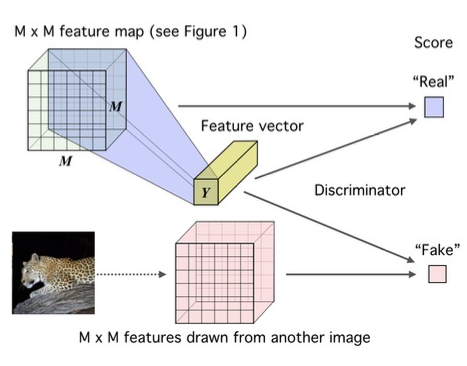
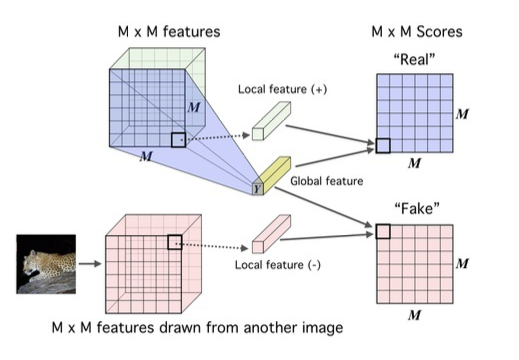
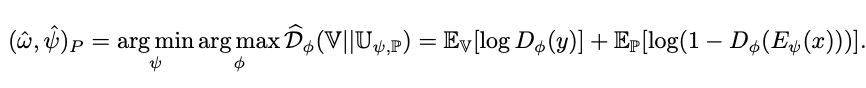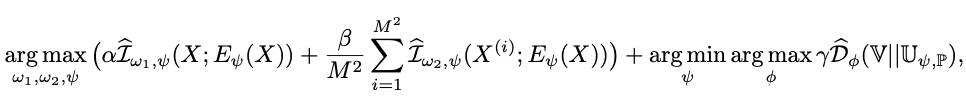One Sentence Summary:给现有的样本加上噪声,作为负样本,模型对原本真实的样本和新增的负样本进行区分,从而将 softmax 这种低效的计算转化成二分类的 logloss,计算效率更高,下面公式里的x_t代表真实的样本,y_t代表加了 noise 后的样本。但是这里会出现一个问题,如果我们的 noise 分布选的不好,效果可能并不一定会好,所以在这篇 paper 里作者也提到了在增加 noise 的时候,尽量和现有的数据分布相似,这样能最大程度上提高训练的效果Intuitively, the noise distribution should be close to the data distribution, because otherwise, the classification problem might be too easy and would not require the system to learn much about the structure of the data. As a consequence, one could choose a noise distribution by first estimating a preliminary model of the data, and then use this preliminary model as the noise distribution.这个方法在推荐里的应用,个人观点是可以在召回里来尝试,毕竟现在的召回面临着很大的 selection bias 问题(有朋友在召回里尝试过,效果一般,只能说明老 paper 时间比较久了,已经被现在的 SOTA beat 掉了,不过这篇文章的 idea 很有意思,数学证明也很不错,可以学习下)。
4.2 Representation Learning with Contrastive Predictive Coding (InfoNCE)
在做 data augumentation,模型见到了更多的样本,记忆的东西更全,效果好也是预期之中的。
去噪
参考文献[1] Gutmann M, Hyvärinen A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010: 297-304.[2] Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv preprint arXiv:1807.03748, 2018.[3] Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018.[4] Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018.[5] GitHub - asheeshcric/awesome-contrastive-self-supervised-learning: A comprehensive list of awesome contrastive self-supervised learning papers.https://github.com/asheeshcric/awesome-contrastive-self-supervised-learning[6] 张俊林:对比学习(Contrastive Learning):研究进展精要:https://zhuanlan.zhihu.com/p/367290573





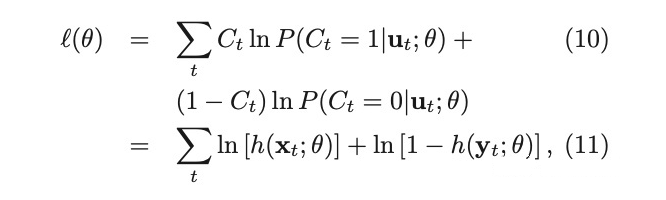
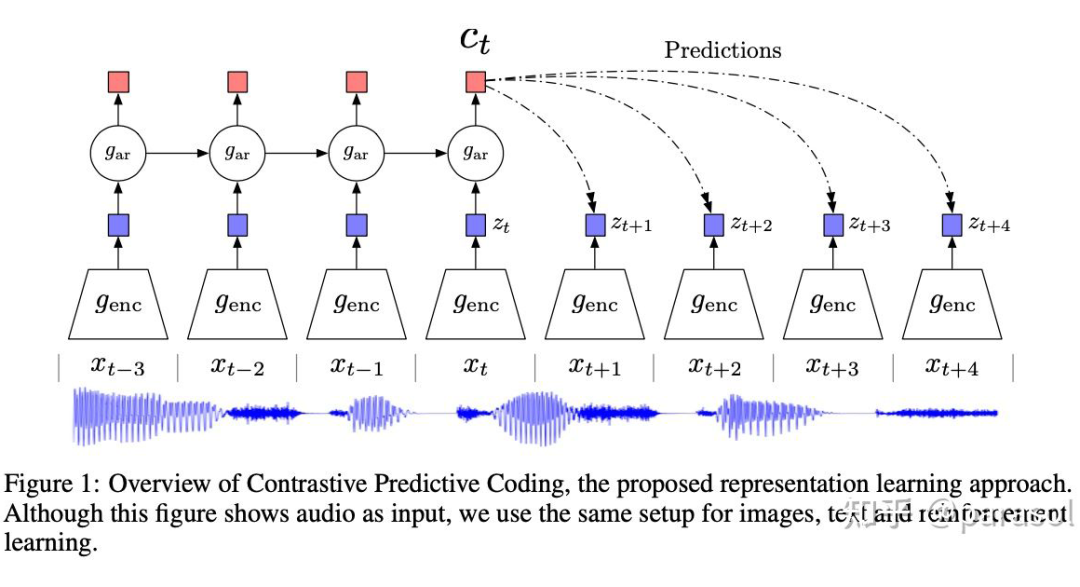
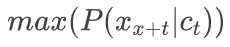
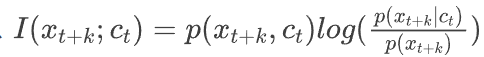
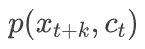
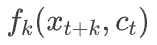
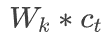
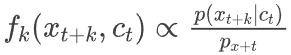
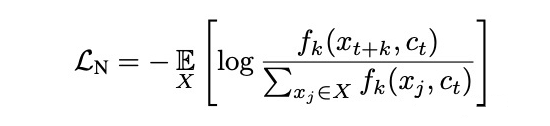
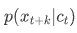 转变成了分类模型
转变成了分类模型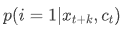 。
。