






随着X86服务器的普及,目前各种主流数据库、中间件、容器等都在逐步迁往Linux平台,那对于应用开发人员还有系统运维人员掌握Linux相关技术将显得尤为重要。
大家都知道服务器硬件简单理解就是Cpu+内存+硬盘(存储)这些,那Linux就是负责调度这些硬件的软件,让大家一起和谐工作产生GDP。由此我们可以发现Linux主要就是管Cpu、内存、硬盘这3类的工作,那换一个角度也就是说Linux运行异常也大概率就这3类问题。
三板斧之--CPU
一说cpu,熟悉linux的都知道vmstat、top之类的命令,这里我们找个案例来解读一下:
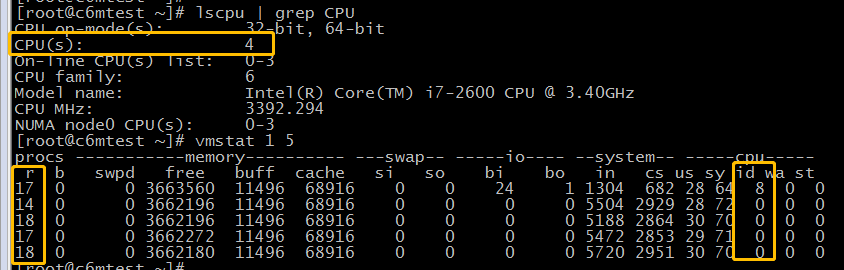
图中可以看到这是一台4cpu的服务器,目前procs-r17,18左右,cpuid空闲为0,由于这是一台4cpu的服务器,理论上在某一时刻CPU的并行处理能力上限将是4,那procs-r远远大于cpu核心数意味着CPU忙不过来了,拼了命淦但还是有一堆任务等着它淦(来者不拒),所以后面的cpuidle是0,那这就是一个高并发场景的cpu过载的特征。
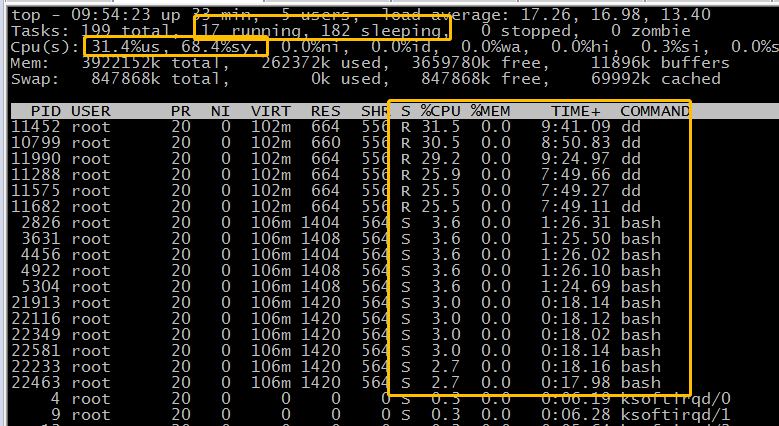
通过top命令同样可以看到目前有17个进程处于running状态,31.4%us:用户状态的调用,68.4%sy:涉及到系统内核的调用.在进程模块中可以看到大量的dd进程以及外层的bash(测试启动的ddif=/dev/zeroof=/dev/null命令)。当发现服务器cpu过载时便可以通过这个思路来排查是否存在异常高消耗进程。
注意对于多线程的程序比如java,%CPU字段很可能出现1100%这种情况,简单理解就是多个线程在cpu上运行,相当于消耗了11颗cpu的运算量。
Procs
r: The number of processes waiting for run time.
三板斧之--内存
再来说说内存,由于内存容量存在上限,比如服务器物理内存128G,当我们进行一个500G数据运算时,内存是明显放不下的,这时候Linux就引入了一个叫swap的东西,相当于一个临时空间,它基于磁盘,当内存不够时,将部分当前不使用的数据转储到swap空间中,这样就可以最大化的利用有限的内存进行计算。
这个设计理念是好的,但实际生产环境中往往引发各种惨痛的案例,如下:
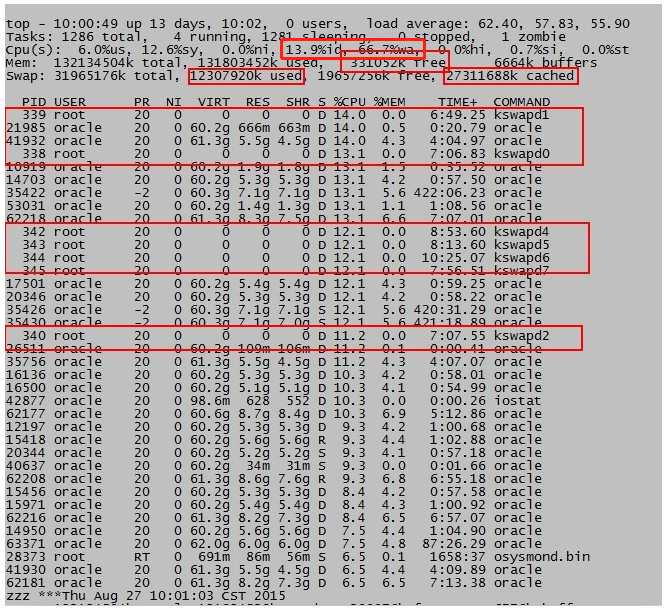
可以看到图中的服务器总共配置了32Gswap空间,当前已经使用了12G说明已经有数据被从内存中swapout到临时空间,top进程也同样出现kswapd[0-9],这些进程就是专门负责swapin,swap out,Top中看到这类进程时需额外注意。
这时cpu6.%us,12.6%sy,13.9%id,66.7%wa,这个wa说明存在磁盘IO等待,那简单理解就是由于swap空间的硬盘性能不足,内存中的数据swapout速度过慢,引发系统层的panic,服务器hang,造成业务中断故障。实际在这个案例过程中vmstat命令输出也可以发现cpu–b/si so这些指标的异常。

总结一下swap,一般在服务器系统安装时系统管理员便会用本地盘划分swap分区,这里本地盘的性能比较容易出现瓶颈,大量的swap易引发系统panic,另外一个Linux使用vm.swappiness参数来控制使用物理内存还是使用交换空间的权重,在老旧一些的版本中设置为0容易引发系统bug推荐设置为1,在较新的版本中比如redhat7/8则推荐设置为0来避免使用交换空间,那在一些数据库一体机等专有服务器上物理内存都能达到TB级,这种也可以直接关闭swap功能。
参考Man :
Man vmstat
Procs
r: The number of processes waiting for run time.
man top
2c. SUMMARY Area Fields
us = user mode
sy = system mode
ni = low priority user mode (nice)
id = idle task
wa = I/O waiting
man vmstat ,
Swap
si: Amount of memory swapped in from disk (/s).
三板斧之--磁盘
最后我们在来说说磁盘类的问题,目前主流方法都是基于磁盘响应时间作为判断依据(iostat命令输出的await值),这里不区分读写,比如SSD存储响应时间都在5ms以内,高端SSD的响应时间甚至达到1ms以内,而传统的机械硬盘响应时间则较慢一些,高端类的存储阵列也在20ms以内,差一点的40ms,50ms也比较常见。
了解了这些当我们通过iostat命令来核查服务器磁盘响应情况时便能够直观的发现是否存在问题。如图:
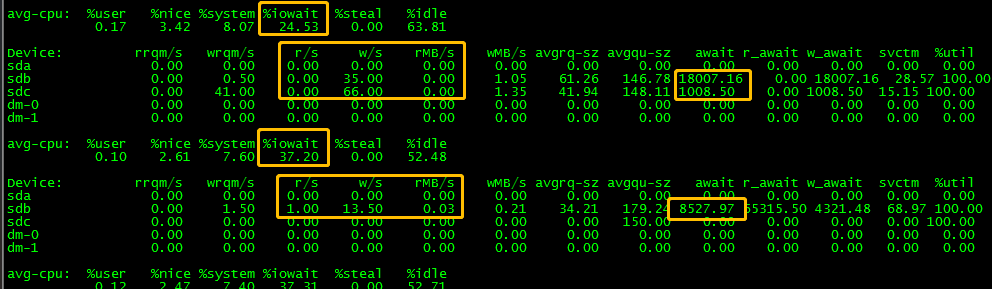
可以看到%iowait已经超过了%user,%system,IO方面压力较大,再往下可以看到sdb/sdc读写都非常少而await(响应时间单位ms)值却异常的大,IO几乎无法完成,推测存储出现异常,通知系统管理员核验确认RAID出现降级故障.这里需要额外注意iostat输出的sdb/sdc的%util值为100%,这个%util100实际没有参考意义,因为系统也并不知道后端存储的iops能力以及使用率,只有await才能判断磁盘IO响应是否正常.如图:
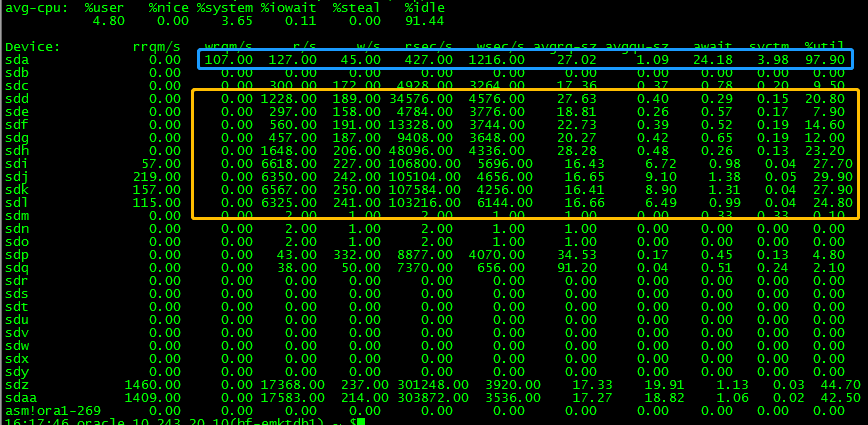
这是一台本地机械盘(sda),在少量的读写情况下%util已经97.9,但响应时间24.18任然在正常范围内,不能根据util%值来判断sda是否存在问题。而下面的sdb/sdc等等磁盘都是外挂SSD存储,可以看到iops近万的情况下较慢的盘await也才1点几ms,快的盘都不到1ms。
await
通过以上三板斧,我们便可以对当前Linux系统的运行情况做到心中有数,在此基础上实际运用过程中,比如swap引起的案例中,vmstatcpu-b/si so以及iostat的swap空间挂载盘一定会有所表现,不能教条的认为一定是这一方面的问题,所以需要结合起来分析。
文章首发于2021年02月25日

本文作者:胡 杰(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

