




ICML 2022 | G-Mixup: Graph Data Augmentation for Graph Classification
文章信息
「来源」:Proceedings of the 39th International Conference on Machine Learning(ICML) 2022
「标题」:G-Mixup: Graph Data Augmentation for Graph Classification
「作者」:Xiaotian Han, Zhimeng Jiang, Ninghao Liu, Xia Hu
「链接」:https://proceedings.mlr.press/v162/han22c.html
「代码」:https://github.com/ahxt/g-mixup
内容简介
本文研究了图形数据的 Mixup。Mixup 通过在两个随机样本之间插入特征和标签,在提高神经网络的泛化性和鲁棒性方面具有优越性。传统上,Mixup 可以处理常规的、网格状的和欧几里得数据,例如图像或表格数据。然而,直接采用 Mixup 来扩充图数据具有挑战性,因为不同的图通常:1)具有不同数量的节点;2) 不容易对齐;3)在非欧几里得空间中具有独特的类型。为此,本文提出 G-Mixup 通过插入不同类别图的生成器(即 graphon)来增强图分类。具体来说首先使用同一类中的图来估计一个graphon。不是直接操作图,而是在欧几里得空间中插值不同类别的图元以获得混合图元,其中合成图是通过基于混合图元的采样生成的。大量实验表明,G-Mixup 显著提高了 GNN 的泛化性和鲁棒性。
由于图的特性和应用 Mixup 的要求,混合图数据仍然是一个开放且具有挑战性的问题。通常,Mixup 要求原始数据实例在欧几里得空间中是规则的且对齐良好,例如图像数据和表格数据。但是,由于以下原因,图数据与它们明显不同:(i) 图数据是不规则的,因为不同图中的节点数通常彼此不同;(ii) 图数据对齐不充分,图中的节点不是自然有序的,不同图之间的节点很难匹配;(iii) 类之间的图拓扑是发散的,其中来自不同类的一对图的拓扑通常不同,而来自同一类的图通常相似。因此,直接采用 Mixup 来绘制数据并非易事。为了解决上述问题,本文提出了 G-Mixup,一种类级别的图数据增强方法,用于混合基于 graphons 的图数据。一个类中的图是在同一个生成器(即graphon)下生成的。本文混合不同类的graphons,然后生成合成图。本文还提供了graphons mixup的理论分析,保证生成的图将保留两个原始类的关键特征。本文提出的方法在下图中举例说明: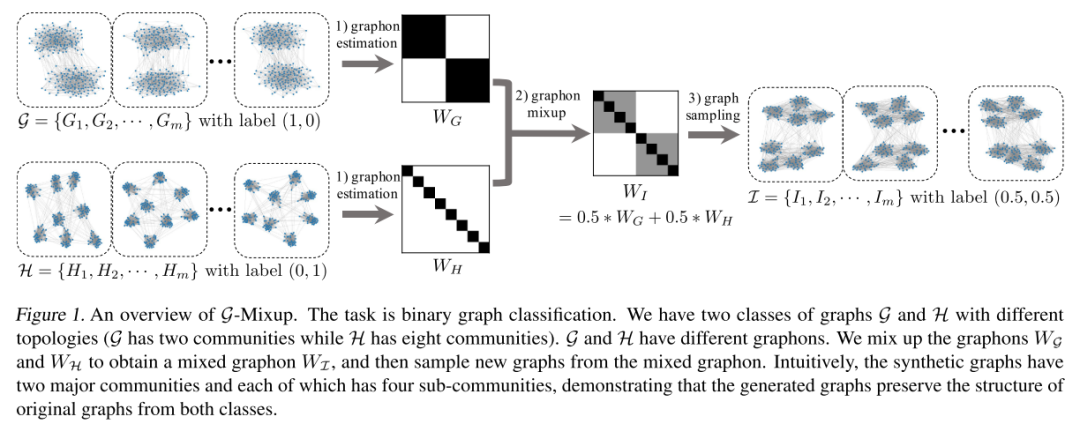 本文的主要贡献如下:
本文的主要贡献如下:
首先,本文提出了 G-Mixup 来扩充用于图分类的训练图。由于直接混合图是难以处理的,因此 G-Mixup 将不同类别的图的图元混合以生成合成图。 其次,本文从理论上证明合成图将是原始图的混合,其中源图的关键拓扑(即判别主题)将被混合。 最后,本文证明了所提出的 G-Mixup 在各种图神经网络和数据集上的有效性。大量的实验结果表明,G-Mixup 在增强图神经网络的泛化性和鲁棒性方面显著提高了其性能。
准备工作
图同态和Graphons
「图同态」:图同态是两个图之间保持邻接的映射,即把一个图中的相邻顶点映射到另一个图中的相邻顶点。从形式上讲,图同态是从到的映射,其中如果,则 .对于两个图和,它们之间可能存在多个图同态。
「Graphon」:Graphon(Airoldi et al.,2013)是一个连续的、有界的对称函数,它可以被看作是一个具有无穷多个结点的图的权矩阵。然后,给定两点表示节点 和 与边相关的概率。图的各种量可以作为图的函数计算出来。
基于图神经网络的图分类
给定一组图,图分类的目的是为每个图G分配一个类标记。近年来,图神经网络已成为最先进的图分类方法。在不损失推广性的前提下,本文给出了一个图卷积网络(GCN)的形式表达式(Kipf&Welling,2017)。第k层的前向传播描述如下:
方案介绍
G-Mixup
与图像数据在欧氏空间中的插值不同,由于图是不规则的、不对齐的、非欧氏的数据,所以对图数据的插值不是一件简单的事情。本文证明了这些挑战可以用graphon理论来解决。直观地说,一个图可以看作是一个图生成器。同一类的图可以看作是从同一个图上生成的。考虑到这一点,本文提出了G-Mixup,一种通过图形插值的类级数据增强方法。具体来说,G-Mixup将不同的图生成器插值得到一个新的混合图生成器。然后,基于混合图对合成图进行采样,进行数据扩充。从该生成器中采样的图部分具有原始图的性质。在形式上,G-Mixup被表述为:
其中,是图集G和H的图,混合图用表示,是控制不同源集贡献的权衡超参数。由生成的综合图集为。图G和图H的和分别是包含基真标号的向量,其中是类的个数。图集中综合图的标号向量记为。
如上述方程和“内容简介”中的图所示,所提出的G-Mixup包括三个关键步骤:i)为每类图估计一个图,ii)混合不同图类的图,iii)基于混合图生成合成图。
实现过程
「图估计与混合」:从观察图估计图是G-Mixup的先决条件。然而这是一个难以解决的问题,因为一个图是一个未知的函数,没有现实世界的图的封闭表达式。因此,本文使用Step函数(Lov'Asz,2012;Xu et al.,2021)来近似graphon。
「综合图生成」:图提供一个分布来生成任意大小的图。具体地说,可以按照以下过程生成k节点随机图:
「计算复杂性分析」:计算量主要来自于图的估计和合成图的生成。对于图估计,假设有m个图,每个图有n个节点,用k个分块估计阶跃函数来逼近一个图,所用的图估计方法(Xu et al.,2021)的复杂度如下表所示。对于图的生成,假设需要生成L个具有K个节点的图,节点生成的计算复杂度为,边生成的计算复杂度为,所以图生成的总体复杂度为。
实验分析
不同类别的真实世界的图有不同的图吗?
本文可视化估计的图形如下图。结果表明:在一个数据集中,不同类图的图具有明显的差异。下图中IMDB-Binaery的图显示,类1的图有更大的稠密面积,这表明该类中的图比类0的图有更大的范围。图2中的Reddit-Binary图显示,类0的图有一个高度节点,而类1的图有两个高度节点。这一观察结果验证了现实世界中不同类别的图具有明显不同的图,为通过混合图生成混合图奠定了坚实的基础。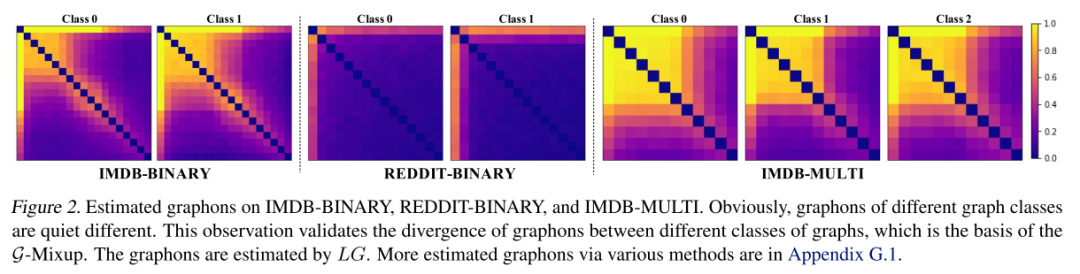
G-Mixup在做什么?
为了研究真实场景中的G-混合结果,本文在下图中的Reddit-Binary 数据集中可视化生成的合成图。观察到合成图实际上是原始图的混合。原始图和生成的合成图分别在下图(a)(b)和下图(c)(d)(e)中可视化。下图证明了混合图能够生成具有一个高阶结点和一个稠密子图的图,它可以看作是具有一个高阶结点和两个高阶结点的图的混合。验证了G-Mixup更倾向于保留原图中的判别母题。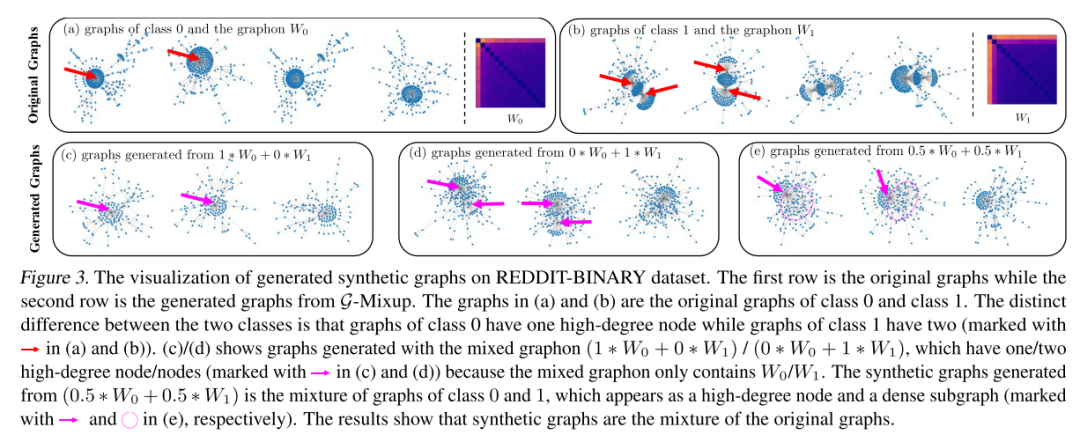
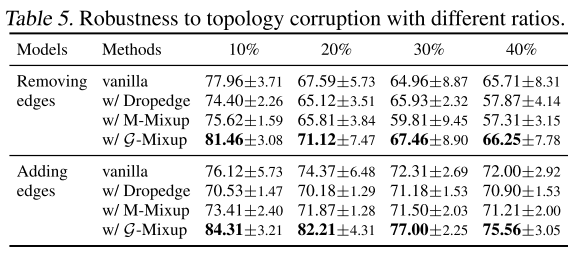
G-Mixup能提高GNNS的鲁棒性吗?
本文研究了G-Mixup的两种鲁棒性,包括标签破坏鲁棒性和拓扑破坏鲁棒性,并在下表中报告了结果,显示G-Mixup总体上获得了更好的性能,表明它比Vanilla基线对噪声标签更鲁棒。当图拓扑被破坏时,G-Mixup更健壮,因为精度始终优于基线。当图标签或拓扑是噪声的,这可能是G-混叠的一个优点。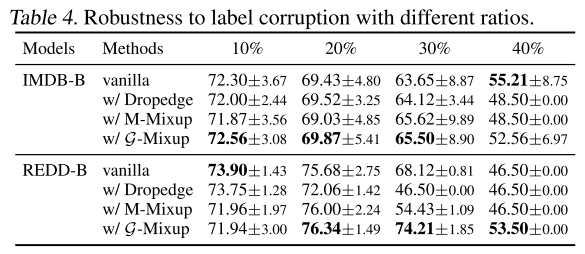
结论
本文提出了一种新的图扩充方法G-Mixup。与图像数据不同,图形数据是不规则的,不对齐的,并且处于非欧几里德空间,使得它很难被混合。然而,一个类中的图具有相同的生成元(即图元),该生成元是正则的、良好对齐的并且在欧几里得空间中。因此,本文转向将不同类别的图混合起来生成合成图。G-Mixup是对不同类图的拓扑进行混合和插值。综合实验表明,用G-Mixup训练的GNNs具有更好的性能和泛化能力,提高了模型对噪声标签和破坏拓扑的鲁棒性
