但与将结构合并到方法中相比,其程度要小得多。此外,本文注意到 SAT 实现了 SOTA 性能,同时只考虑了一个小的超参数搜索空间。通过更多的超参数调整,性能可能会进一步提高。
下表总结了 SAT 相对于稀疏 GNN 的性能,它用于跨不同 GNN 提取子图表示。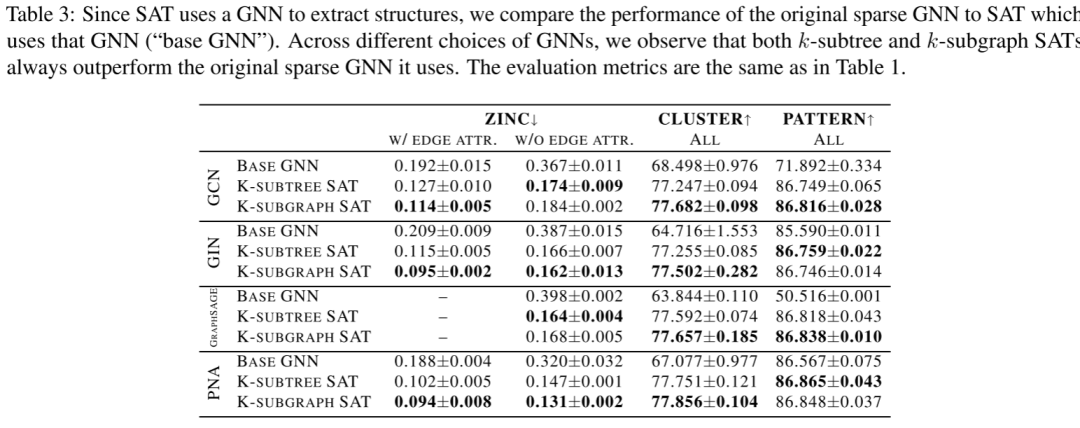 本文观察到 SAT 的两种变体始终为其基础 GNN 对应物带来巨大的性能提升,使其成为任何 GNN 模型的系统增强器。此外,作为本文考虑过的最具表现力的 GNN,PNA 在与 SAT 一起使用时始终具有最佳性能。在几乎所有情况下,k-subgraph SAT 的表现也优于或表现与 k-subtree SAT 相同,显示出其卓越的表现力。
本文观察到 SAT 的两种变体始终为其基础 GNN 对应物带来巨大的性能提升,使其成为任何 GNN 模型的系统增强器。此外,作为本文考虑过的最具表现力的 GNN,PNA 在与 SAT 一起使用时始终具有最佳性能。在几乎所有情况下,k-subgraph SAT 的表现也优于或表现与 k-subtree SAT 相同,显示出其卓越的表现力。
总结
本文引入了 SAT 模型,它成功地将结构信息整合到 Transformer 架构中,并克服了绝对编码的局限性。除了具有最小超参数调整的 SOTA 经验性能外,SAT 还提供比 Transformer 更好的可解释性。k-subgraph SAT 比 k-subtree SAT 具有更高的内存要求,如果访问高内存 GPU 受到限制,这可能会限制其适用性。本文看到 SAT 的主要限制是它具有与 Transformer 相同的缺点,即自注意力计算的二次复杂度 未来的工作因为 SAT 可以与任何 GNN 结合,本文工作的自然扩展是将 SAT 与结构提取器结合起来,这些结构提取器已被证明比 1-WL 测试更具表现力。此外,SAT 框架很灵活,可以合并任何结构提取器,产生结构感知节点表示,甚至可以扩展到使用 GNN 之外,例如可微图内核。未来工作的另一个重要领域是专注于降低自注意力计算的高内存成本和时间复杂度,正如最近开发所谓的线性变换器所做的那样,它在时间和空间上都具有线性复杂度要求。
