




原文:Why and When to Avoid S3 as a Data Platform for Data Lakes
如今,数据湖在大型企业中风靡一时。数据湖是单个存储,用于存储源系统数据的原始副本和转换后的数据,以用于报告,可视化,高级分析和机器学习等任务。
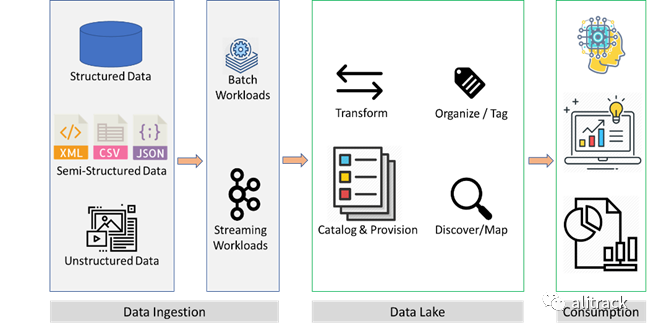
对象存储(如 S3)正成为数据湖的首选平台,原因有两个:
在云上提供廉价,持久且几乎无限的存储 实现了计算和存储的分离,从而可以独立扩展任何一个
本文,我将更深入地探讨对象存储的一些优点,这些对象存储是作为数据湖平台而流行的。我还将研究一些经常被低估的难题,这些难题困扰着许多数据湖用例中对象存储的使用。
对象存储的好处:持久,便宜且几乎不受限制的存储
像 S3 这样的对象存储提供了 11 个 9 的持久性(99.999999999%)和四个 9 的可用性(99.99%),它们设法以几乎无限的规模做到了这一点,其价格低得令人难以置信,约为 23 美元/ TB 月。与此形成鲜明对比的是,几年前流行的本地数据仓库设备(DWA)。不包括企业支持,DWA 的成本[1]为每 TB 数万美元。仅支持数百 TB 的数百万美元的 DWA 合同是很常见的。
当 IT 领导者考虑为其数据湖选择数据平台时,对象存储的$23/TB/月的价格标签实在令人难以抗拒。使用最便宜的存储空间来处理预期将要容纳的数据湖的大量数据(从数百 TB 到 PB)是有意义的。像 S3 这样的对象存储似乎(不正确,我们将在本文后面看到)代表着许多大型企业仍在使用的 DWA 的一千倍的价格优势。
对象存储的好处:存储和计算的分离
数据湖所需的存储规模使使用 DWA 之类的体系结构将存储和计算耦合在一个单独的程序包中,这使它的成本过高。通过解耦存储和计算,我们可以在任何给定时间携带适当数量的按需计算,以承载需要分析的数据。这显着降低了数据分析解决方案的总体成本。
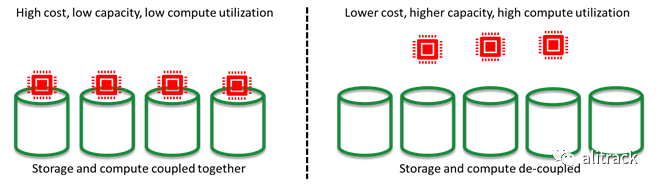
可以理解,所有这些优势对于推动 S3 和其他对象存储作为数据湖的平台的普及至关重要。但是对象存储面临很多挑战,没有引起足够的重视。对于源自 RDBMS 且经常刷新(每天/每小时)的数据尤其如此,后者构成了企业中大量的高质量数据。
对象存储的缺点:不变性
所有对象存储,包括 S3,GCS 和 Azure Blob 存储,都是不可变的。这意味着,一旦将文件写入对象存储,就永远无法对其进行编辑。用户只能硬删除旧文件并创建一个新文件,或者在逻辑上删除该旧文件并创建一个新文件(版本控制)。
当使用 S3 作为源于 RDBMS 且经常刷新的数据的数据平台时,这将导致为每个表创建大量的小文件。
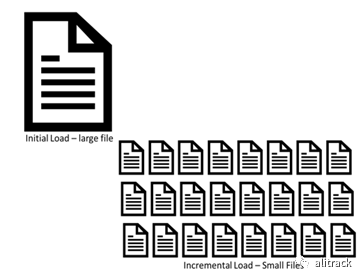
随着插入,更新和删除随着时间的推移而堆积,尝试导出表的当前状态变得成倍地增加了时间和计算量。大多数数据科学家都对这项复杂的工作不屑一顾,而是要求直接访问源系统,从而一开始就破坏了使用数据湖的目的。
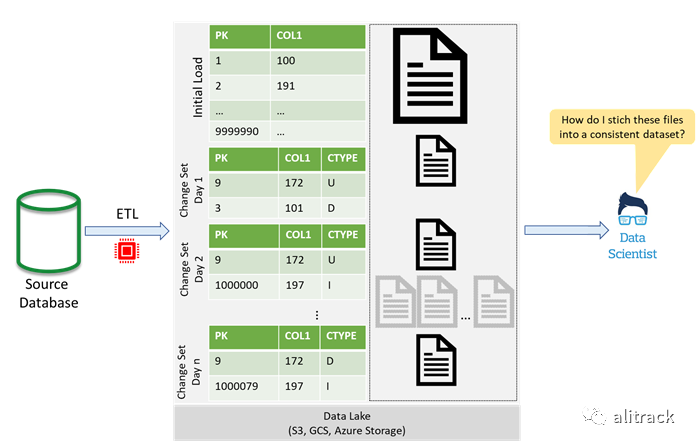
U=更新,I=插入,D=删除
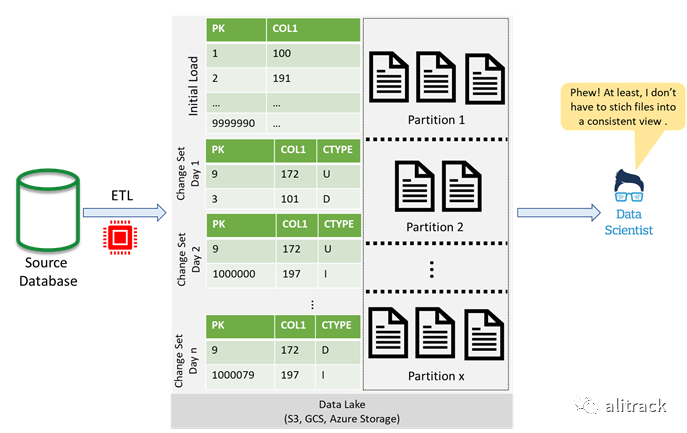
解决方案,第 1 部分:对数据进行分区
解除最终用户合并变更责任的一种解决方案是对数据进行分区,然后重新写入最新插入,更新和删除所针对的分区。这在一定程度上减轻了最终用户的负担。但是,仍然存在性能问题,尤其是在表中有大量列且仅需要这些列中的一个子集进行分析的情况下。
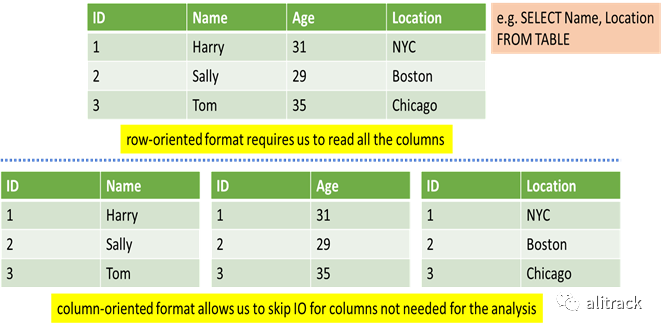
解决方案,第 2 部分:使用列式存储
通过使用诸如Apache Parquet[2]或Apache ORC[3]之类的列格式,可以改进上述解决方案。列格式通过更好地压缩数据并将 I/O 限制为仅用于分析所需的列,从而显着提高了性能。但是,从语言和工具(如 Python,R 或 Tableau)的角度,读取 Parquet 文件仍然很困难。
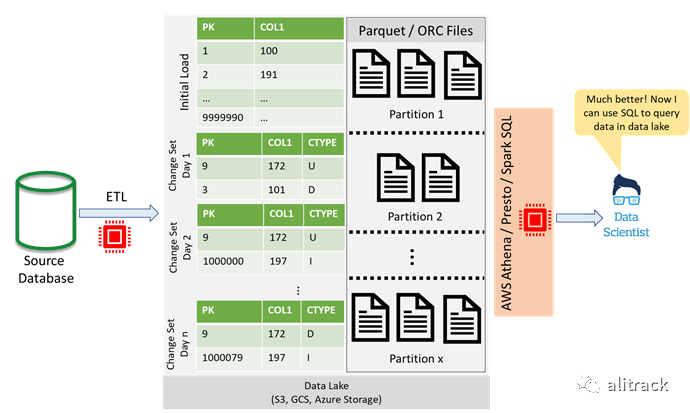
解决方案,第 3 部分:使用 SQL 接口简化访问
为了进一步构建此解决方案,许多工程师在原始 Parquet 文件上添加了 SQL 接口(例如AWS Athena[4],Presto[5]或Spark SQL[6])。这使得最终用户的数据访问更加简化,他们现在可以通过自己喜欢的编程语言和工具(例如 Python,R 或 Tableau)发出 SQL 查询。
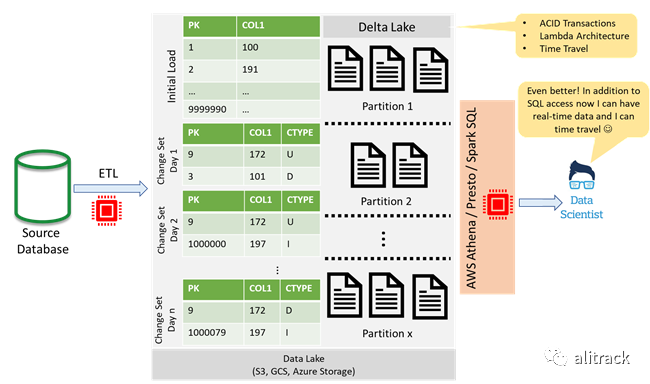
解决方案,第 4 部分:使用 Delta Lake 添加功能
通过使用像Delta Lake[7]这样的开源存储层,可以再次改进上述解决方案。Delta Lake 通过增加对 ACID(原子性,一致性,隔离性,持久性)交易的支持,支持流和批处理用例的 lambda 体系结构以及访问先前刷新日期/之前的数据的能力,进一步改进了 Parquet 格式。时间(时间旅行)。
问题解决了?
没那么快!上面的体系结构确实代表了可行的解决方案,并且许多企业为能够设计和实施这种解决方案而自以为是。公平地说,能够大规模实现这一目标是一项相当大的成就。但是,该体系结构仍然困扰着许多问题,并且还有很多改进的余地。作为数据湖平台的 S3 上的 Delta Lake 的关键问题包括:
该体系结构无法解决变更集的创建问题,因此创建变更集可能会遇到很大的挑战 实施和支持企业级的弹性提取,转换和加载(ETL)解决方案非常复杂 编写 Parquet 和 Delta 文件需要额外的计算以及技术知识,才能大规模配置和运行集群计算平台(例如 Apache Spark) SQL 接口访问(通过AWS Athena[8],Presto[9]或Spark SQL 等技术[10])需要附加的计算基础架构,从而增加了解决方案的整体复杂性和成本 解决方案的复杂性使其支持成本高昂 S3 提供有限的元数据和标记功能 在 S3 中的对象上集成表级或行级安全性,尤其是对于大型和复杂的企业而言,可能会非常具有挑战性 最后但并非最不重要的一点是,这种平台的性能远远落后于它打算取代的数据仓库设备的性能
考虑隐藏的计算和支持成本,安全集成和性能问题,S3 作为 RDBMS 来源,频繁刷新的数据的数据平台,使它与承诺的$23/TB/月相去甚远。一旦我们将所有成本加起来,它便开始攀升至每月每 TB 数千美元的范围。对于这样的价格,有很多更好的选择。
诸如Snowflake[11],Google BigQuery[12]或Azure Synapse Analytics[13]之类的云级托管分析数据库提供了两全其美的优势。通过将存储和计算分开,它们提供了 S3 可比的存储成本以及可管理的数据平台,该平台抽象了实现云规模分析解决方案的复杂性。它们具有 AWS Athena Presto Spark SQL 界面,提供了与基于 S3 的 Parquet/ORC/Delta Lake 相似的 TCO,同时拥有更好的性能,安全性集成和架构支持。它们还减少了运营开销,同时将技术和人才风险转移给了第三方供应商。
源自 RDBMS 的大部分为静态数据呢?
基于 RDBMS 的,大多数为静态数据(即,数周或数月不变)不会像基于 RDBMS 的,经常刷新的数据那样产生大量的 ETL 计算和支持开销。但是,对于此类用例,我的建议是首选基于云的托管分析数据库,而不是基于 S3 的 Parquet/ORC/Delta Lake 存储,因为围绕元数据管理,安全集成和性能的所有挑战和成本仍然存在。
那半结构化数据呢?
进入企业的大多数半结构化数据(通过 XML,JSON 和 CSV 等格式)都具有相当稳定的架构,可以将其提取到关系表中。大型企业中的大多数此类数据经常被吸收到AWS Redshift 之[14]类的分析数据库中,或者通过基于 S3 的 Parquet/ORC/Delta Lake 存储通过 SQL 接口(如 AWS Athena,Presto 或 Spark SQL)访问。对于这种类型的用例,我的建议是考虑将存储和计算分开的托管分析数据库。
TCO 应该是您的北极星
最后,应根据总体拥有成本(TCO)来考虑解决方案,同时要考虑它们带来的功能和解决方案固有的风险。如果两种解决方案的总拥有成本相似,但是其中一种提供了更好的功能,那么与该解决方案保持一致就很容易了。此外,应仔细考虑与内部开发的解决方案相关的技术和人才风险。通常,对于大型企业,在合理的情况下,将技术和人才风险转移给信誉良好的供应商产品更有意义。
那什么时候对象存储可用于数据湖?
对于其他用例,例如半结构化和非结构化数据,由于(出于成本或实用性的原因)不能或不应该将其吸收到云规模的分析数据库中,对象存储(如 S3)仍然是一个极好的数据平台。例如,将图像,音频文件,视频,电子邮件,PowerPoint 演示文稿,Word 文档或 PDF 提取到托管分析数据库中是没有意义的。此外,这些云规模的分布式数据库中的许多数据库都使用对象存储(如 S3)作为它们的数据摄取接口,有些甚至使用对象存储作为后台内部管理的存储平台。
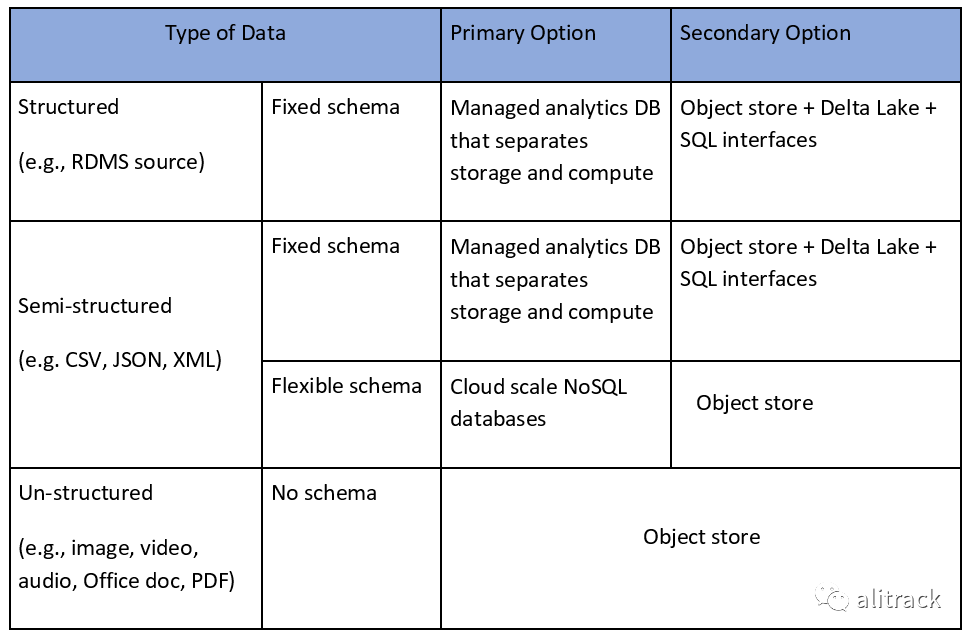
| 数据类型 | 例子 | 表结构 | 首先方案 | 备选方案 |
|---|---|---|---|---|
| 结构化数据 | RDBMS | 固定 | 计算存储分离的可维护分析数据库 | 对象存储+Delta+SQL 接口 |
| 半结构化数据 | CSV,JSON,XML | 固定 | 计算存储分离的可维护分析数据库 | 对象存储+Delta+SQL 接口 |
| 半结构化数据 | CSV,JSON,XML | 弹性 | 云弹性 NoSQL Databases | 对象存储 |
| 非结构化数据 | image,video,audio,Office Doc,PDF | 无 | 对象存储 | 对象存储 |
参考资料
DWA 的成本: https://shefsite.wordpress.com/2015/03/11/how-much-does-a-teradata-data-warehouse-appliance-cost/
[2]Apache Parquet: https://parquet.apache.org/
[3]Apache ORC: https://orc.apache.org/
[4]AWS Athena: https://aws.amazon.com/athena/
[5]Presto: https://prestodb.io/
[6]Spark SQL: https://spark.apache.org/sql/
[7]Delta Lake: https://delta.io/
[8]AWS Athena: https://aws.amazon.com/athena/
[9]Presto: https://prestodb.io/
[10]Spark SQL 等技术: https://spark.apache.org/sql/
[11]Snowflake: https://www.snowflake.com/
[12]Google BigQuery: https://cloud.google.com/bigquery
[13]Azure Synapse Analytics: https://azure.microsoft.com/en-us/services/synapse-analytics/
[14]AWS Redshift 之: https://aws.amazon.com/redshift/
欢迎关注公众号

有兴趣加群讨论数据挖掘和分析的朋友可以加我微信(witwall),暗号:入群

也欢迎投稿!
